 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntermediate-layer output Regularization for Attention-based Speech Recognition with Shared Decoder
Paper and Code
Jul 09, 2022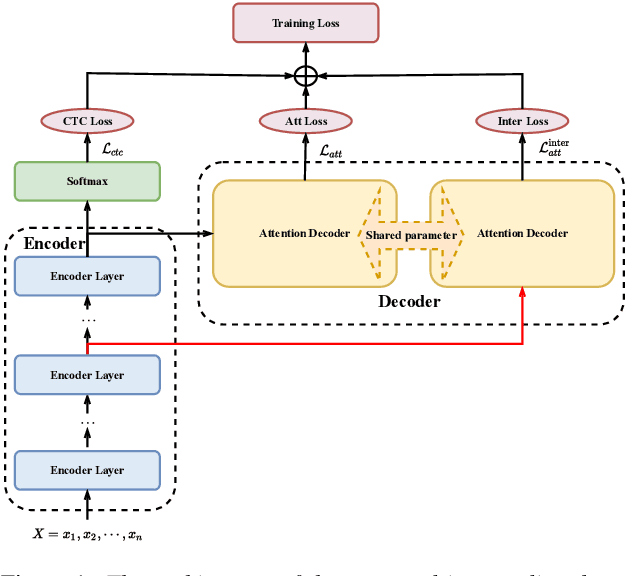
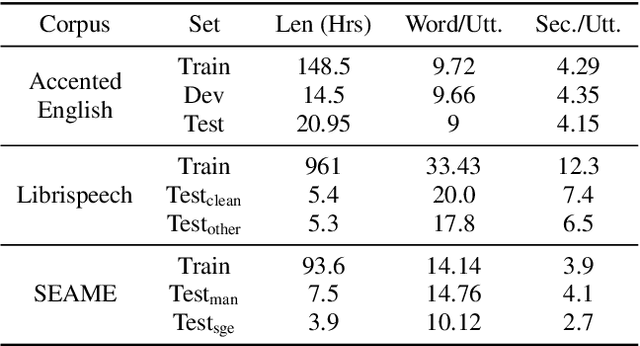
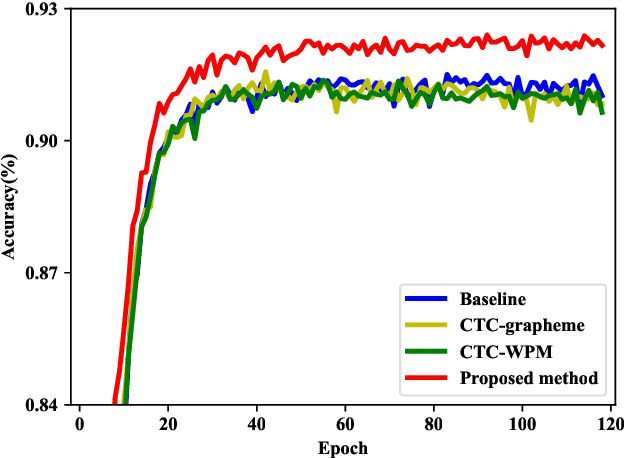
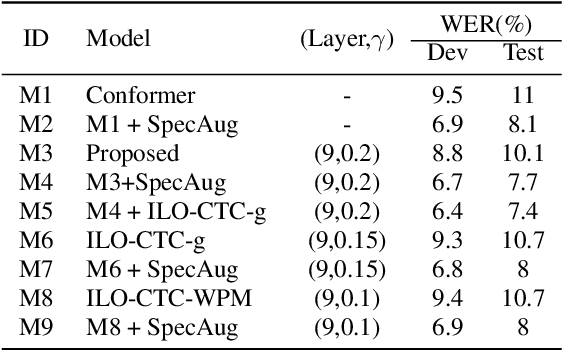
Intermediate layer output (ILO) regularization by means of multitask training on encoder side has been shown to be an effective approach to yielding improved results on a wide range of end-to-end ASR frameworks. In this paper, we propose a novel method to do ILO regularized training differently. Instead of using conventional multitask methods that entail more training overhead, we directly make the intermediate layer output as input to the decoder, that is, our decoder not only accepts the output of the final encoder layer as input, it also takes the output of the encoder ILO as input during training. With the proposed method, as both encoder and decoder are simultaneously "regularized", the network is more sufficiently trained, consistently leading to improved results, over the ILO-based CTC method, as well as over the original attention-based modeling method without the proposed method employed.