 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Distance: A Novel Metric for Directed Fuzzing with Large Language Models
Dec 19, 2025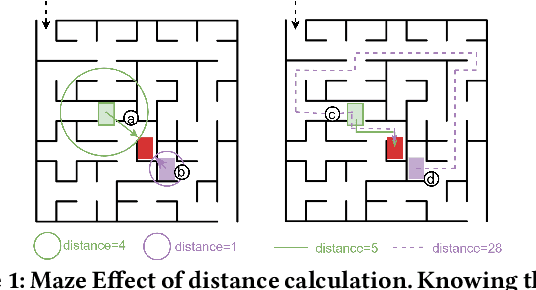
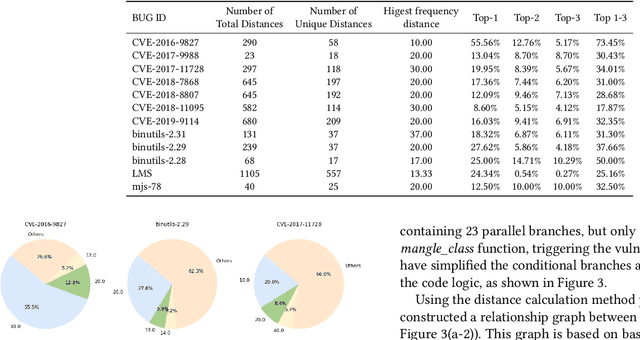
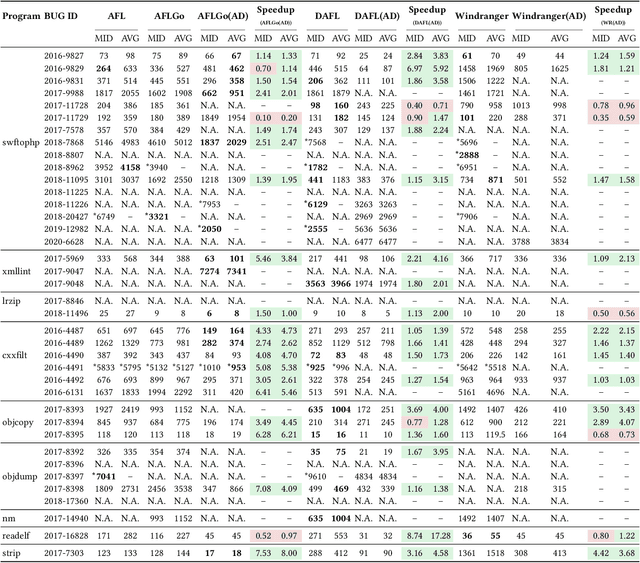
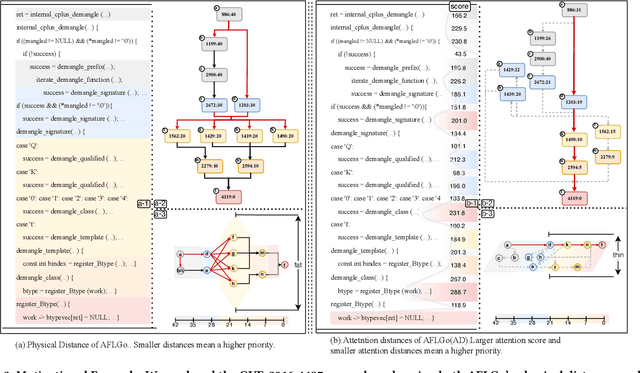
In the domain of software security testing, Directed Grey-Box Fuzzing (DGF) has garnered widespread attention for its efficient target localization and excellent detection performance. However, existing approaches measure only the physical distance between seed execution paths and target locations, overlooking logical relationships among code segments. This omission can yield redundant or misleading guidance in complex binaries, weakening DGF's real-world effectiveness. To address this, we introduce \textbf{attention distance}, a novel metric that leverages a large language model's contextual analysis to compute attention scores between code elements and reveal their intrinsic connections. Under the same AFLGo configuration -- without altering any fuzzing components other than the distance metric -- replacing physical distances with attention distances across 38 real vulnerability reproduction experiments delivers a \textbf{3.43$\times$} average increase in testing efficiency over the traditional method. Compared to state-of-the-art directed fuzzers DAFL and WindRanger, our approach achieves \textbf{2.89$\times$} and \textbf{7.13$\times$} improvements, respectively. To further validate the generalizability of attention distance, we integrate it into DAFL and WindRanger, where it also consistently enhances their original performance. All related code and datasets are publicly available at https://github.com/TheBinKing/Attention\_Distance.git.
