 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentLens: Revealing The Lucky Pass Problem in SWE-Agent Evaluation
May 13, 2026Evaluation of software engineering (SWE) agents is dominated by a binary signal: whether the final patch passes the tests. This outcome-only view treats a principled solution and a chaotic trial-and-error process as equivalent. We show that this equivalence is empirically false. We evaluate 2,614 OpenHands trajectories from eight model backends on 60 SWE-bench Verified tasks. Of these, 47 have enough passing trajectories to construct task-level process references, yielding a 1,815-trajectory evaluation subset. Among passing trajectories in this subset, 10.7% exhibit behavior we call a Lucky Pass: regression cycles, blind retries, missing verification, or temporally disordered exploration, implementation, and verification. We introduce AgentLens, a framework for process-level assessment of SWE-agent trajectories, and release AgentLens-Bench, a dataset of 1,815 trajectories annotated with quality scores, waste signals, divergence points, and 47 task-level Prefix Tree Acceptor (PTA) references. AgentLens builds PTA references by merging multiple passing solutions for the same task, and uses a context-sensitive intent labeler to assign actions to Exploration, Implementation, Verification, or Orchestration based on trajectory history rather than tool identity alone. On AgentLens-Bench, the quality score separates passing trajectories into Lucky, Solid, and Ideal tiers and further decomposes Lucky Passes into five recurring mechanisms. Across the eight model backends, Lucky rates range from 0.5% to 23.2%, and some models move by as many as five rank positions when ranked by quality score instead of pass rate. We release the anonymized project repository, including the AgentLens-Bench dataset and AgentLens SDK, at https://github.com/microsoft/code-agent-state-trajectories/.
DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
