 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end speaker diarization with transformer
Paper and Code
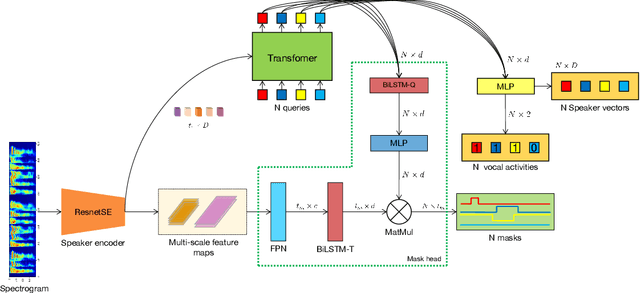

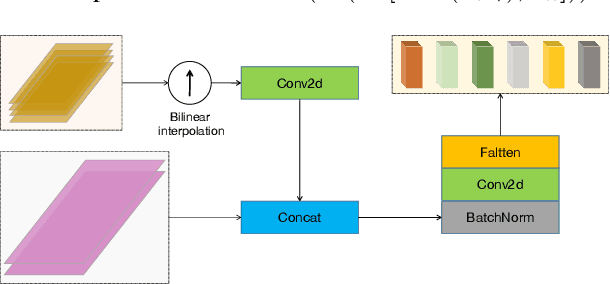
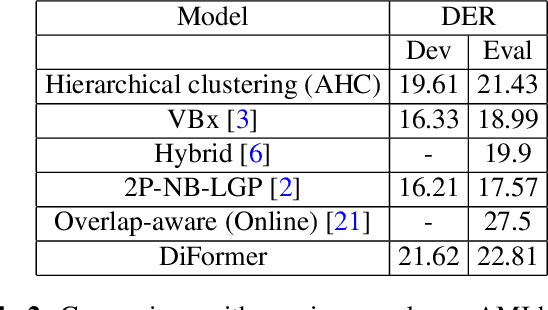
Speaker diarization is connected to semantic segmentation in computer vision. Inspired from MaskFormer \cite{cheng2021per} which treats semantic segmentation as a set-prediction problem, we propose an end-to-end approach to predict a set of targets consisting of binary masks, vocal activities and speaker vectors. Our model, which we coin \textit{DiFormer}, is mainly based on a speaker encoder and a feature pyramid network (FPN) module to extract multi-scale speaker features which are then fed into a transformer encoder-decoder to predict a set of diarization targets from learned query embedding. To account for temporal characteristics of speech signal, bidirectional LSTMs are inserted into the mask prediction module to improve temporal consistency. Our model handles unknown number of speakers, speech overlaps, as well as vocal activity detection in a unified way. Experiments on multimedia and meeting datasets demonstrate the effectiveness of our approach.