 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective State Space Model for Monaural Speech Enhancement
Nov 09, 2024
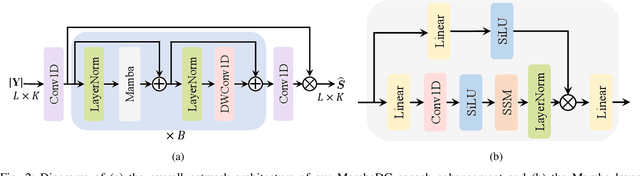
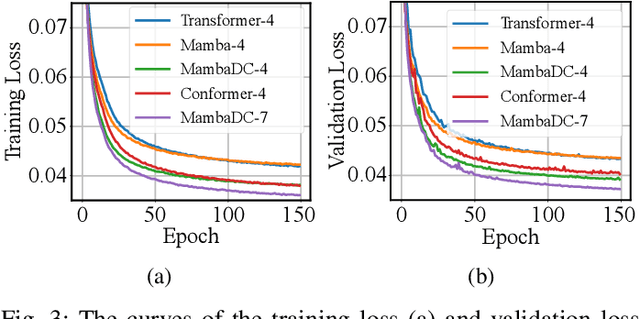
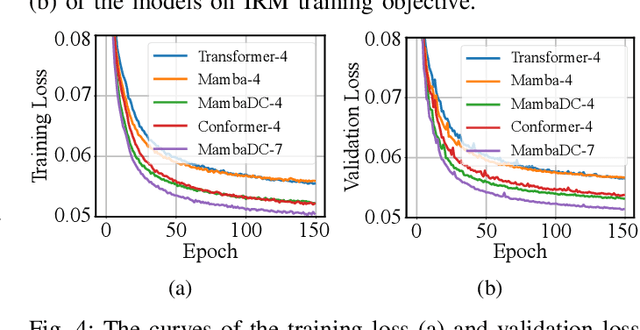
Voice user interfaces (VUIs) have facilitated the efficient interactions between humans and machines through spoken commands. Since real-word acoustic scenes are complex, speech enhancement plays a critical role for robust VUI. Transformer and its variants, such as Conformer, have demonstrated cutting-edge results in speech enhancement. However, both of them suffers from the quadratic computational complexity with respect to the sequence length, which hampers their ability to handle long sequences. Recently a novel State Space Model called Mamba, which shows strong capability to handle long sequences with linear complexity, offers a solution to address this challenge. In this paper, we propose a novel hybrid convolution-Mamba backbone, denoted as MambaDC, for speech enhancement. Our MambaDC marries the benefits of convolutional networks to model the local interactions and Mamba's ability for modeling long-range global dependencies. We conduct comprehensive experiments within both basic and state-of-the-art (SoTA) speech enhancement frameworks, on two commonly used training targets. The results demonstrate that MambaDC outperforms Transformer, Conformer, and the standard Mamba across all training targets. Built upon the current advanced framework, the use of MambaDC backbone showcases superior results compared to existing \textcolor{black}{SoTA} systems. This sets the stage for efficient long-range global modeling in speech enhancement.
Human Activity Recognition with Low-Resolution Infrared Array Sensor Using Semi-supervised Cross-domain Neural Networks for Indoor Environment
Mar 05, 2024Low-resolution infrared-based human activity recognition (HAR) attracted enormous interests due to its low-cost and private. In this paper, a novel semi-supervised crossdomain neural network (SCDNN) based on 8 $\times$ 8 low-resolution infrared sensor is proposed for accurately identifying human activity despite changes in the environment at a low-cost. The SCDNN consists of feature extractor, domain discriminator and label classifier. In the feature extractor, the unlabeled and minimal labeled target domain data are trained for domain adaptation to achieve a mapping of the source domain and target domain data. The domain discriminator employs the unsupervised learning to migrate data from the source domain to the target domain. The label classifier obtained from training the source domain data improves the recognition of target domain activities due to the semi-supervised learning utilized in training the target domain data. Experimental results show that the proposed method achieves 92.12\% accuracy for recognition of activities in the target domain by migrating the source and target domains. The proposed approach adapts superior to cross-domain scenarios compared to the existing deep learning methods, and it provides a low-cost yet highly adaptable solution for cross-domain scenarios.