 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023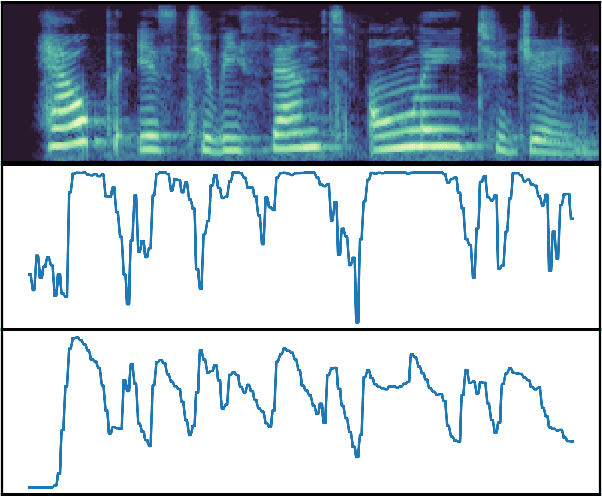
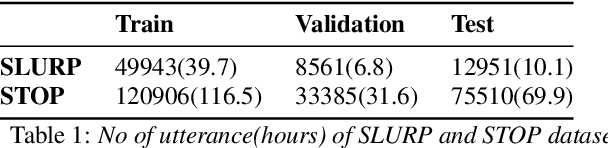
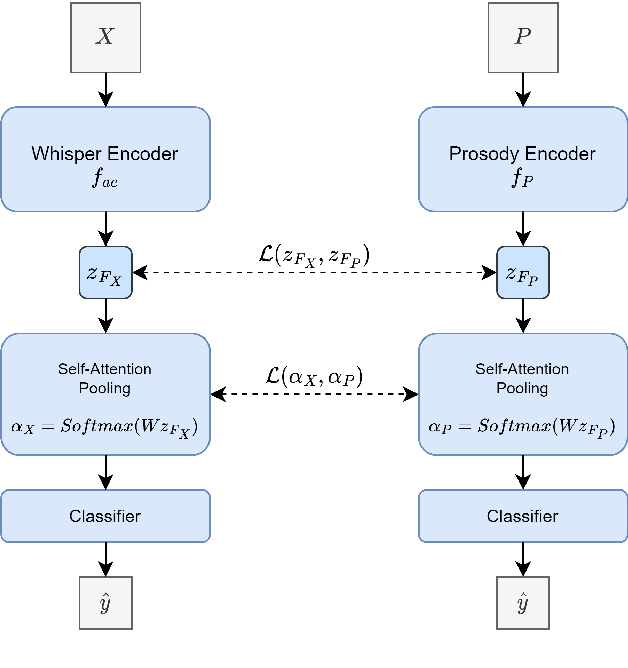
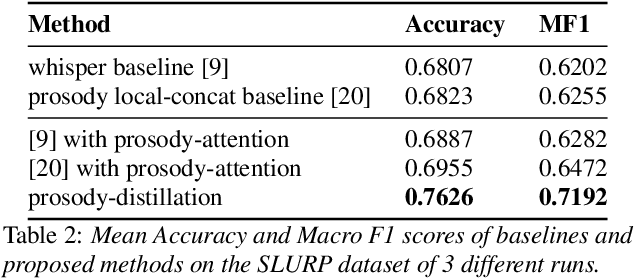
Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
Improving Spoken Language Identification with Map-Mix
Feb 16, 2023The pre-trained multi-lingual XLSR model generalizes well for language identification after fine-tuning on unseen languages. However, the performance significantly degrades when the languages are not very distinct from each other, for example, in the case of dialects. Low resource dialect classification remains a challenging problem to solve. We present a new data augmentation method that leverages model training dynamics of individual data points to improve sampling for latent mixup. The method works well in low-resource settings where generalization is paramount. Our datamaps-based mixup technique, which we call Map-Mix improves weighted F1 scores by 2% compared to the random mixup baseline and results in a significantly well-calibrated model. The code for our method is open sourced on https://github.com/skit-ai/Map-Mix.