InfiJanice: Joint Analysis and In-situ Correction Engine for Quantization-Induced Math Degradation in Large Language Models
May 16, 2025



Large Language Models (LLMs) have demonstrated impressive performance on complex reasoning benchmarks such as GSM8K, MATH, and AIME. However, the substantial computational demands of these tasks pose significant challenges for real-world deployment. Model quantization has emerged as a promising approach to reduce memory footprint and inference latency by representing weights and activations with lower bit-widths. In this work, we conduct a comprehensive study of mainstream quantization methods(e.g., AWQ, GPTQ, SmoothQuant) on the most popular open-sourced models (e.g., Qwen2.5, LLaMA3 series), and reveal that quantization can degrade mathematical reasoning accuracy by up to 69.81%. To better understand this degradation, we develop an automated assignment and judgment pipeline that qualitatively categorizes failures into four error types and quantitatively identifies the most impacted reasoning capabilities. Building on these findings, we employ an automated data-curation pipeline to construct a compact "Silver Bullet" datasets. Training a quantized model on as few as 332 carefully selected examples for just 3-5 minutes on a single GPU is enough to restore its reasoning accuracy to match that of the full-precision baseline.
PiCo: Jailbreaking Multimodal Large Language Models via $\textbf{Pi}$ctorial $\textbf{Co}$de Contextualization
Apr 02, 2025Multimodal Large Language Models (MLLMs), which integrate vision and other modalities into Large Language Models (LLMs), significantly enhance AI capabilities but also introduce new security vulnerabilities. By exploiting the vulnerabilities of the visual modality and the long-tail distribution characteristic of code training data, we present PiCo, a novel jailbreaking framework designed to progressively bypass multi-tiered defense mechanisms in advanced MLLMs. PiCo employs a tier-by-tier jailbreak strategy, using token-level typographic attacks to evade input filtering and embedding harmful intent within programming context instructions to bypass runtime monitoring. To comprehensively assess the impact of attacks, a new evaluation metric is further proposed to assess both the toxicity and helpfulness of model outputs post-attack. By embedding harmful intent within code-style visual instructions, PiCo achieves an average Attack Success Rate (ASR) of 84.13% on Gemini-Pro Vision and 52.66% on GPT-4, surpassing previous methods. Experimental results highlight the critical gaps in current defenses, underscoring the need for more robust strategies to secure advanced MLLMs.
DBF-UNet: A Two-Stage Framework for Carotid Artery Segmentation with Pseudo-Label Generation
Apr 01, 2025



Medical image analysis faces significant challenges due to limited annotation data, particularly in three-dimensional carotid artery segmentation tasks, where existing datasets exhibit spatially discontinuous slice annotations with only a small portion of expert-labeled slices in complete 3D volumetric data. To address this challenge, we propose a two-stage segmentation framework. First, we construct continuous vessel centerlines by interpolating between annotated slice centroids and propagate labels along these centerlines to generate interpolated annotations for unlabeled slices. The slices with expert annotations are used for fine-tuning SAM-Med2D, while the interpolated labels on unlabeled slices serve as prompts to guide segmentation during inference. In the second stage, we propose a novel Dense Bidirectional Feature Fusion UNet (DBF-UNet). This lightweight architecture achieves precise segmentation of complete 3D vascular structures. The network incorporates bidirectional feature fusion in the encoder and integrates multi-scale feature aggregation with dense connectivity for effective feature reuse. Experimental validation on public datasets demonstrates that our proposed method effectively addresses the sparse annotation challenge in carotid artery segmentation while achieving superior performance compared to existing approaches. The source code is available at https://github.com/Haoxuanli-Thu/DBF-UNet.
