 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Solution to Connect Speech Encoder and Large Language Model for ASR
Jun 25, 2024
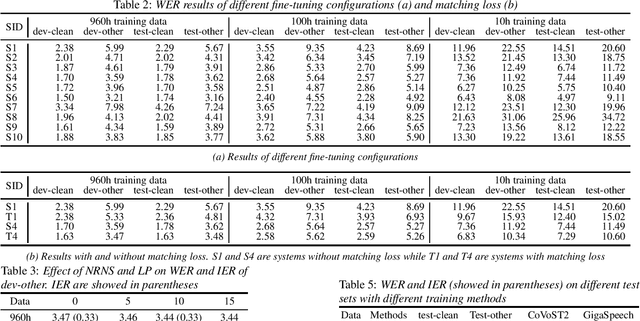
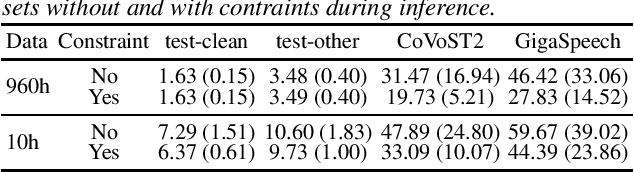
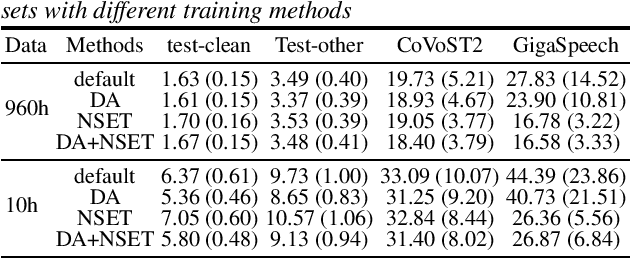
Recent works have shown promising results in connecting speech encoders to large language models (LLMs) for speech recognition. However, several limitations persist, including limited fine-tuning options, a lack of mechanisms to enforce speech-text alignment, and high insertion errors especially in domain mismatch conditions. This paper presents a comprehensive solution to address these issues. We begin by investigating more thoughtful fine-tuning schemes. Next, we propose a matching loss to enhance alignment between modalities. Finally, we explore training and inference methods to mitigate high insertion errors. Experimental results on the Librispeech corpus demonstrate that partially fine-tuning the encoder and LLM using parameter-efficient methods, such as LoRA, is the most cost-effective approach. Additionally, the matching loss improves modality alignment, enhancing performance. The proposed training and inference methods significantly reduce insertion errors.
