 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenHalDet: A Unified Benchmark for Hallucination Detection across Diverse Generation Scenarios
Jun 05, 2026Hallucination detection is essential for the reliable deployment of large language models (LLMs). However, existing evaluations face two core challenges: inconsistent inference configuration and evaluation, and limited coverage of downstream domains and tasks. Consequently, reported detector performance is often difficult to compare, reproduce, and generalize beyond specific experimental settings. We introduce OpenHalDet, a unified benchmark for hallucination detection across diverse generation scenarios. OpenHalDet standardizes the evaluation pipeline, from prompt construction and response generation to truthfulness annotation, detector scoring, and metric computation. It supports heterogeneous detector families under different access settings, including black-box methods that use only generated outputs, gray-box methods that rely on probability-based signals, and white-box methods that exploit internal model signals. By bringing diverse tasks, models, and detectors into a shared framework, OpenHalDet enables controlled comparison and provides a systematic view of how different detection paradigms behave in LLM applications. We release OpenHalDet as an open and extensible codebase to facilitate reproducible evaluation and future development of hallucination detection methods. The code and datasets are available at https://github.com/Nellie179/Hallucination-Detection.
Lost in Pronunciation: Detecting Chinese Offensive Language Disguised by Phonetic Cloaking Replacement
Jul 10, 2025Phonetic Cloaking Replacement (PCR), defined as the deliberate use of homophonic or near-homophonic variants to hide toxic intent, has become a major obstacle to Chinese content moderation. While this problem is well-recognized, existing evaluations predominantly rely on rule-based, synthetic perturbations that ignore the creativity of real users. We organize PCR into a four-way surface-form taxonomy and compile \ours, a dataset of 500 naturally occurring, phonetically cloaked offensive posts gathered from the RedNote platform. Benchmarking state-of-the-art LLMs on this dataset exposes a serious weakness: the best model reaches only an F1-score of 0.672, and zero-shot chain-of-thought prompting pushes performance even lower. Guided by error analysis, we revisit a Pinyin-based prompting strategy that earlier studies judged ineffective and show that it recovers much of the lost accuracy. This study offers the first comprehensive taxonomy of Chinese PCR, a realistic benchmark that reveals current detectors' limits, and a lightweight mitigation technique that advances research on robust toxicity detection.
Monte Carlo Planning with Large Language Model for Text-Based Game Agents
Apr 23, 2025Text-based games provide valuable environments for language-based autonomous agents. However, planning-then-learning paradigms, such as those combining Monte Carlo Tree Search (MCTS) and reinforcement learning (RL), are notably time-consuming due to extensive iterations. Additionally, these algorithms perform uncertainty-driven exploration but lack language understanding and reasoning abilities. In this paper, we introduce the Monte Carlo planning with Dynamic Memory-guided Large language model (MC-DML) algorithm. MC-DML leverages the language understanding and reasoning capabilities of Large Language Models (LLMs) alongside the exploratory advantages of tree search algorithms. Specifically, we enhance LLMs with in-trial and cross-trial memory mechanisms, enabling them to learn from past experiences and dynamically adjust action evaluations during planning. We conduct experiments on a series of text-based games from the Jericho benchmark. Our results demonstrate that the MC-DML algorithm significantly enhances performance across various games at the initial planning phase, outperforming strong contemporary methods that require multiple iterations. This demonstrates the effectiveness of our algorithm, paving the way for more efficient language-grounded planning in complex environments.
Enhancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Efficiency in RAG Systems
Jul 15, 2024
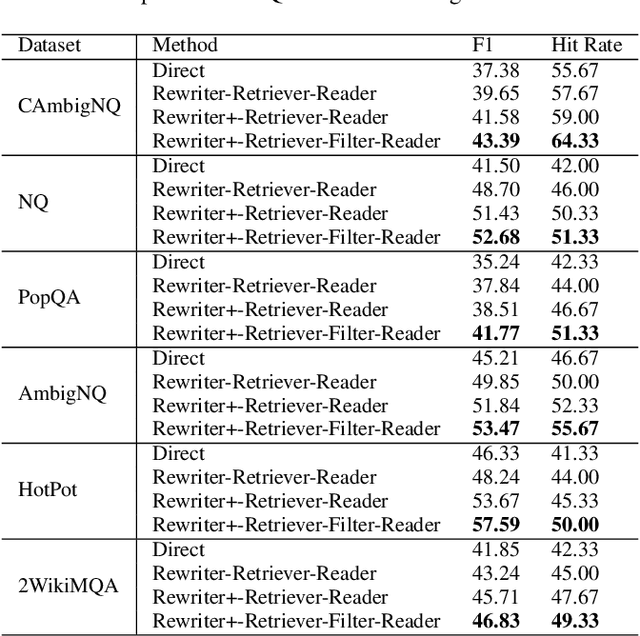


