 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPVNet: A Deep and Efficient Range-Point-Voxel Fusion Network for LiDAR Point Cloud Segmentation
Paper and Code
Mar 24, 2021
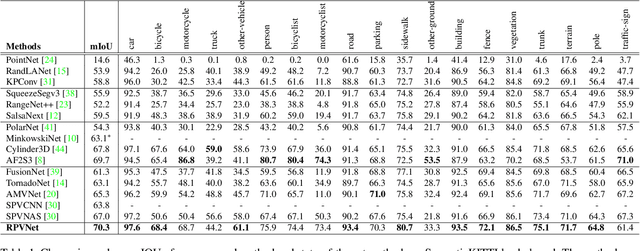
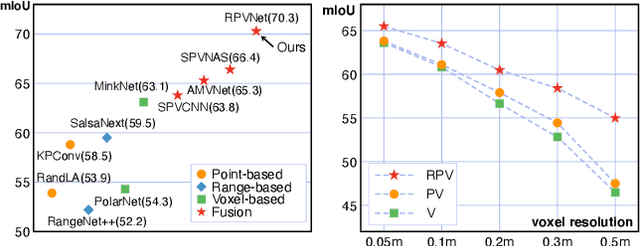
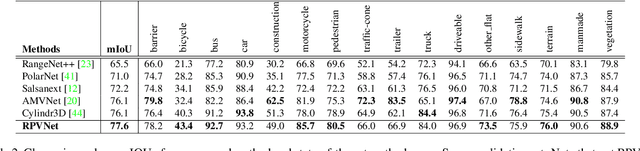
Point clouds can be represented in many forms (views), typically, point-based sets, voxel-based cells or range-based images(i.e., panoramic view). The point-based view is geometrically accurate, but it is disordered, which makes it difficult to find local neighbors efficiently. The voxel-based view is regular, but sparse, and computation grows cubically when voxel resolution increases. The range-based view is regular and generally dense, however spherical projection makes physical dimensions distorted. Both voxel- and range-based views suffer from quantization loss, especially for voxels when facing large-scale scenes. In order to utilize different view's advantages and alleviate their own shortcomings in fine-grained segmentation task, we propose a novel range-point-voxel fusion network, namely RPVNet. In this network, we devise a deep fusion framework with multiple and mutual information interactions among these three views and propose a gated fusion module (termed as GFM), which can adaptively merge the three features based on concurrent inputs. Moreover, the proposed RPV interaction mechanism is highly efficient, and we summarize it into a more general formulation. By leveraging this efficient interaction and relatively lower voxel resolution, our method is also proved to be more efficient. Finally, we evaluated the proposed model on two large-scale datasets, i.e., SemanticKITTI and nuScenes, and it shows state-of-the-art performance on both of them. Note that, our method currently ranks 1st on SemanticKITTI leaderboard without any extra tricks.