 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Case or Not to Case: An Empirical Study in Learned Sparse Retrieval
Jan 24, 2026Learned Sparse Retrieval (LSR) methods construct sparse lexical representations of queries and documents that can be efficiently searched using inverted indexes. Existing LSR approaches have relied almost exclusively on uncased backbone models, whose vocabularies exclude case-sensitive distinctions, thereby reducing vocabulary mismatch. However, the most recent state-of-the-art language models are only available in cased versions. Despite this shift, the impact of backbone model casing on LSR has not been studied, potentially posing a risk to the viability of the method going forward. To fill this gap, we systematically evaluate paired cased and uncased versions of the same backbone models across multiple datasets to assess their suitability for LSR. Our findings show that LSR models with cased backbone models by default perform substantially worse than their uncased counterparts; however, this gap can be eliminated by pre-processing the text to lowercase. Moreover, our token-level analysis reveals that, under lowercasing, cased models almost entirely suppress cased vocabulary items and behave effectively as uncased models, explaining their restored performance. This result broadens the applicability of recent cased models to the LSR setting and facilitates the integration of stronger backbone architectures into sparse retrieval. The complete code and implementation for this project are available at: https://github.com/lionisakis/Uncased-vs-cased-models-in-LSR
Pipeline Inspection, Visualization, and Interoperability in PyTerrier
Jan 24, 2026PyTerrier provides a declarative framework for building and experimenting with Information Retrieval (IR) pipelines. In this demonstration, we highlight several recent pipeline operations that improve their ability to be programmatically inspected, visualized, and integrated with other tools (via the Model Context Protocol, MCP). These capabilities aim to make it easier for researchers, students, and AI agents to understand and use a wide array of IR pipelines.
Information Leakage of Sentence Embeddings via Generative Embedding Inversion Attacks
Apr 23, 2025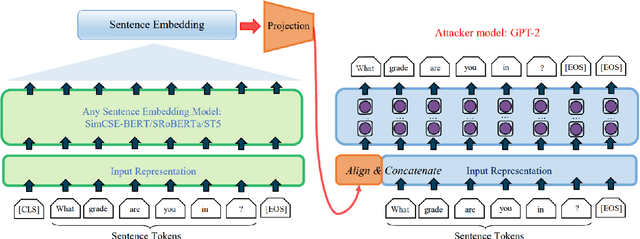

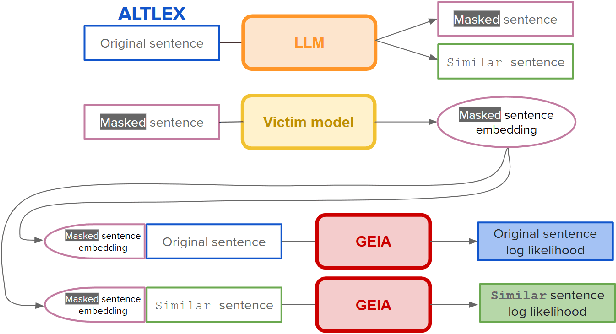
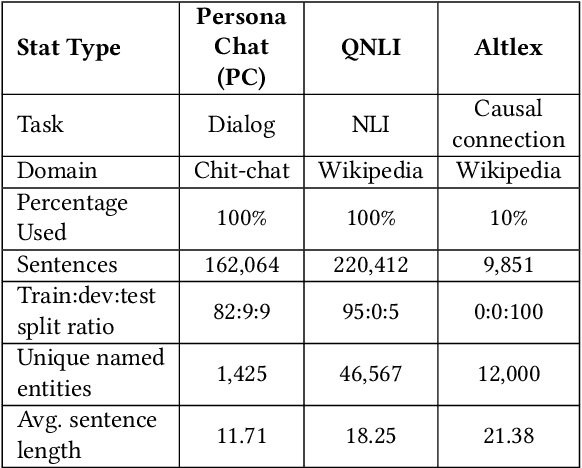
Text data are often encoded as dense vectors, known as embeddings, which capture semantic, syntactic, contextual, and domain-specific information. These embeddings, widely adopted in various applications, inherently contain rich information that may be susceptible to leakage under certain attacks. The GEIA framework highlights vulnerabilities in sentence embeddings, demonstrating that they can reveal the original sentences they represent. In this study, we reproduce GEIA's findings across various neural sentence embedding models. Additionally, we contribute new analysis to examine whether these models leak sensitive information from their training datasets. We propose a simple yet effective method without any modification to the attacker's architecture proposed in GEIA. The key idea is to examine differences between log-likelihood for masked and original variants of data that sentence embedding models have been pre-trained on, calculated on the embedding space of the attacker. Our findings indicate that following our approach, an adversary party can recover meaningful sensitive information related to the pre-training knowledge of the popular models used for creating sentence embeddings, seriously undermining their security. Our code is available on: https://github.com/taslanidis/GEIA
On the Reproducibility of Learned Sparse Retrieval Adaptations for Long Documents
Mar 31, 2025Document retrieval is one of the most challenging tasks in Information Retrieval. It requires handling longer contexts, often resulting in higher query latency and increased computational overhead. Recently, Learned Sparse Retrieval (LSR) has emerged as a promising approach to address these challenges. Some have proposed adapting the LSR approach to longer documents by aggregating segmented document using different post-hoc methods, including n-grams and proximity scores, adjusting representations, and learning to ensemble all signals. In this study, we aim to reproduce and examine the mechanisms of adapting LSR for long documents. Our reproducibility experiments confirmed the importance of specific segments, with the first segment consistently dominating document retrieval performance. Furthermore, We re-evaluate recently proposed methods -- ExactSDM and SoftSDM -- across varying document lengths, from short (up to 2 segments) to longer (3+ segments). We also designed multiple analyses to probe the reproduced methods and shed light on the impact of global information on adapting LSR to longer contexts. The complete code and implementation for this project is available at: https://github.com/lionisakis/Reproducibilitiy-lsr-long.
* This is a preprint of our paper accepted at ECIR 2025