Feb 11, 2026Existing multimodal retrieval systems excel at semantic matching but implicitly assume that query-image relevance can be measured in isolation. This paradigm overlooks the rich dependencies inherent in realistic visual streams, where information is distributed across temporal sequences rather than confined to single snapshots. To bridge this gap, we introduce DeepImageSearch, a novel agentic paradigm that reformulates image retrieval as an autonomous exploration task. Models must plan and perform multi-step reasoning over raw visual histories to locate targets based on implicit contextual cues. We construct DISBench, a challenging benchmark built on interconnected visual data. To address the scalability challenge of creating context-dependent queries, we propose a human-model collaborative pipeline that employs vision-language models to mine latent spatiotemporal associations, effectively offloading intensive context discovery before human verification. Furthermore, we build a robust baseline using a modular agent framework equipped with fine-grained tools and a dual-memory system for long-horizon navigation. Extensive experiments demonstrate that DISBench poses significant challenges to state-of-the-art models, highlighting the necessity of incorporating agentic reasoning into next-generation retrieval systems.
Synthesize-on-Graph: Knowledgeable Synthetic Data Generation for Continue Pre-training of Large Language Models
May 02, 2025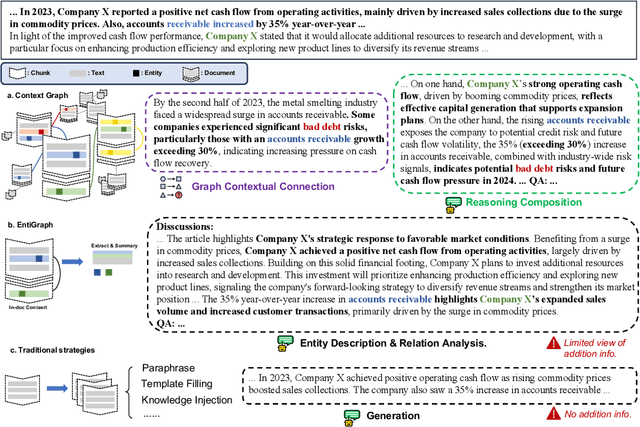
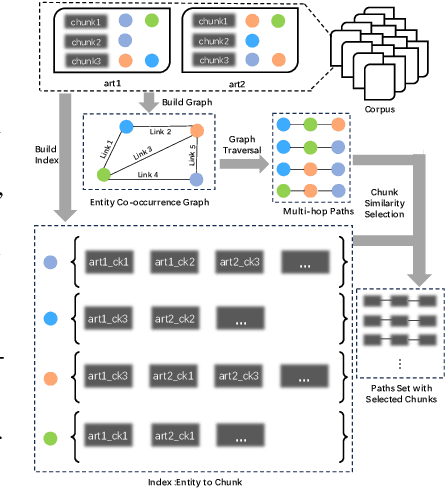

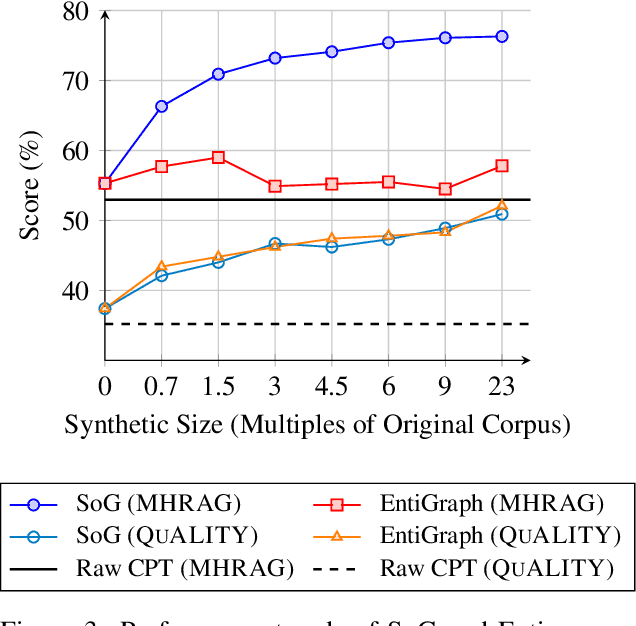
Large Language Models (LLMs) have achieved remarkable success but remain data-inefficient, especially when learning from small, specialized corpora with limited and proprietary data. Existing synthetic data generation methods for continue pre-training focus on intra-document content and overlook cross-document knowledge associations, limiting content diversity and depth. We propose Synthetic-on-Graph (SoG), a synthetic data generation framework that incorporates cross-document knowledge associations for efficient corpus expansion. SoG constructs a context graph by extracting entities and concepts from the original corpus, representing cross-document associations, and employing a graph walk strategy for knowledge-associated sampling. This enhances synthetic data diversity and coherence, enabling models to learn complex knowledge structures and handle rare knowledge. To further improve synthetic data quality, we integrate Chain-of-Thought (CoT) and Contrastive Clarifying (CC) synthetic, enhancing reasoning processes and discriminative power. Experiments show that SoG outperforms the state-of-the-art (SOTA) method in a multi-hop document Q&A dataset while performing comparably to the SOTA method on the reading comprehension task datasets, which also underscores the better generalization capability of SoG. Our work advances synthetic data generation and provides practical solutions for efficient knowledge acquisition in LLMs, especially in domains with limited data availability.
LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data
Feb 18, 2025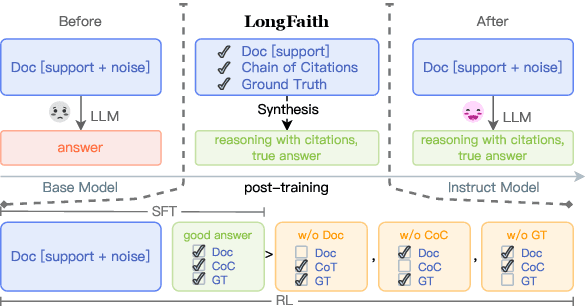
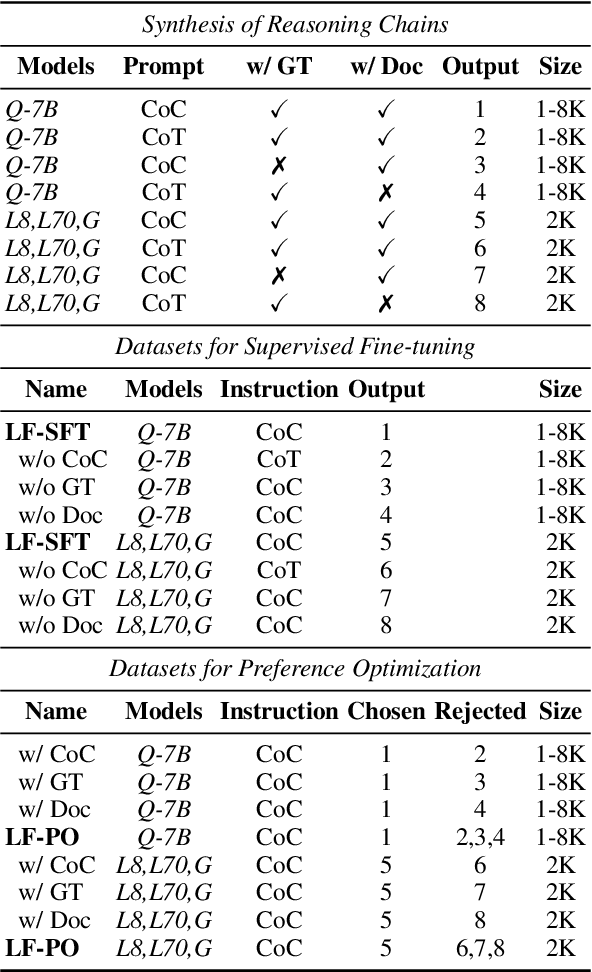
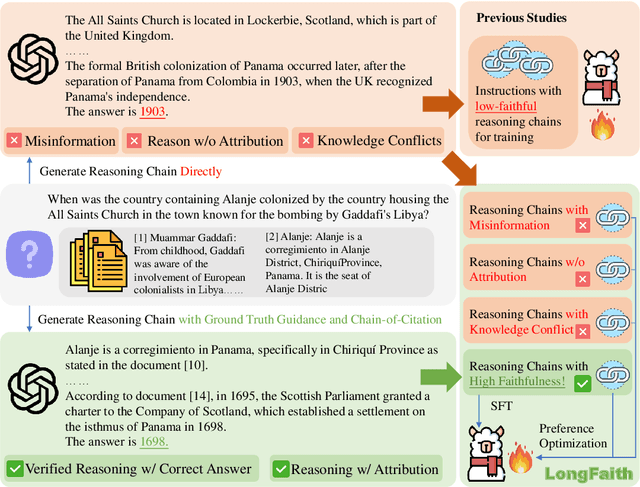
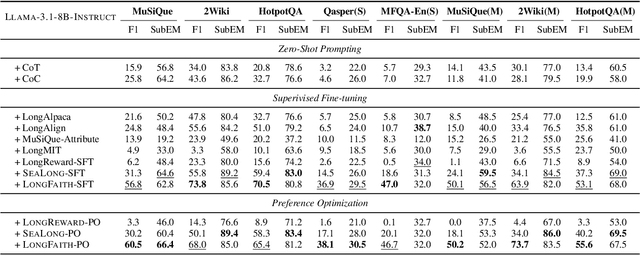
Despite the growing development of long-context large language models (LLMs), data-centric approaches relying on synthetic data have been hindered by issues related to faithfulness, which limit their effectiveness in enhancing model performance on tasks such as long-context reasoning and question answering (QA). These challenges are often exacerbated by misinformation caused by lack of verification, reasoning without attribution, and potential knowledge conflicts. We propose LongFaith, a novel pipeline for synthesizing faithful long-context reasoning instruction datasets. By integrating ground truth and citation-based reasoning prompts, we eliminate distractions and improve the accuracy of reasoning chains, thus mitigating the need for costly verification processes. We open-source two synthesized datasets, LongFaith-SFT and LongFaith-PO, which systematically address multiple dimensions of faithfulness, including verified reasoning, attribution, and contextual grounding. Extensive experiments on multi-hop reasoning datasets and LongBench demonstrate that models fine-tuned on these datasets significantly improve performance. Our ablation studies highlight the scalability and adaptability of the LongFaith pipeline, showcasing its broad applicability in developing long-context LLMs.
A Survey on LLM-as-a-Judge
Nov 23, 2024Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey of LLM-as-a-Judge, addressing the core question: How can reliable LLM-as-a-Judge systems be built? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.
