 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum word error training for non-autoregressive Transformer-based code-switching ASR
Paper and Code
Oct 07, 2021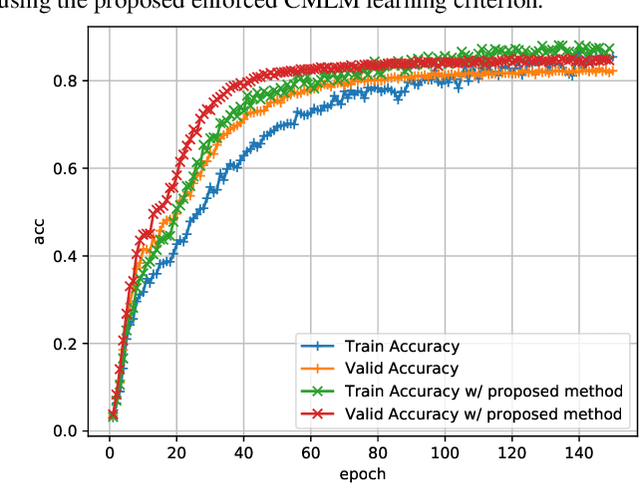
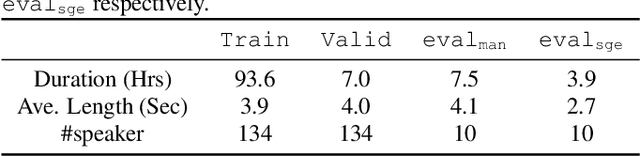

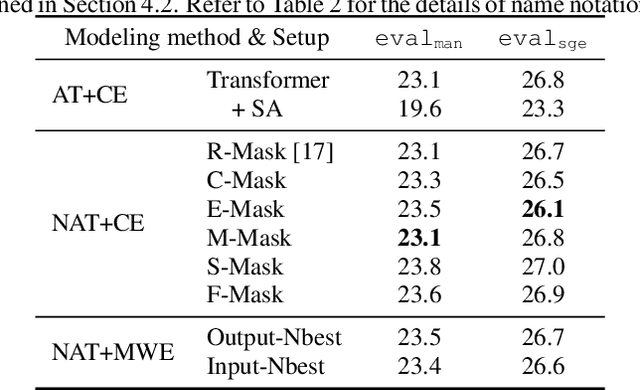
Non-autoregressive end-to-end ASR framework might be potentially appropriate for code-switching recognition task thanks to its inherent property that present output token being independent of historical ones. However, it still under-performs the state-of-the-art autoregressive ASR frameworks. In this paper, we propose various approaches to boosting the performance of a CTC-mask-based nonautoregressive Transformer under code-switching ASR scenario. To begin with, we attempt diversified masking method that are closely related with code-switching point, yielding an improved baseline model. More importantly, we employ MinimumWord Error (MWE) criterion to train the model. One of the challenges is how to generate a diversified hypothetical space, so as to obtain the average loss for a given ground truth. To address such a challenge, we explore different approaches to yielding desired N-best-based hypothetical space. We demonstrate the efficacy of the proposed methods on SEAME corpus, a challenging English-Mandarin code-switching corpus for Southeast Asia community. Compared with the crossentropy-trained strong baseline, the proposed MWE training method achieves consistent performance improvement on the test sets.