Improving short-video speech recognition using random utterance concatenation
Oct 28, 2022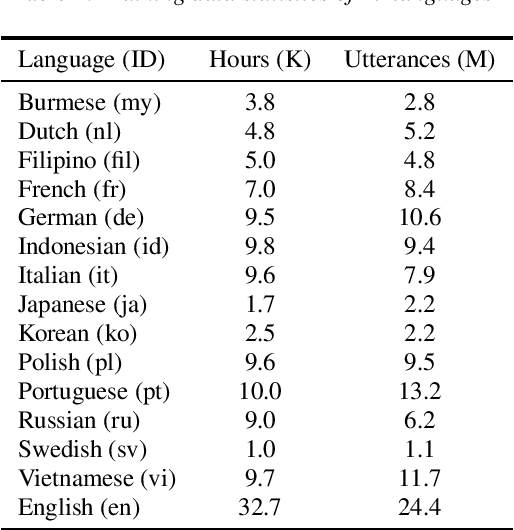
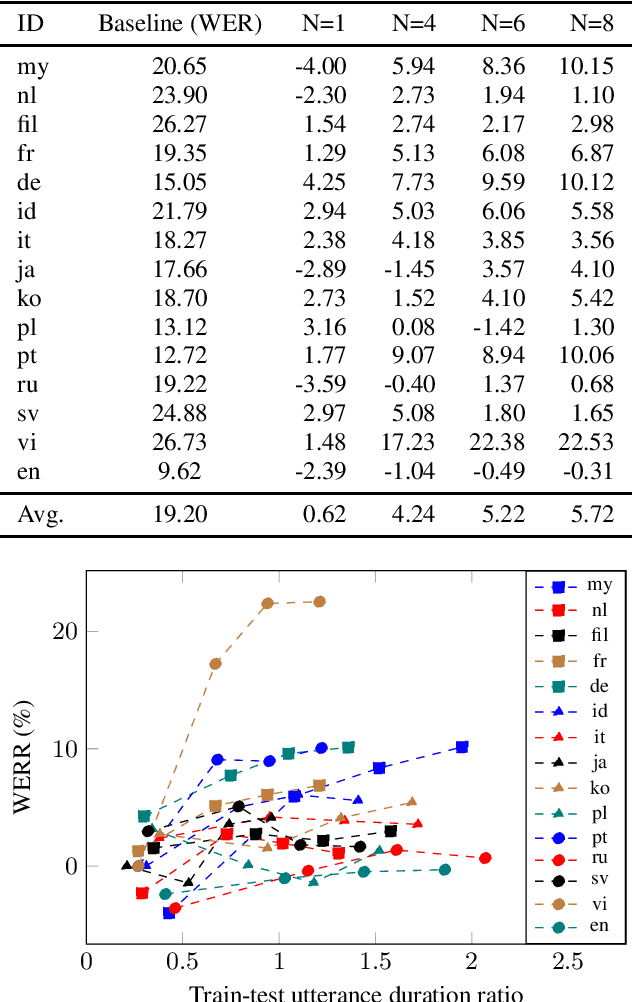
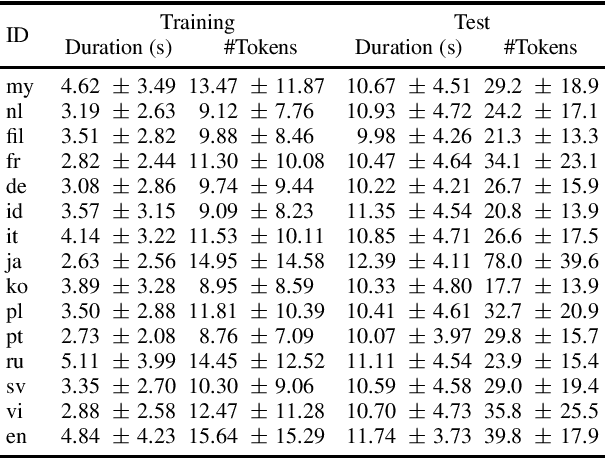
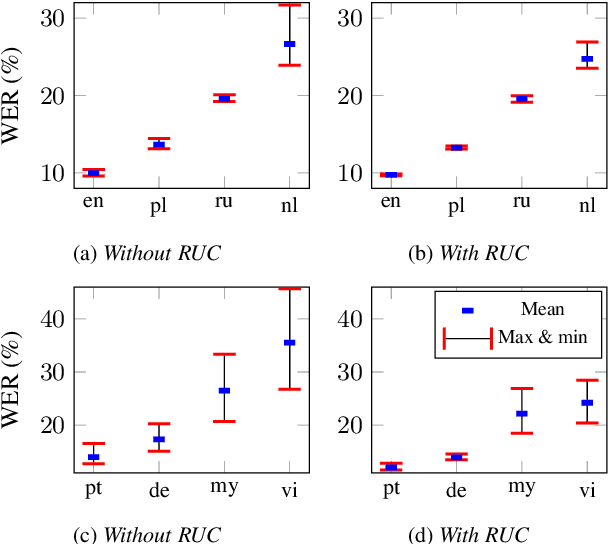
One of the limitations in end-to-end automatic speech recognition framework is its performance would be compromised if train-test utterance lengths are mismatched. In this paper, we propose a random utterance concatenation (RUC) method to alleviate train-test utterance length mismatch issue for short-video speech recognition task. Specifically, we are motivated by observations our human-transcribed training utterances tend to be much shorter for short-video spontaneous speech (~3 seconds on average), while our test utterance generated from voice activity detection front-end is much longer (~10 seconds on average). Such a mismatch can lead to sub-optimal performance. Experimentally, by using the proposed RUC method, the best word error rate reduction (WERR) can be achieved with around three fold training data size increase as well as two utterance concatenation for each. In practice, the proposed method consistently outperforms the strong baseline models, where 3.64% average WERR is achieved on 14 languages.