STAND-Guard: A Small Task-Adaptive Content Moderation Model
Nov 07, 2024

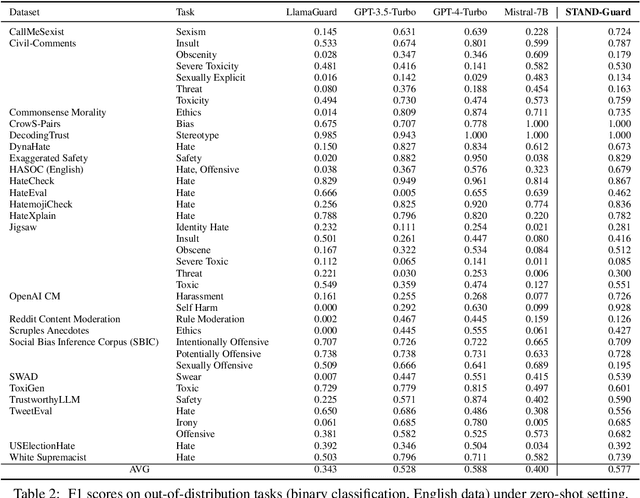

Content moderation, the process of reviewing and monitoring the safety of generated content, is important for development of welcoming online platforms and responsible large language models. Content moderation contains various tasks, each with its unique requirements tailored to specific scenarios. Therefore, it is crucial to develop a model that can be easily adapted to novel or customized content moderation tasks accurately without extensive model tuning. This paper presents STAND-GUARD, a Small Task-Adaptive coNtent moDeration model. The basic motivation is: by performing instruct tuning on various content moderation tasks, we can unleash the power of small language models (SLMs) on unseen (out-of-distribution) content moderation tasks. We also carefully study the effects of training tasks and model size on the efficacy of cross-task fine-tuning mechanism. Experiments demonstrate STAND-Guard is comparable to GPT-3.5-Turbo across over 40 public datasets, as well as proprietary datasets derived from real-world business scenarios. Remarkably, STAND-Guard achieved nearly equivalent results to GPT-4-Turbo on unseen English binary classification tasks
Think-on-Graph 2.0: Deep and Interpretable Large Language Model Reasoning with Knowledge Graph-guided Retrieval
Jul 15, 2024



Retrieval-augmented generation (RAG) has significantly advanced large language models (LLMs) by enabling dynamic information retrieval to mitigate knowledge gaps and hallucinations in generated content. However, these systems often falter with complex reasoning and consistency across diverse queries. In this work, we present Think-on-Graph 2.0, an enhanced RAG framework that aligns questions with the knowledge graph and uses it as a navigational tool, which deepens and refines the RAG paradigm for information collection and integration. The KG-guided navigation fosters deep and long-range associations to uphold logical consistency and optimize the scope of retrieval for precision and interoperability. In conjunction, factual consistency can be better ensured through semantic similarity guided by precise directives. ToG${2.0}$ not only improves the accuracy and reliability of LLMs' responses but also demonstrates the potential of hybrid structured knowledge systems to significantly advance LLM reasoning, aligning it closer to human-like performance. We conducted extensive experiments on four public datasets to demonstrate the advantages of our method compared to the baseline.
3D Gaussian Blendshapes for Head Avatar Animation
May 02, 2024We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
Leveraging Large Language Models for Relevance Judgments in Legal Case Retrieval
Mar 27, 2024Collecting relevant judgments for legal case retrieval is a challenging and time-consuming task. Accurately judging the relevance between two legal cases requires a considerable effort to read the lengthy text and a high level of domain expertise to extract Legal Facts and make juridical judgments. With the advent of advanced large language models, some recent studies have suggested that it is promising to use LLMs for relevance judgment. Nonetheless, the method of employing a general large language model for reliable relevance judgments in legal case retrieval is yet to be thoroughly explored. To fill this research gap, we devise a novel few-shot workflow tailored to the relevant judgment of legal cases. The proposed workflow breaks down the annotation process into a series of stages, imitating the process employed by human annotators and enabling a flexible integration of expert reasoning to enhance the accuracy of relevance judgments. By comparing the relevance judgments of LLMs and human experts, we empirically show that we can obtain reliable relevance judgments with the proposed workflow. Furthermore, we demonstrate the capacity to augment existing legal case retrieval models through the synthesis of data generated by the large language model.