Retrieval-augmented generation (RAG) techniques leverage the in-context learning capabilities of large language models (LLMs) to produce more accurate and relevant responses. Originating from the simple 'retrieve-then-read' approach, the RAG framework has evolved into a highly flexible and modular paradigm. A critical component, the Query Rewriter module, enhances knowledge retrieval by generating a search-friendly query. This method aligns input questions more closely with the knowledge base. Our research identifies opportunities to enhance the Query Rewriter module to Query Rewriter+ by generating multiple queries to overcome the Information Plateaus associated with a single query and by rewriting questions to eliminate Ambiguity, thereby clarifying the underlying intent. We also find that current RAG systems exhibit issues with Irrelevant Knowledge; to overcome this, we propose the Knowledge Filter. These two modules are both based on the instruction-tuned Gemma-2B model, which together enhance response quality. The final identified issue is Redundant Retrieval; we introduce the Memory Knowledge Reservoir and the Retriever Trigger to solve this. The former supports the dynamic expansion of the RAG system's knowledge base in a parameter-free manner, while the latter optimizes the cost for accessing external knowledge, thereby improving resource utilization and response efficiency. These four RAG modules synergistically improve the response quality and efficiency of the RAG system. The effectiveness of these modules has been validated through experiments and ablation studies across six common QA datasets. The source code can be accessed at https://github.com/Ancientshi/ERM4.
ERAGent: Enhancing Retrieval-Augmented Language Models with Improved Accuracy, Efficiency, and Personalization
May 06, 2024



Retrieval-augmented generation (RAG) for language models significantly improves language understanding systems. The basic retrieval-then-read pipeline of response generation has evolved into a more extended process due to the integration of various components, sometimes even forming loop structures. Despite its advancements in improving response accuracy, challenges like poor retrieval quality for complex questions that require the search of multifaceted semantic information, inefficiencies in knowledge re-retrieval during long-term serving, and lack of personalized responses persist. Motivated by transcending these limitations, we introduce ERAGent, a cutting-edge framework that embodies an advancement in the RAG area. Our contribution is the introduction of the synergistically operated module: Enhanced Question Rewriter and Knowledge Filter, for better retrieval quality. Retrieval Trigger is incorporated to curtail extraneous external knowledge retrieval without sacrificing response quality. ERAGent also personalizes responses by incorporating a learned user profile. The efficiency and personalization characteristics of ERAGent are supported by the Experiential Learner module which makes the AI assistant being capable of expanding its knowledge and modeling user profile incrementally. Rigorous evaluations across six datasets and three question-answering tasks prove ERAGent's superior accuracy, efficiency, and personalization, emphasizing its potential to advance the RAG field and its applicability in practical systems.
Large Language Models Are Neurosymbolic Reasoners
Jan 17, 2024



A wide range of real-world applications is characterized by their symbolic nature, necessitating a strong capability for symbolic reasoning. This paper investigates the potential application of Large Language Models (LLMs) as symbolic reasoners. We focus on text-based games, significant benchmarks for agents with natural language capabilities, particularly in symbolic tasks like math, map reading, sorting, and applying common sense in text-based worlds. To facilitate these agents, we propose an LLM agent designed to tackle symbolic challenges and achieve in-game objectives. We begin by initializing the LLM agent and informing it of its role. The agent then receives observations and a set of valid actions from the text-based games, along with a specific symbolic module. With these inputs, the LLM agent chooses an action and interacts with the game environments. Our experimental results demonstrate that our method significantly enhances the capability of LLMs as automated agents for symbolic reasoning, and our LLM agent is effective in text-based games involving symbolic tasks, achieving an average performance of 88% across all tasks.
Cooperation on the Fly: Exploring Language Agents for Ad Hoc Teamwork in the Avalon Game
Dec 29, 2023Multi-agent collaboration with Large Language Models (LLMs) demonstrates proficiency in basic tasks, yet its efficiency in more complex scenarios remains unexplored. In gaming environments, these agents often face situations without established coordination protocols, requiring them to make intelligent inferences about teammates from limited data. This problem motivates the area of ad hoc teamwork, in which an agent may potentially cooperate with a variety of teammates to achieve a shared goal. Our study focuses on the ad hoc teamwork problem where the agent operates in an environment driven by natural language. Our findings reveal the potential of LLM agents in team collaboration, highlighting issues related to hallucinations in communication. To address this issue, we develop CodeAct, a general agent that equips LLM with enhanced memory and code-driven reasoning, enabling the repurposing of partial information for rapid adaptation to new teammates.
CHBias: Bias Evaluation and Mitigation of Chinese Conversational Language Models
May 18, 2023



\textit{\textbf{\textcolor{red}{Warning}:} This paper contains content that may be offensive or upsetting.} Pretrained conversational agents have been exposed to safety issues, exhibiting a range of stereotypical human biases such as gender bias. However, there are still limited bias categories in current research, and most of them only focus on English. In this paper, we introduce a new Chinese dataset, CHBias, for bias evaluation and mitigation of Chinese conversational language models. Apart from those previous well-explored bias categories, CHBias includes under-explored bias categories, such as ageism and appearance biases, which received less attention. We evaluate two popular pretrained Chinese conversational models, CDial-GPT and EVA2.0, using CHBias. Furthermore, to mitigate different biases, we apply several debiasing methods to the Chinese pretrained models. Experimental results show that these Chinese pretrained models are potentially risky for generating texts that contain social biases, and debiasing methods using the proposed dataset can make response generation less biased while preserving the models' conversational capabilities.