 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Code-switching Speech Recognition with Interactive Language Biases
Paper and Code
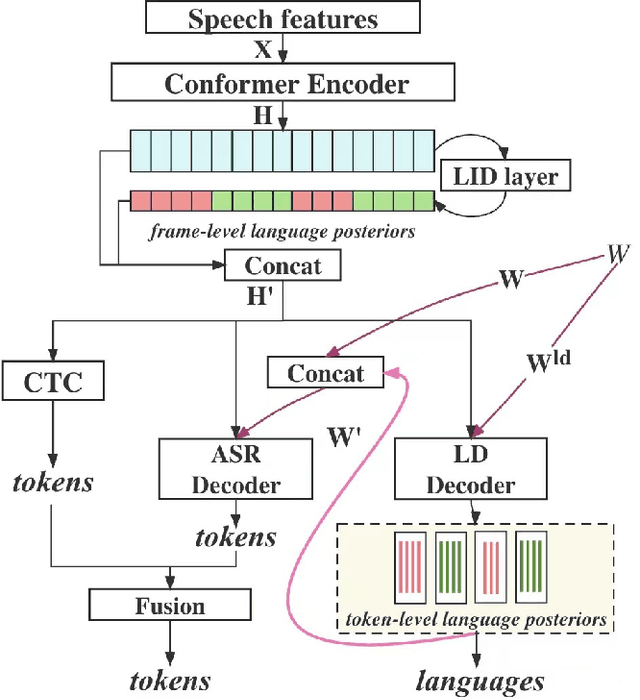

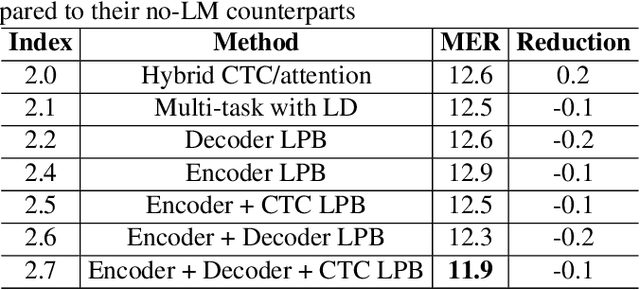
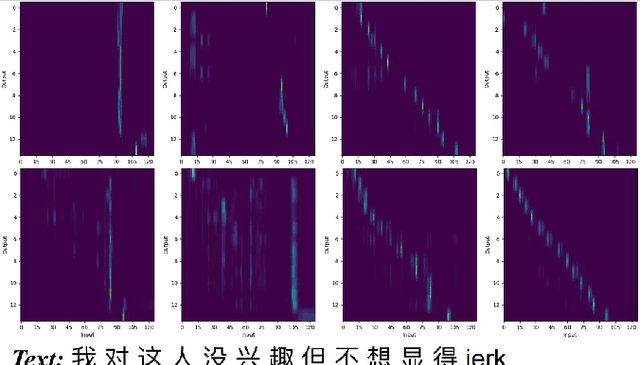
Languages usually switch within a multilingual speech signal, especially in a bilingual society. This phenomenon is referred to as code-switching (CS), making automatic speech recognition (ASR) challenging under a multilingual scenario. We propose to improve CS-ASR by biasing the hybrid CTC/attention ASR model with multi-level language information comprising frame- and token-level language posteriors. The interaction between various resolutions of language biases is subsequently explored in this work. We conducted experiments on datasets from the ASRU 2019 code-switching challenge. Compared to the baseline, the proposed interactive language biases (ILB) method achieves higher performance and ablation studies highlight the effects of different language biases and their interactions. In addition, the results presented indicate that language bias implicitly enhances internal language modeling, leading to performance degradation after employing an external language model.