 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Leakage of Sentence Embeddings via Generative Embedding Inversion Attacks
Paper and Code
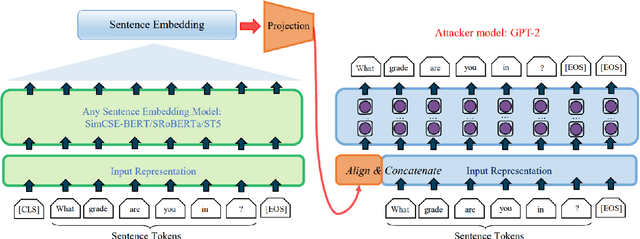

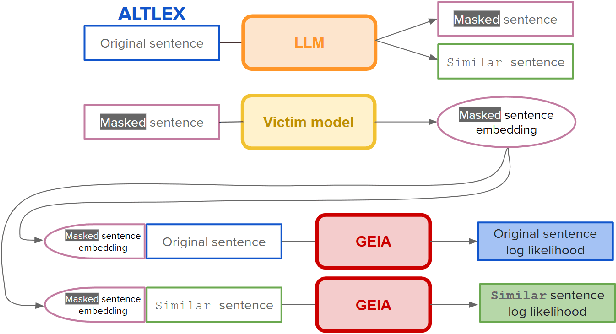
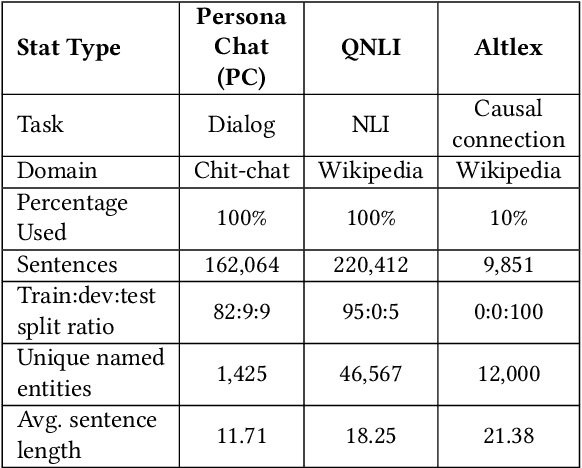
Text data are often encoded as dense vectors, known as embeddings, which capture semantic, syntactic, contextual, and domain-specific information. These embeddings, widely adopted in various applications, inherently contain rich information that may be susceptible to leakage under certain attacks. The GEIA framework highlights vulnerabilities in sentence embeddings, demonstrating that they can reveal the original sentences they represent. In this study, we reproduce GEIA's findings across various neural sentence embedding models. Additionally, we contribute new analysis to examine whether these models leak sensitive information from their training datasets. We propose a simple yet effective method without any modification to the attacker's architecture proposed in GEIA. The key idea is to examine differences between log-likelihood for masked and original variants of data that sentence embedding models have been pre-trained on, calculated on the embedding space of the attacker. Our findings indicate that following our approach, an adversary party can recover meaningful sensitive information related to the pre-training knowledge of the popular models used for creating sentence embeddings, seriously undermining their security. Our code is available on: https://github.com/taslanidis/GEIA