Skit-S2I: An Indian Accented Speech to Intent dataset
Dec 26, 2022Conventional conversation assistants extract text transcripts from the speech signal using automatic speech recognition (ASR) and then predict intent from the transcriptions. Using end-to-end spoken language understanding (SLU), the intents of the speaker are predicted directly from the speech signal without requiring intermediate text transcripts. As a result, the model can optimize directly for intent classification and avoid cascading errors from ASR. The end-to-end SLU system also helps in reducing the latency of the intent prediction model. Although many datasets are available publicly for text-to-intent tasks, the availability of labeled speech-to-intent datasets is limited, and there are no datasets available in the Indian accent. In this paper, we release the Skit-S2I dataset, the first publicly available Indian-accented SLU dataset in the banking domain in a conversational tonality. We experiment with multiple baselines, compare different pretrained speech encoder's representations, and find that SSL pretrained representations perform slightly better than ASR pretrained representations lacking prosodic features for speech-to-intent classification. The dataset and baseline code is available at \url{https://github.com/skit-ai/speech-to-intent-dataset}
Learning Speaker Representation with Semi-supervised Learning approach for Speaker Profiling
Oct 24, 2021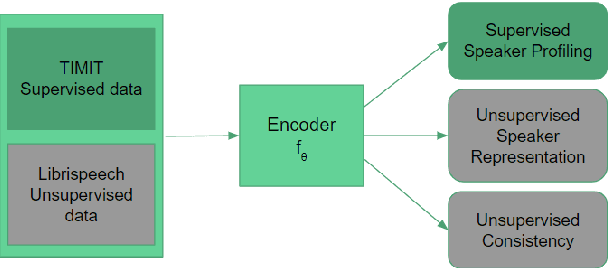
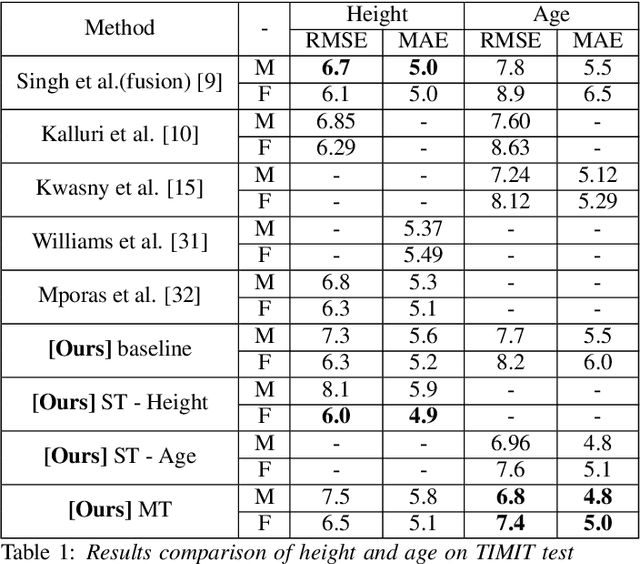
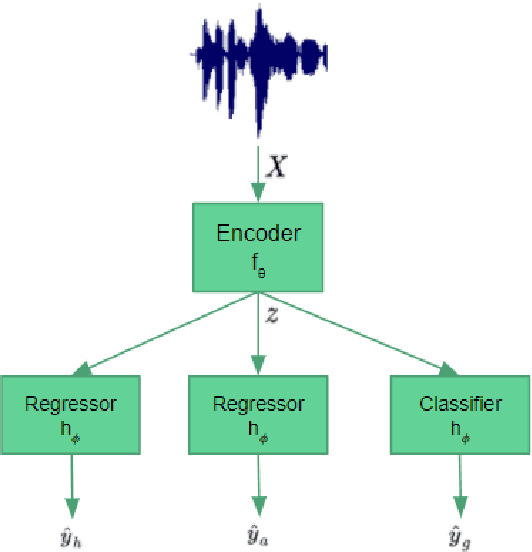
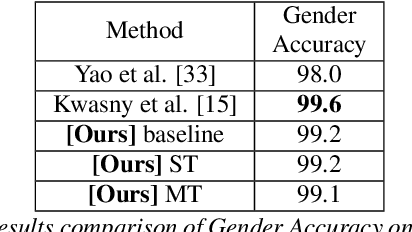
Speaker profiling, which aims to estimate speaker characteristics such as age and height, has a wide range of applications inforensics, recommendation systems, etc. In this work, we propose a semisupervised learning approach to mitigate the issue of low training data for speaker profiling. This is done by utilizing external corpus with speaker information to train a better representation which can help to improve the speaker profiling systems. Specifically, besides the standard supervised learning path, the proposed framework has two more paths: (1) an unsupervised speaker representation learning path that helps to capture the speaker information; (2) a consistency training path that helps to improve the robustness of the system by enforcing it to produce similar predictions for utterances of the same speaker.The proposed approach is evaluated on the TIMIT and NISP datasets for age, height, and gender estimation, while the Librispeech is used as the unsupervised external corpus. Trained both on single-task and multi-task settings, our approach was able to achieve state-of-the-art results on age estimation on the TIMIT Test dataset with Root Mean Square Error(RMSE) of6.8 and 7.4 years and Mean Absolute Error(MAE) of 4.8 and5.0 years for male and female speakers respectively.
Convolutional Feature Extraction and Neural Arithmetic Logic Units for Stock Prediction
May 18, 2019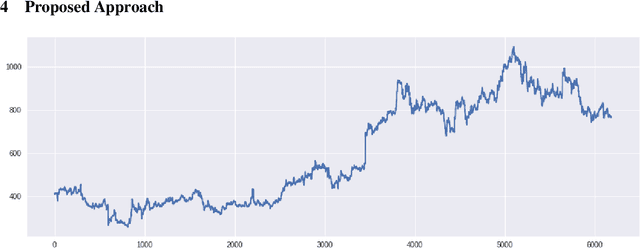


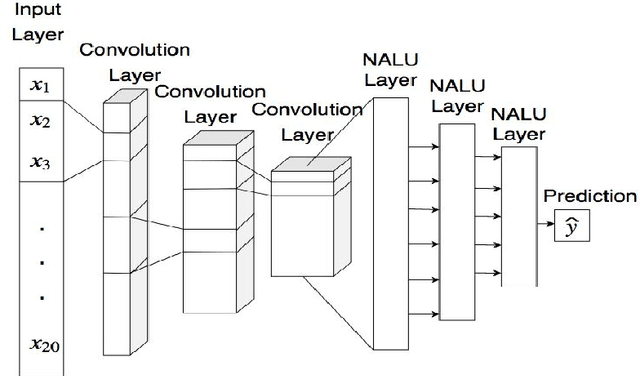
Stock prediction is a topic undergoing intense study for many years. Finance experts and mathematicians have been working on a way to predict the future stock price so as to decide to buy the stock or sell it to make profit. Stock experts or economists, usually analyze on the previous stock values using technical indicators, sentiment analysis etc to predict the future stock price. In recent years, many researches have extensively used machine learning for predicting the stock behaviour. In this paper we propose data driven deep learning approach to predict the future stock value with the previous price with the feature extraction property of convolutional neural network and to use Neural Arithmetic Logic Units with it.