 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speaker Representation with Semi-supervised Learning approach for Speaker Profiling
Oct 24, 2021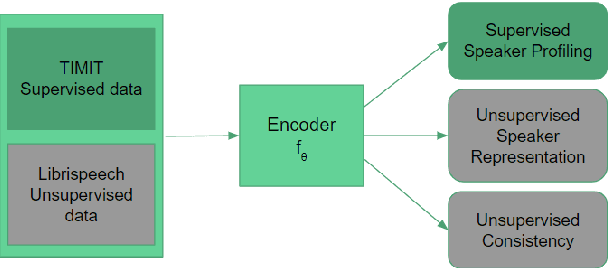
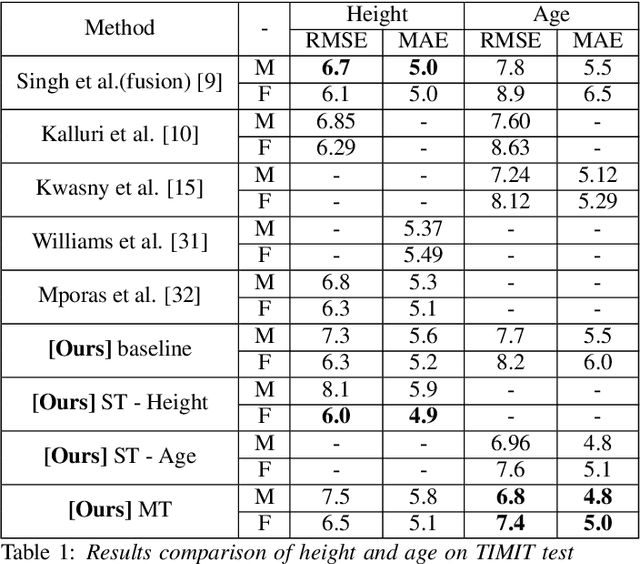
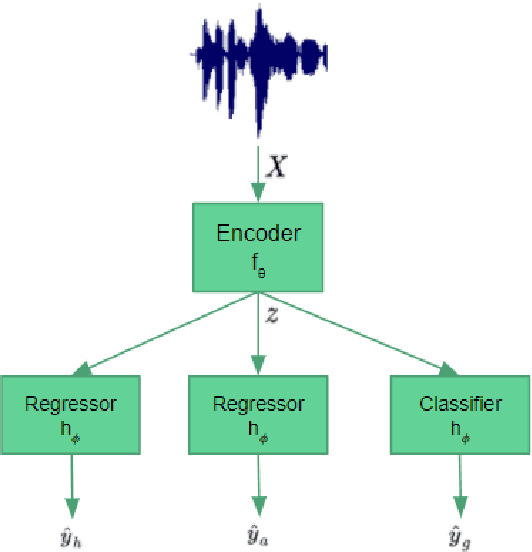
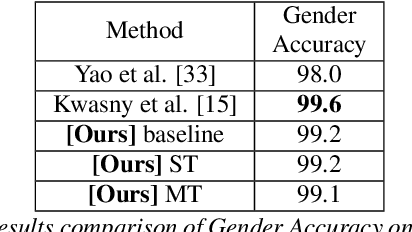
Speaker profiling, which aims to estimate speaker characteristics such as age and height, has a wide range of applications inforensics, recommendation systems, etc. In this work, we propose a semisupervised learning approach to mitigate the issue of low training data for speaker profiling. This is done by utilizing external corpus with speaker information to train a better representation which can help to improve the speaker profiling systems. Specifically, besides the standard supervised learning path, the proposed framework has two more paths: (1) an unsupervised speaker representation learning path that helps to capture the speaker information; (2) a consistency training path that helps to improve the robustness of the system by enforcing it to produce similar predictions for utterances of the same speaker.The proposed approach is evaluated on the TIMIT and NISP datasets for age, height, and gender estimation, while the Librispeech is used as the unsupervised external corpus. Trained both on single-task and multi-task settings, our approach was able to achieve state-of-the-art results on age estimation on the TIMIT Test dataset with Root Mean Square Error(RMSE) of6.8 and 7.4 years and Mean Absolute Error(MAE) of 4.8 and5.0 years for male and female speakers respectively.
E2E-based Multi-task Learning Approach to Joint Speech and Accent Recognition
Jun 15, 2021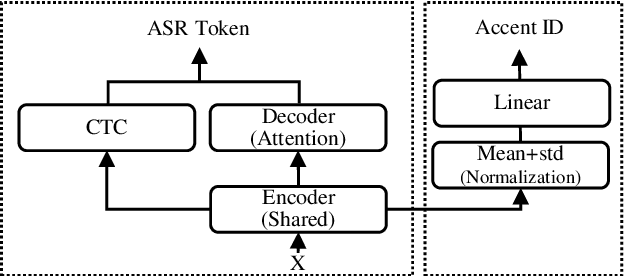
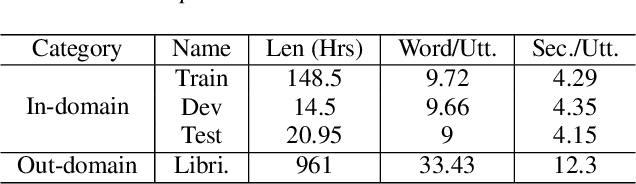
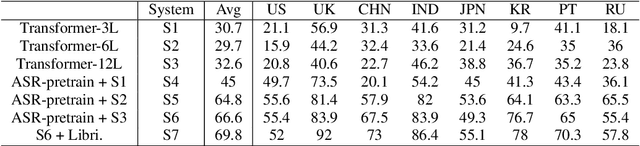
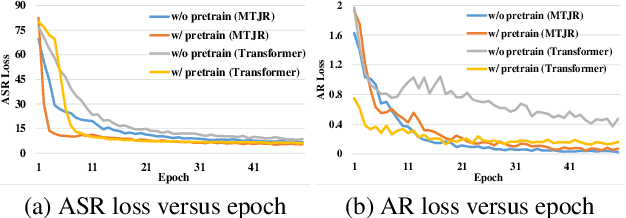
In this paper, we propose a single multi-task learning framework to perform End-to-End (E2E) speech recognition (ASR) and accent recognition (AR) simultaneously. The proposed framework is not only more compact but can also yield comparable or even better results than standalone systems. Specifically, we found that the overall performance is predominantly determined by the ASR task, and the E2E-based ASR pretraining is essential to achieve improved performance, particularly for the AR task. Additionally, we conduct several analyses of the proposed method. First, though the objective loss for the AR task is much smaller compared with its counterpart of ASR task, a smaller weighting factor with the AR task in the joint objective function is necessary to yield better results for each task. Second, we found that sharing only a few layers of the encoder yields better AR results than sharing the overall encoder. Experimentally, the proposed method produces WER results close to the best standalone E2E ASR ones, while it achieves 7.7% and 4.2% relative improvement over standalone and single-task-based joint recognition methods on test set for accent recognition respectively.