 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing for LLM-Based ASR with Hotword Retrieval and Reinforcement Learning
Dec 26, 2025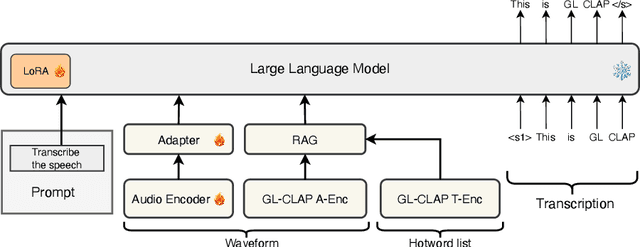
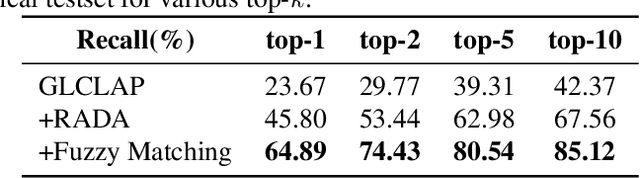
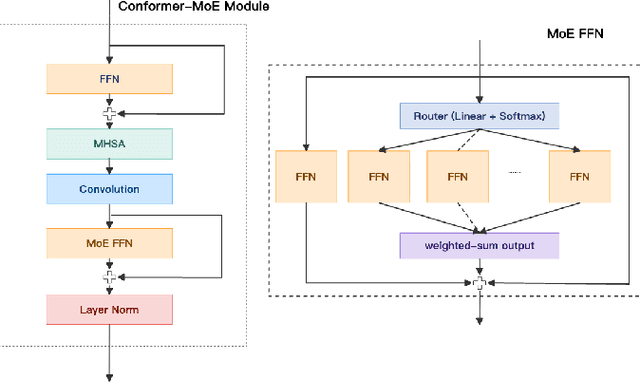
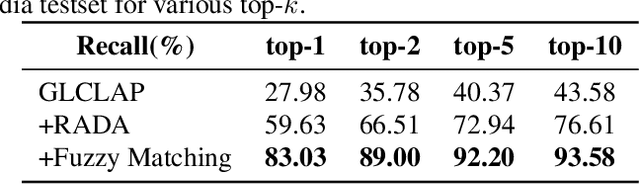
Large language model (LLM)-based automatic speech recognition (ASR) has recently achieved strong performance across diverse tasks, yet contextual biasing for named entities and hotwords under large vocabularies remains challenging. In this work, we propose a scalable two-stage framework that integrates hotword retrieval with LLM-ASR adaptation. First, we extend the Global-Local Contrastive Language-Audio pre-trained model (GLCLAP) to retrieve a compact top-k set of hotword candidates from a large vocabulary via robustness-aware data augmentation and fuzzy matching. Second, we inject the retrieved candidates as textual prompts into an LLM-ASR model and fine-tune it with Generative Rejection-Based Policy Optimization (GRPO), using a task-driven reward that jointly optimizes hotword recognition and overall transcription accuracy. Experiments on hotword-focused test sets show substantial keyword error rate (KER) reductions while maintaining sentence accuracy on general ASR benchmarks, demonstrating the effectiveness of the proposed framework for large-vocabulary contextual biasing.
