 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Speaker Representation with Semi-supervised Learning approach for Speaker Profiling
Paper and Code
Oct 24, 2021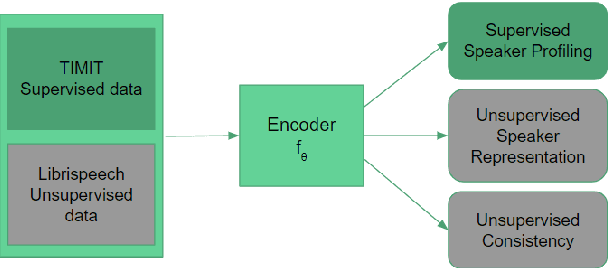
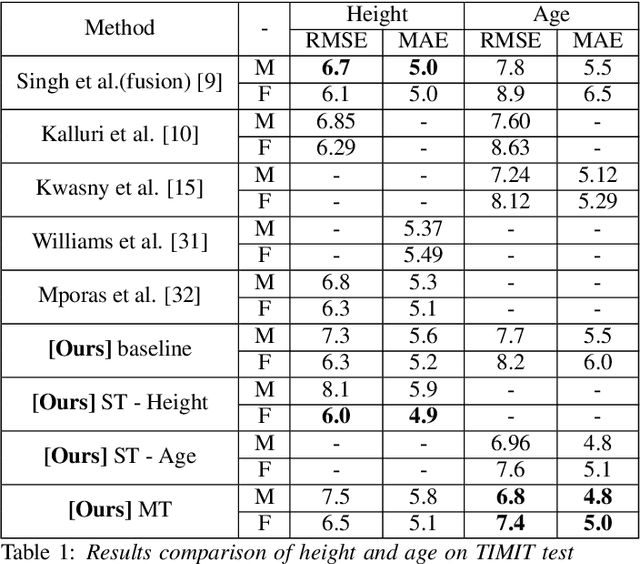
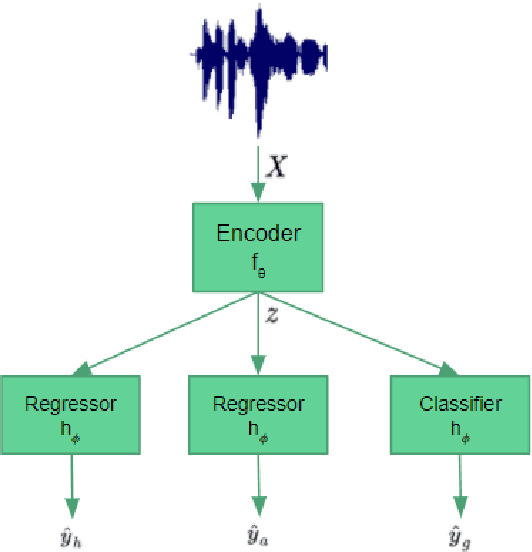
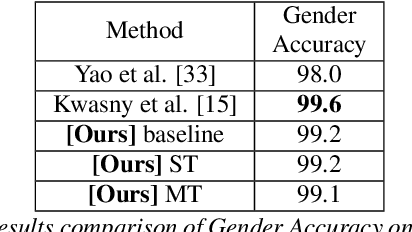
Speaker profiling, which aims to estimate speaker characteristics such as age and height, has a wide range of applications inforensics, recommendation systems, etc. In this work, we propose a semisupervised learning approach to mitigate the issue of low training data for speaker profiling. This is done by utilizing external corpus with speaker information to train a better representation which can help to improve the speaker profiling systems. Specifically, besides the standard supervised learning path, the proposed framework has two more paths: (1) an unsupervised speaker representation learning path that helps to capture the speaker information; (2) a consistency training path that helps to improve the robustness of the system by enforcing it to produce similar predictions for utterances of the same speaker.The proposed approach is evaluated on the TIMIT and NISP datasets for age, height, and gender estimation, while the Librispeech is used as the unsupervised external corpus. Trained both on single-task and multi-task settings, our approach was able to achieve state-of-the-art results on age estimation on the TIMIT Test dataset with Root Mean Square Error(RMSE) of6.8 and 7.4 years and Mean Absolute Error(MAE) of 4.8 and5.0 years for male and female speakers respectively.