 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenterAtt: Fast 2-stage Center Attention Network
Jun 19, 2021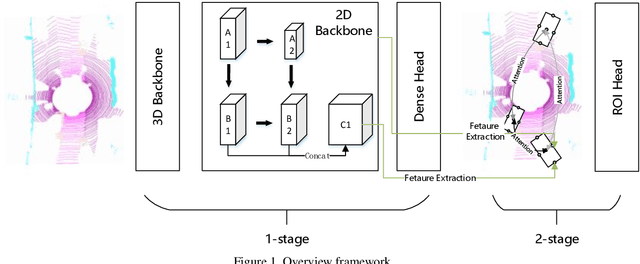
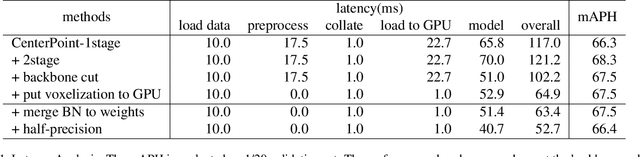


In this technical report, we introduce the methods of HIKVISION_LiDAR_Det in the challenge of waymo open dataset real-time 3D detection. Our solution for the competition are built upon Centerpoint 3D detection framework. Several variants of CenterPoint are explored, including center attention head and feature pyramid network neck. In order to achieve real time detection, methods like batchnorm merge, half-precision floating point network and GPU-accelerated voxelization process are adopted. By using these methods, our team ranks 6th among all the methods on real-time 3D detection challenge in the waymo open dataset.
RPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for LiDAR Point Cloud Segmentation
Mar 24, 2021
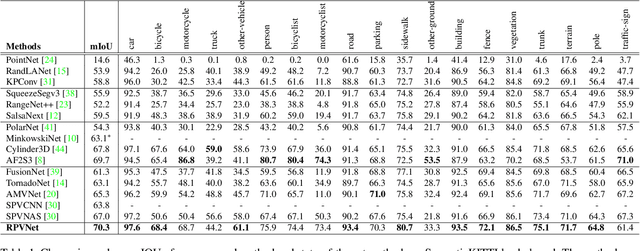
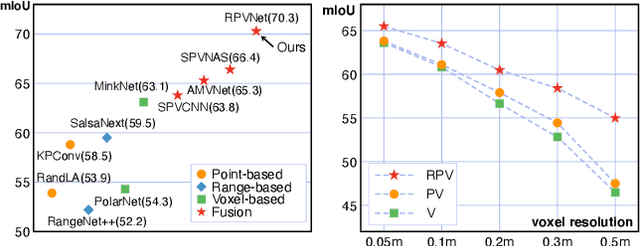
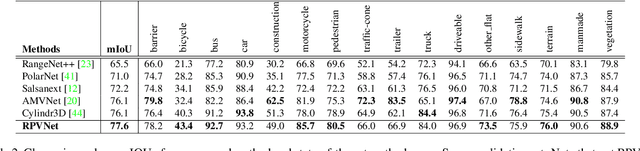
Point clouds can be represented in many forms (views), typically, point-based sets, voxel-based cells or range-based images(i.e., panoramic view). The point-based view is geometrically accurate, but it is disordered, which makes it difficult to find local neighbors efficiently. The voxel-based view is regular, but sparse, and computation grows cubically when voxel resolution increases. The range-based view is regular and generally dense, however spherical projection makes physical dimensions distorted. Both voxel- and range-based views suffer from quantization loss, especially for voxels when facing large-scale scenes. In order to utilize different view's advantages and alleviate their own shortcomings in fine-grained segmentation task, we propose a novel range-point-voxel fusion network, namely RPVNet. In this network, we devise a deep fusion framework with multiple and mutual information interactions among these three views and propose a gated fusion module (termed as GFM), which can adaptively merge the three features based on concurrent inputs. Moreover, the proposed RPV interaction mechanism is highly efficient, and we summarize it into a more general formulation. By leveraging this efficient interaction and relatively lower voxel resolution, our method is also proved to be more efficient. Finally, we evaluated the proposed model on two large-scale datasets, i.e., SemanticKITTI and nuScenes, and it shows state-of-the-art performance on both of them. Note that, our method currently ranks 1st on SemanticKITTI leaderboard without any extra tricks.