Intermediate-layer output Regularization for Attention-based Speech Recognition with Shared Decoder
Jul 09, 2022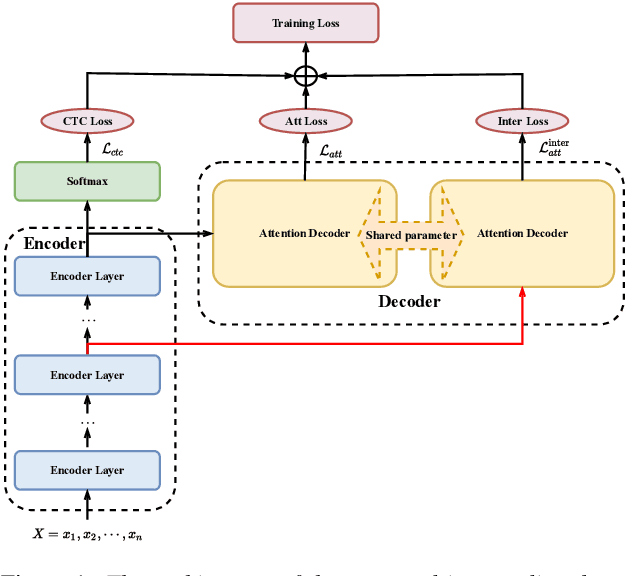
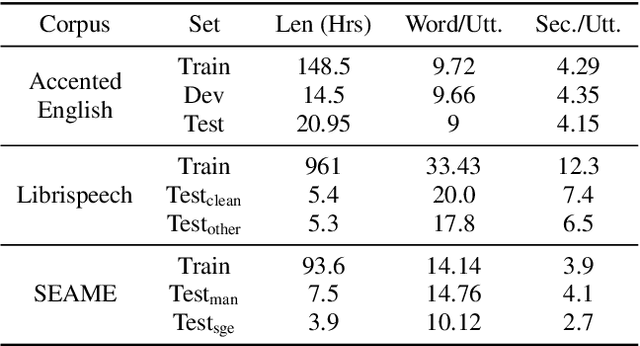
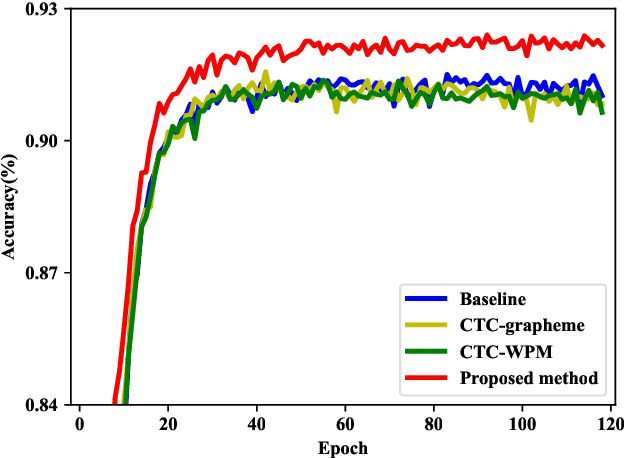
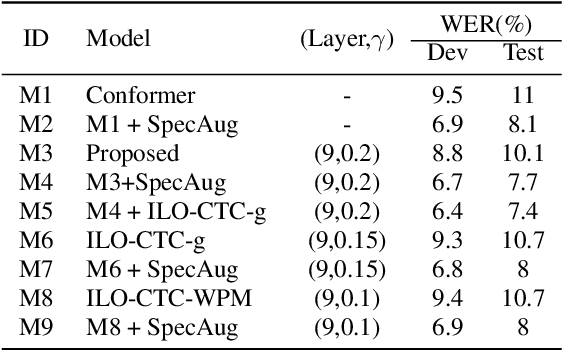
Intermediate layer output (ILO) regularization by means of multitask training on encoder side has been shown to be an effective approach to yielding improved results on a wide range of end-to-end ASR frameworks. In this paper, we propose a novel method to do ILO regularized training differently. Instead of using conventional multitask methods that entail more training overhead, we directly make the intermediate layer output as input to the decoder, that is, our decoder not only accepts the output of the final encoder layer as input, it also takes the output of the encoder ILO as input during training. With the proposed method, as both encoder and decoder are simultaneously "regularized", the network is more sufficiently trained, consistently leading to improved results, over the ILO-based CTC method, as well as over the original attention-based modeling method without the proposed method employed.
