 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Language Models for Crosslingual Knowledge Consistency
Mar 04, 2026Large language models are known to often exhibit inconsistent knowledge. This is particularly problematic in multilingual scenarios, where models are likely to be asked similar questions in different languages, and inconsistent responses can undermine their reliability. In this work, we show that this issue can be mitigated using reinforcement learning with a structured reward function, which leads to an optimal policy with consistent crosslingual responses. We introduce Direct Consistency Optimization (DCO), a DPO-inspired method that requires no explicit reward model and is derived directly from the LLM itself. Comprehensive experiments show that DCO significantly improves crosslingual consistency across diverse LLMs and outperforms existing methods when training with samples of multiple languages, while complementing DPO when gold labels are available. Extra experiments demonstrate the effectiveness of DCO in bilingual settings, significant out-of-domain generalizability, and controllable alignment via direction hyperparameters. Taken together, these results establish DCO as a robust and efficient solution for improving knowledge consistency across languages in multilingual LLMs. All code, training scripts, and evaluation benchmarks are released at https://github.com/Betswish/ConsistencyRL.
When Models Reason in Your Language: Controlling Thinking Trace Language Comes at the Cost of Accuracy
May 28, 2025Recent Large Reasoning Models (LRMs) with thinking traces have shown strong performance on English reasoning tasks. However, their ability to think in other languages is less studied. This capability is as important as answer accuracy for real world applications because users may find the reasoning trace useful for oversight only when it is expressed in their own language. We comprehensively evaluate two leading families of LRMs on our XReasoning benchmark and find that even the most advanced models often revert to English or produce fragmented reasoning in other languages, revealing a substantial gap in multilingual reasoning. Prompt based interventions that force models to reason in the users language improve readability and oversight but reduce answer accuracy, exposing an important trade off. We further show that targeted post training on just 100 examples mitigates this mismatch, though some accuracy loss remains. Our results highlight the limited multilingual reasoning capabilities of current LRMs and outline directions for future work. Code and data are available at https://github.com/Betswish/mCoT-XReasoning.
On the Consistency of Multilingual Context Utilization in Retrieval-Augmented Generation
Apr 01, 2025

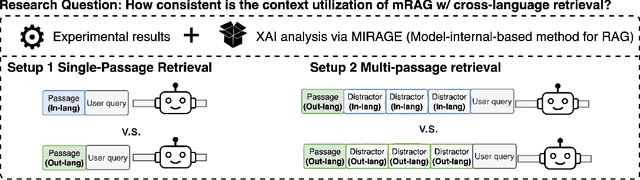
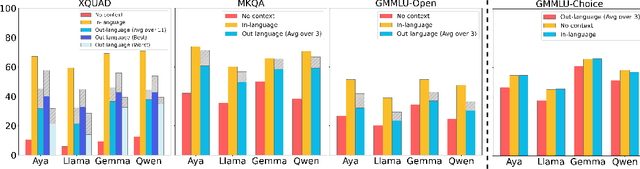
Retrieval-augmented generation (RAG) with large language models (LLMs) has demonstrated strong performance in multilingual question-answering (QA) tasks by leveraging relevant passages retrieved from corpora. In multilingual RAG (mRAG), the retrieved passages can be written in languages other than that of the query entered by the user, making it challenging for LLMs to effectively utilize the provided information. Recent research suggests that retrieving passages from multilingual corpora can improve RAG performance, particularly for low-resource languages. However, the extent to which LLMs can leverage different kinds of multilingual contexts to generate accurate answers, *independently from retrieval quality*, remains understudied. In this paper, we conduct an extensive assessment of LLMs' ability to (i) make consistent use of a relevant passage regardless of its language, (ii) respond in the expected language, and (iii) focus on the relevant passage even when multiple `distracting' passages in different languages are provided in the context. Our experiments with four LLMs across three QA datasets covering a total of 48 languages reveal a surprising ability of LLMs to extract the relevant information from out-language passages, but a much weaker ability to formulate a full answer in the correct language. Our analysis, based on both accuracy and feature attribution techniques, further shows that distracting passages negatively impact answer quality regardless of their language. However, distractors in the query language exert a slightly stronger influence. Taken together, our findings deepen the understanding of how LLMs utilize context in mRAG systems, providing directions for future improvements.
