 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Paper and Code

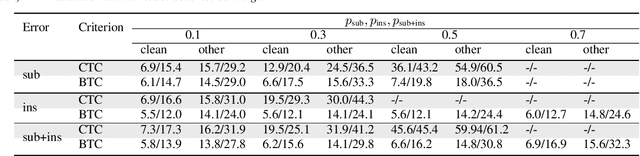
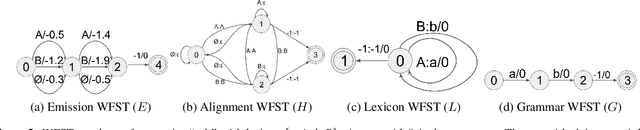
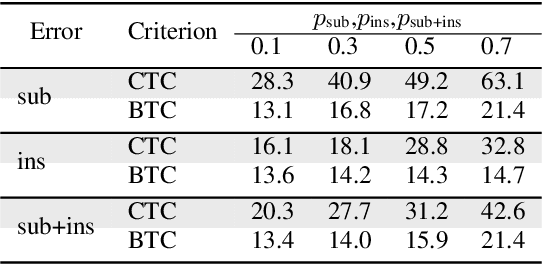
This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.