Internal Language Model Estimation based Language Model Fusion for Cross-Domain Code-Switching Speech Recognition
Jul 09, 2022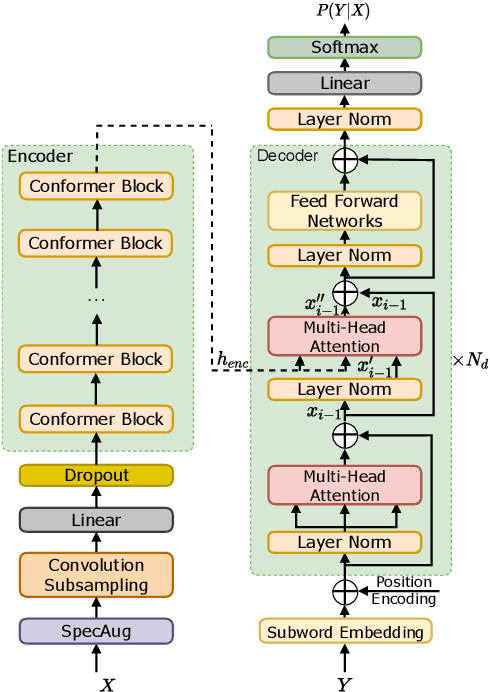
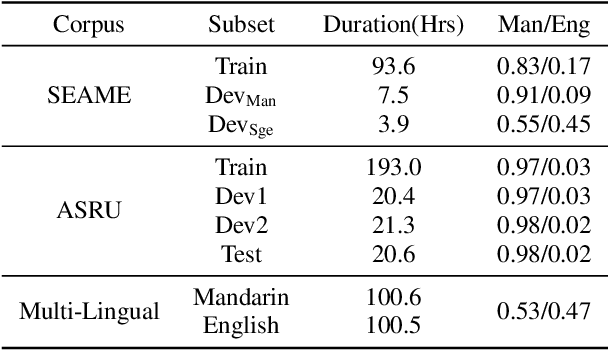
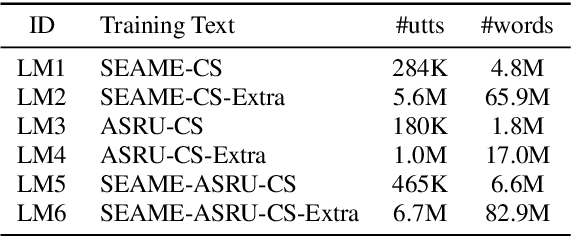
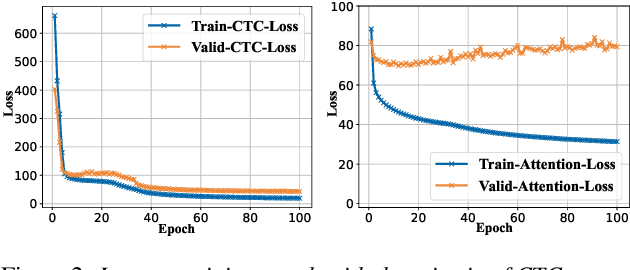
Internal Language Model Estimation (ILME) based language model (LM) fusion has been shown significantly improved recognition results over conventional shallow fusion in both intra-domain and cross-domain speech recognition tasks. In this paper, we attempt to apply our ILME method to cross-domain code-switching speech recognition (CSSR) work. Specifically, our curiosity comes from several aspects. First, we are curious about how effective the ILME-based LM fusion is for both intra-domain and cross-domain CSSR tasks. We verify this with or without merging two code-switching domains. More importantly, we train an end-to-end (E2E) speech recognition model by means of merging two monolingual data sets and observe the efficacy of the proposed ILME-based LM fusion for CSSR. Experimental results on SEAME that is from Southeast Asian and another Chinese Mainland CS data set demonstrate the effectiveness of the proposed ILME-based LM fusion method.
Minimum word error training for non-autoregressive Transformer-based code-switching ASR
Oct 07, 2021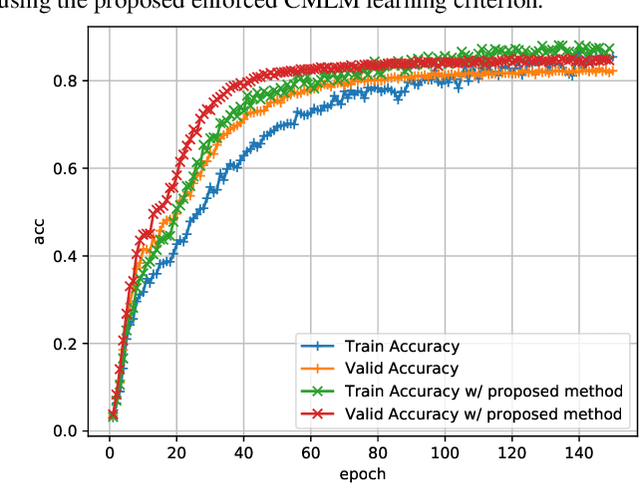
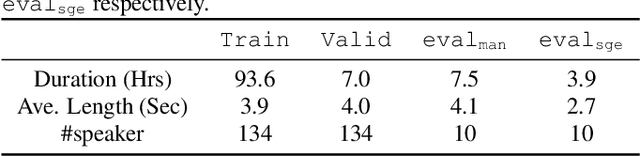

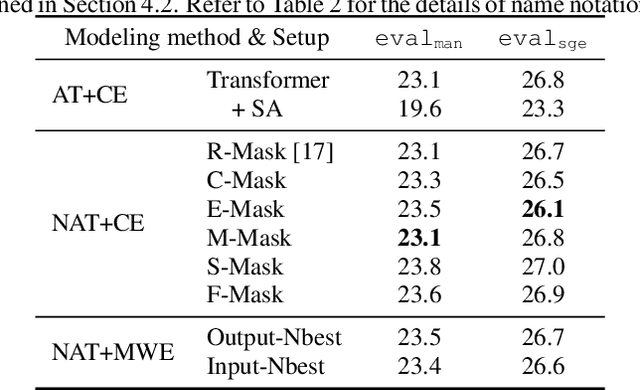
Non-autoregressive end-to-end ASR framework might be potentially appropriate for code-switching recognition task thanks to its inherent property that present output token being independent of historical ones. However, it still under-performs the state-of-the-art autoregressive ASR frameworks. In this paper, we propose various approaches to boosting the performance of a CTC-mask-based nonautoregressive Transformer under code-switching ASR scenario. To begin with, we attempt diversified masking method that are closely related with code-switching point, yielding an improved baseline model. More