Likelihood as a Performance Gauge for Retrieval-Augmented Generation
Nov 12, 2024Recent work finds that retrieval-augmented generation with large language models is prone to be influenced by the order of retrieved documents in the context. However, the lack of in-depth analysis limits the use of this phenomenon for prompt engineering in practice. In this study, we posit that likelihoods serve as an effective gauge for language model performance. Through experiments on two question-answering datasets with a variety of state-of-the-art language models, we reveal correlations between answer accuracy and the likelihood of the question at both the corpus level and the instance level. In addition, we find that question likelihood can also indicate the position of the task-relevant information in the context. Based on these findings, we propose two methods that use question likelihood as a gauge for selecting and constructing prompts that lead to better performance. We demonstrate their effectiveness with experiments. In addition, our likelihood-based methods are efficient, as they only need to compute the likelihood of the input, requiring much fewer language model passes than heuristic prompt engineering methods that require generating responses. Our analysis deepens our understanding of how input prompts affect model performance and provides a promising direction for efficient prompt optimization.
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models
Jun 28, 2024



Following multiple instructions is a crucial ability for large language models (LLMs). Evaluating this ability comes with significant challenges: (i) limited coherence between multiple instructions, (ii) positional bias where the order of instructions affects model performance, and (iii) a lack of objectively verifiable tasks. To address these issues, we introduce a benchmark designed to evaluate models' abilities to follow multiple instructions through sequential instruction following (SIFo) tasks. In SIFo, the successful completion of multiple instructions is verifiable by examining only the final instruction. Our benchmark evaluates instruction following using four tasks (text modification, question answering, mathematics, and security rule following), each assessing different aspects of sequential instruction following. Our evaluation of popular LLMs, both closed-source and open-source, shows that more recent and larger models significantly outperform their older and smaller counterparts on the SIFo tasks, validating the benchmark's effectiveness. All models struggle with following sequences of instructions, hinting at an important lack of robustness of today's language models.
Model Internals-based Answer Attribution for Trustworthy Retrieval-Augmented Generation
Jun 19, 2024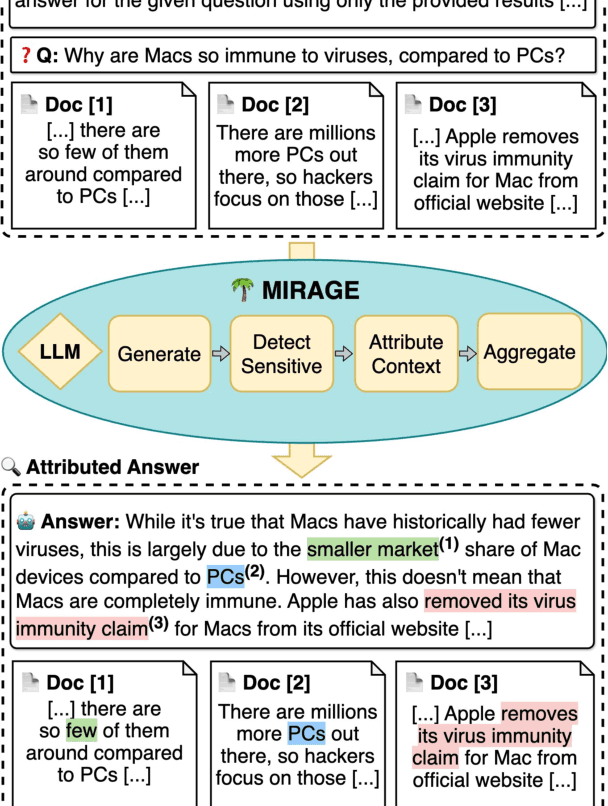

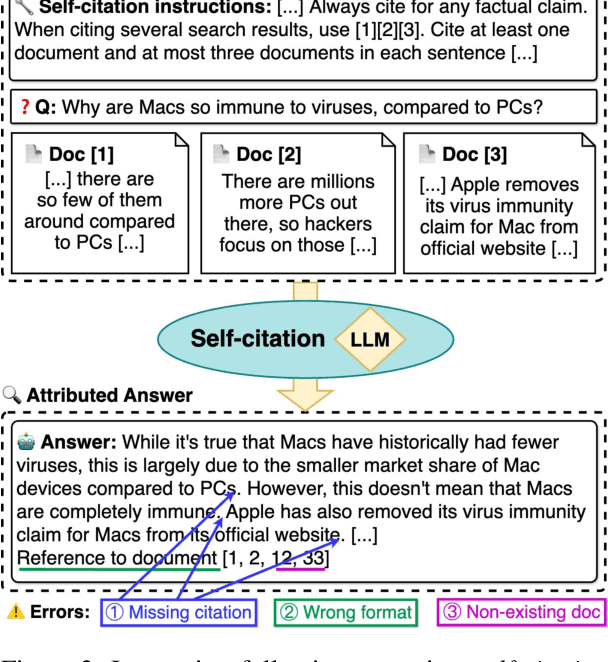
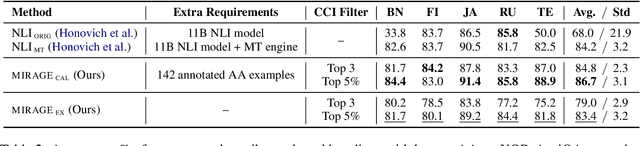
