 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Language Model Estimation based Language Model Fusion for Cross-Domain Code-Switching Speech Recognition
Paper and Code
Jul 09, 2022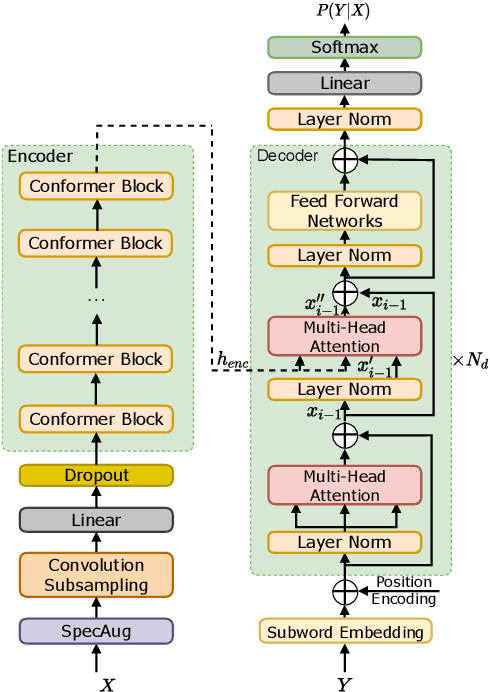
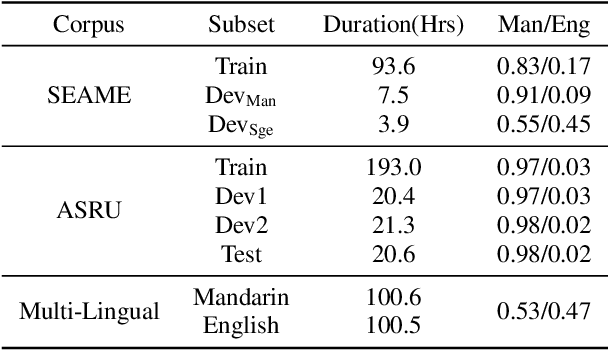
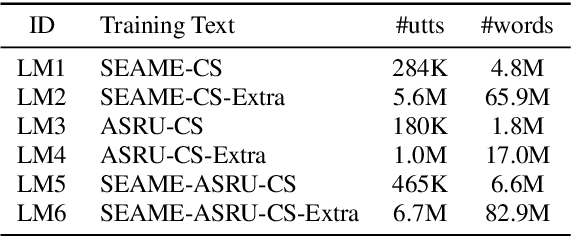
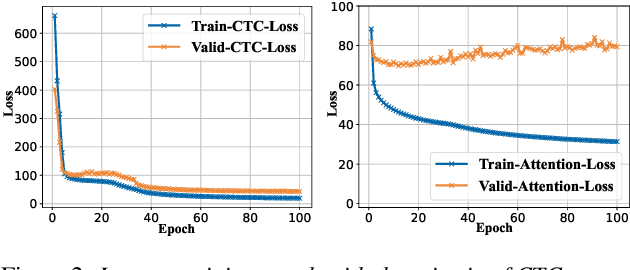
Internal Language Model Estimation (ILME) based language model (LM) fusion has been shown significantly improved recognition results over conventional shallow fusion in both intra-domain and cross-domain speech recognition tasks. In this paper, we attempt to apply our ILME method to cross-domain code-switching speech recognition (CSSR) work. Specifically, our curiosity comes from several aspects. First, we are curious about how effective the ILME-based LM fusion is for both intra-domain and cross-domain CSSR tasks. We verify this with or without merging two code-switching domains. More importantly, we train an end-to-end (E2E) speech recognition model by means of merging two monolingual data sets and observe the efficacy of the proposed ILME-based LM fusion for CSSR. Experimental results on SEAME that is from Southeast Asian and another Chinese Mainland CS data set demonstrate the effectiveness of the proposed ILME-based LM fusion method.