BLVD: Building A Large-scale 5D Semantics Benchmark for Autonomous Driving
Mar 15, 2019
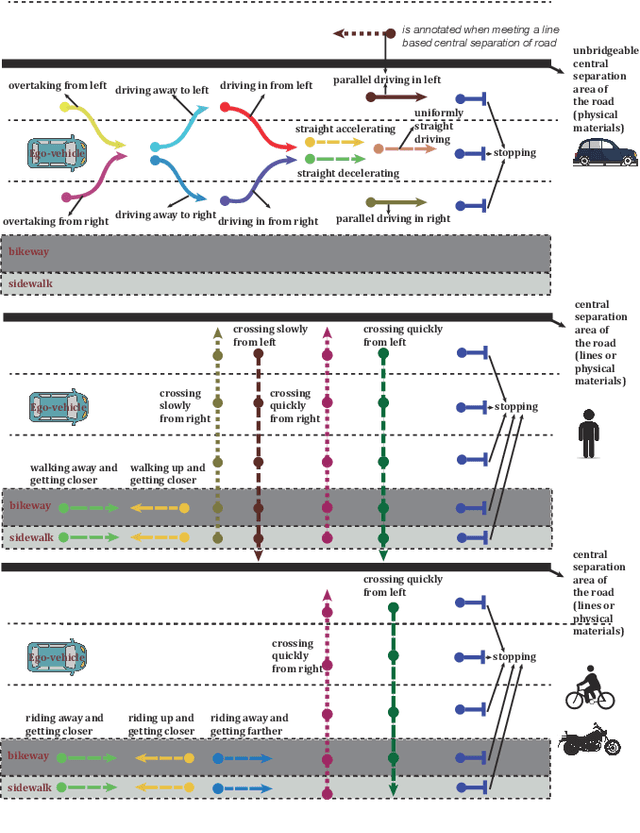
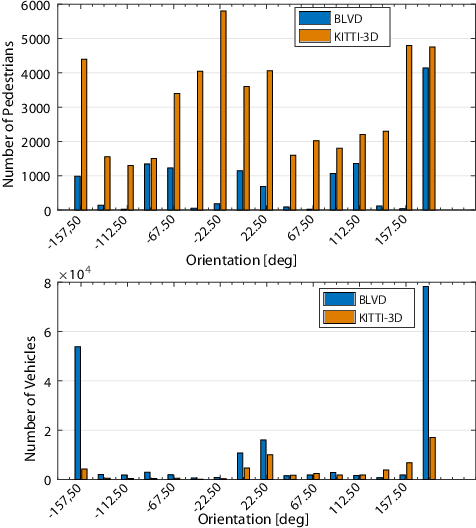
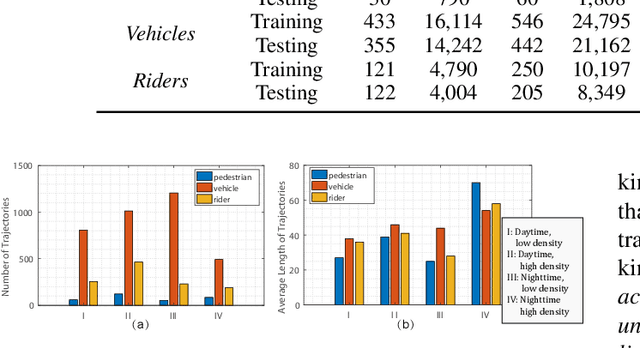
In autonomous driving community, numerous benchmarks have been established to assist the tasks of 3D/2D object detection, stereo vision, semantic/instance segmentation. However, the more meaningful dynamic evolution of the surrounding objects of ego-vehicle is rarely exploited, and lacks a large-scale dataset platform. To address this, we introduce BLVD, a large-scale 5D semantics benchmark which does not concentrate on the static detection or semantic/instance segmentation tasks tackled adequately before. Instead, BLVD aims to provide a platform for the tasks of dynamic 4D (3D+temporal) tracking, 5D (4D+interactive) interactive event recognition and intention prediction. This benchmark will boost the deeper understanding of traffic scenes than ever before. We totally yield 249,129 3D annotations, 4,902 independent individuals for tracking with the length of overall 214,922 points, 6,004 valid fragments for 5D interactive event recognition, and 4,900 individuals for 5D intention prediction. These tasks are contained in four kinds of scenarios depending on the object density (low and high) and light conditions (daytime and nighttime). The benchmark can be downloaded from our project site https://github.com/VCCIV/BLVD/.