 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRCC: Contrast-Based Robust Cross-Subject and Cross-Site Representation Learning for EEG
Feb 22, 2026EEG-based neural decoding models often fail to generalize across acquisition sites due to structured, site-dependent biases implicitly exploited during training. We reformulate cross-site clinical EEG learning as a bias-factorized generalization problem, in which domain shifts arise from multiple interacting sources. We identify three fundamental bias factors and propose a general training framework that mitigates their influence through data standardization and representation-level constraints. We construct a standardized multi-site EEG benchmark for Major Depressive Disorder and introduce CRCC, a two-stage training paradigm combining encoder-decoder pretraining with joint fine-tuning via cross-subject/site contrastive learning and site-adversarial optimization. CRCC consistently outperforms state-of-the-art baselines and achieves a 10.7 percentage-point improvement in balanced accuracy under strict zero-shot site transfer, demonstrating robust generalization to unseen environments.
Satisfaction-Aware Incentive Scheme for Federated Learning in Industrial Metaverse: DRL-Based Stackbelberg Game Approach
Feb 10, 2025Industrial Metaverse leverages the Industrial Internet of Things (IIoT) to integrate data from diverse devices, employing federated learning and meta-computing to train models in a distributed manner while ensuring data privacy. Achieving an immersive experience for industrial Metaverse necessitates maintaining a balance between model quality and training latency. Consequently, a primary challenge in federated learning tasks is optimizing overall system performance by balancing model quality and training latency. This paper designs a satisfaction function that accounts for data size, Age of Information (AoI), and training latency. Additionally, the satisfaction function is incorporated into the utility functions to incentivize node participation in model training. We model the utility functions of servers and nodes as a two-stage Stackelberg game and employ a deep reinforcement learning approach to learn the Stackelberg equilibrium. This approach ensures balanced rewards and enhances the applicability of the incentive scheme for industrial Metaverse. Simulation results demonstrate that, under the same budget constraints, the proposed incentive scheme improves at least 23.7% utility compared to existing schemes without compromising model accuracy.
Learning Social Image Embedding with Deep Multimodal Attention Networks
Oct 18, 2017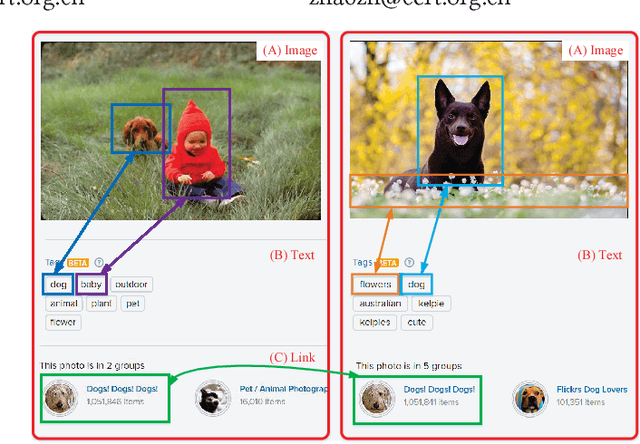
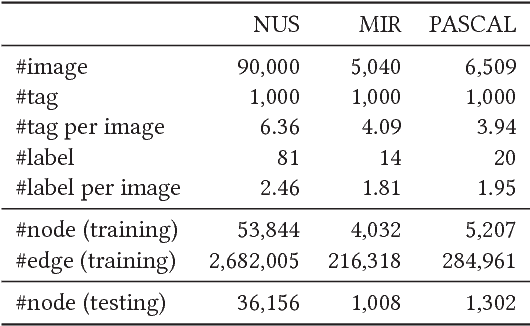
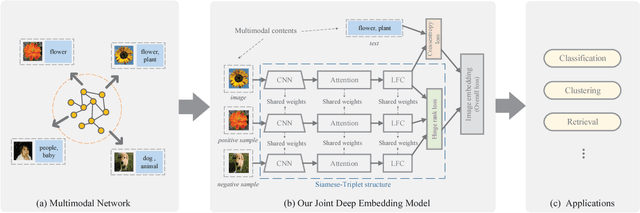
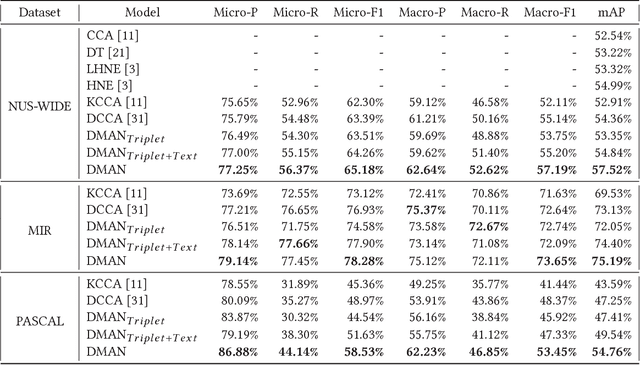
Learning social media data embedding by deep models has attracted extensive research interest as well as boomed a lot of applications, such as link prediction, classification, and cross-modal search. However, for social images which contain both link information and multimodal contents (e.g., text description, and visual content), simply employing the embedding learnt from network structure or data content results in sub-optimal social image representation. In this paper, we propose a novel social image embedding approach called Deep Multimodal Attention Networks (DMAN), which employs a deep model to jointly embed multimodal contents and link information. Specifically, to effectively capture the correlations between multimodal contents, we propose a multimodal attention network to encode the fine-granularity relation between image regions and textual words. To leverage the network structure for embedding learning, a novel Siamese-Triplet neural network is proposed to model the links among images. With the joint deep model, the learnt embedding can capture both the multimodal contents and the nonlinear network information. Extensive experiments are conducted to investigate the effectiveness of our approach in the applications of multi-label classification and cross-modal search. Compared to state-of-the-art image embeddings, our proposed DMAN achieves significant improvement in the tasks of multi-label classification and cross-modal search.