 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving short-video speech recognition using random utterance concatenation
Paper and Code
Oct 28, 2022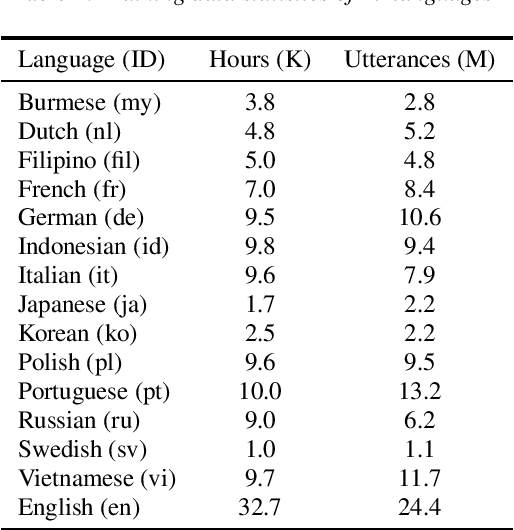
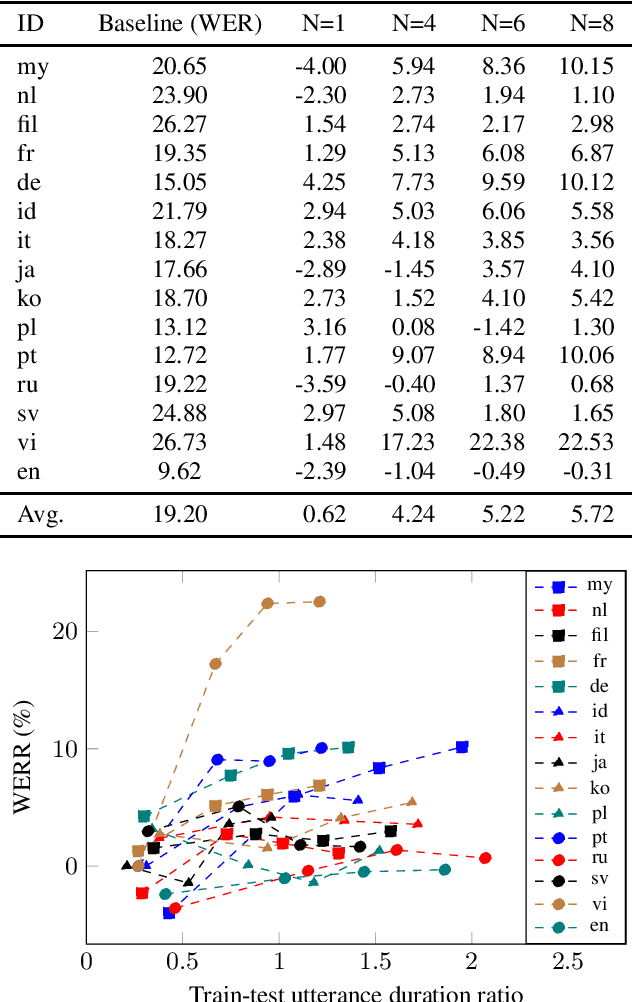
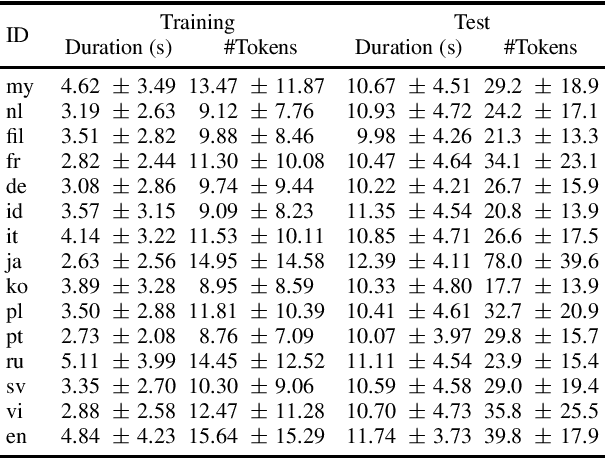
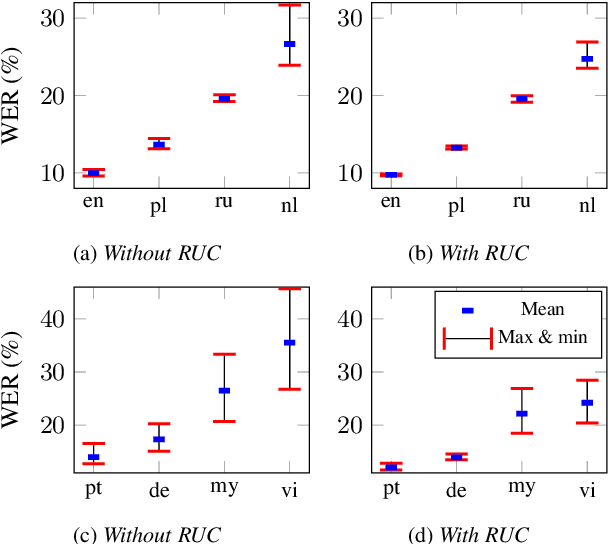
One of the limitations in end-to-end automatic speech recognition framework is its performance would be compromised if train-test utterance lengths are mismatched. In this paper, we propose a random utterance concatenation (RUC) method to alleviate train-test utterance length mismatch issue for short-video speech recognition task. Specifically, we are motivated by observations our human-transcribed training utterances tend to be much shorter for short-video spontaneous speech (~3 seconds on average), while our test utterance generated from voice activity detection front-end is much longer (~10 seconds on average). Such a mismatch can lead to sub-optimal performance. Experimentally, by using the proposed RUC method, the best word error rate reduction (WERR) can be achieved with around three fold training data size increase as well as two utterance concatenation for each. In practice, the proposed method consistently outperforms the strong baseline models, where 3.64% average WERR is achieved on 14 languages.