importantly, we employ MinimumWord Error (MWE) criterion to train the model. One of the challenges is how to generate a diversified hypothetical space, so as to obtain the average loss for a given ground truth. To address such a challenge, we explore different approaches to yielding desired N-best-based hypothetical space. We demonstrate the efficacy of the proposed methods on SEAME corpus, a challenging English-Mandarin code-switching corpus for Southeast Asia community. Compared with the crossentropy-trained strong baseline, the proposed MWE training method achieves consistent performance improvement on the test sets.
E2E-based Multi-task Learning Approach to Joint Speech and Accent Recognition
Jun 15, 2021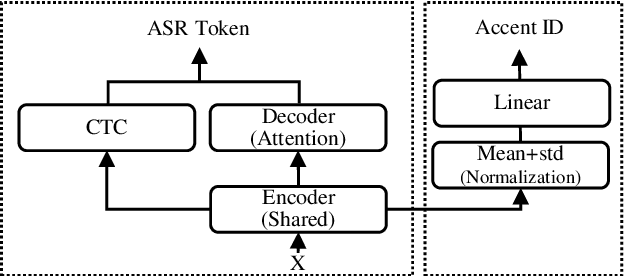
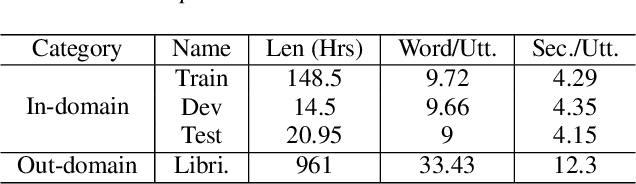
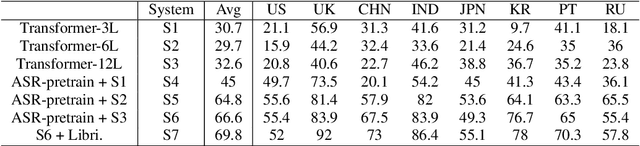
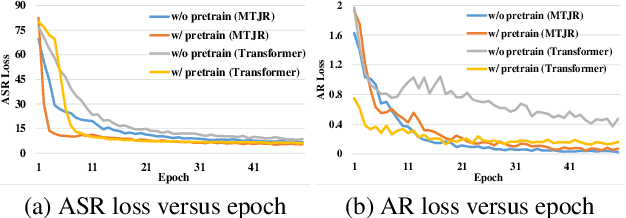
In this paper, we propose a single multi-task learning framework to perform End-to-End (E2E) speech recognition (ASR) and accent recognition (AR) simultaneously. The proposed framework is not only more compact but can also yield comparable or even better results than standalone systems. Specifically, we found that the overall performance is predominantly determined by the ASR task, and the E2E-based ASR pretraining is essential to achieve improved performance, particularly for the AR task. Additionally, we conduct several analyses of the proposed method. First, though the objective loss for the AR task is much smaller compared with its counterpart of ASR task, a smaller weighting factor with the AR task in the joint objective function is necessary to yield better results for each task. Second, we found that sharing only a few layers of the encoder yields better AR results than sharing the overall encoder. Experimentally, the proposed method produces WER results close to the best standalone E2E ASR ones, while it achieves 7.7% and 4.2% relative improvement over standalone and single-task-based joint recognition methods on test set for accent recognition respectively.