Ensuring the verifiability of model answers is a fundamental challenge for retrieval-augmented generation (RAG) in the question answering (QA) domain. Recently, self-citation prompting was proposed to make large language models (LLMs) generate citations to supporting documents along with their answers. However, self-citing LLMs often struggle to match the required format, refer to non-existent sources, and fail to faithfully reflect LLMs' context usage throughout the generation. In this work, we present MIRAGE --Model Internals-based RAG Explanations -- a plug-and-play approach using model internals for faithful answer attribution in RAG applications. MIRAGE detects context-sensitive answer tokens and pairs them with retrieved documents contributing to their prediction via saliency methods. We evaluate our proposed approach on a multilingual extractive QA dataset, finding high agreement with human answer attribution. On open-ended QA, MIRAGE achieves citation quality and efficiency comparable to self-citation while also allowing for a finer-grained control of attribution parameters. Our qualitative evaluation highlights the faithfulness of MIRAGE's attributions and underscores the promising application of model internals for RAG answer attribution.
Cross-Lingual Consistency of Factual Knowledge in Multilingual Language Models
Oct 21, 2023



Multilingual large-scale Pretrained Language Models (PLMs) have been shown to store considerable amounts of factual knowledge, but large variations are observed across languages. With the ultimate goal of ensuring that users with different language backgrounds obtain consistent feedback from the same model, we study the cross-lingual consistency (CLC) of factual knowledge in various multilingual PLMs. To this end, we propose a Ranking-based Consistency (RankC) metric to evaluate knowledge consistency across languages independently from accuracy. Using this metric, we conduct an in-depth analysis of the determining factors for CLC, both at model level and at language-pair level. Among other results, we find that increasing model size leads to higher factual probing accuracy in most languages, but does not improve cross-lingual consistency. Finally, we conduct a case study on CLC when new factual associations are inserted in the PLMs via model editing. Results on a small sample of facts inserted in English reveal a clear pattern whereby the new piece of knowledge transfers only to languages with which English has a high RankC score.
Cross Domain Few-Shot Learning via Meta Adversarial Training
Mar 01, 2022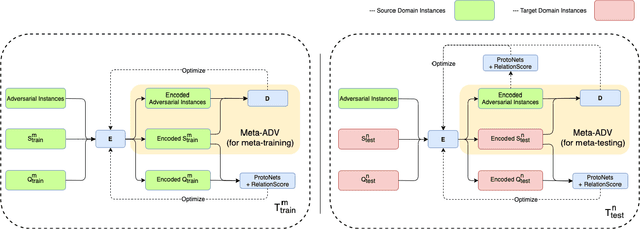
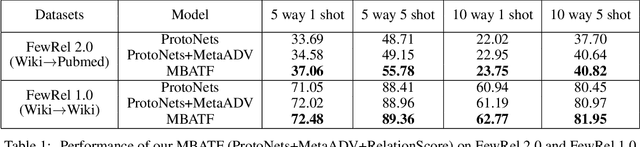
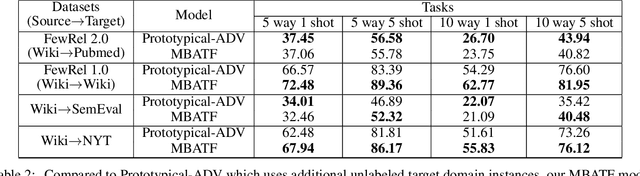
Few-shot relation classification (RC) is one of the critical problems in machine learning. Current research merely focuses on the set-ups that both training and testing are from the same domain. However, in practice, this assumption is not always guaranteed. In this study, we present a novel model that takes into consideration the afore-mentioned cross-domain situation. Not like previous models, we only use the source domain data to train the prototypical networks and test the model on target domain data. A meta-based adversarial training framework (MBATF) is proposed to fine-tune the trained networks for adapting to data from the target domain. Empirical studies confirm the effectiveness of the proposed model.