LongFaith: Enhancing Long-Context Reasoning in LLMs with Faithful Synthetic Data
Feb 18, 2025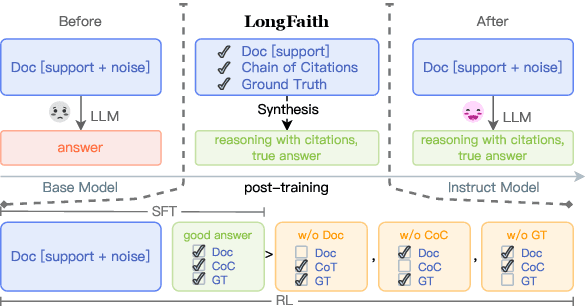
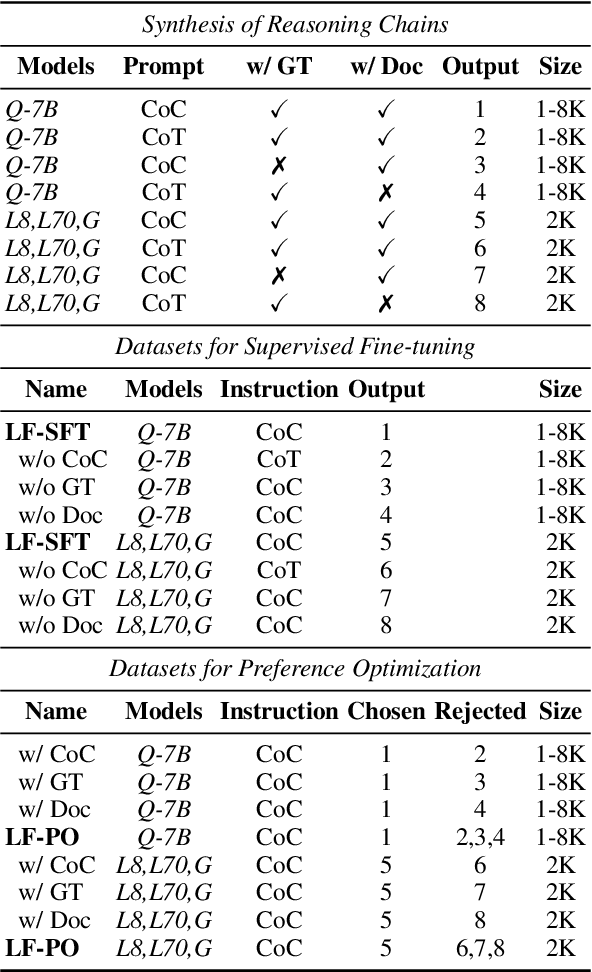
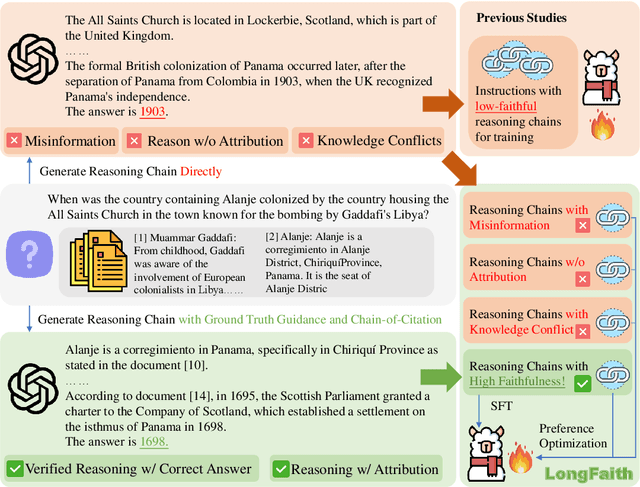
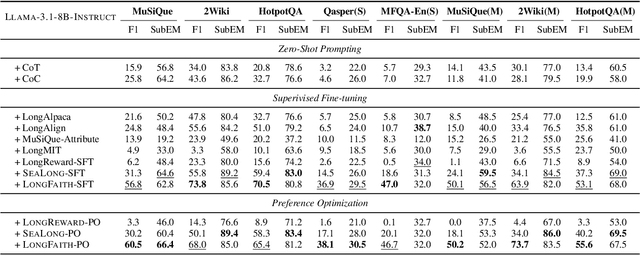
Despite the growing development of long-context large language models (LLMs), data-centric approaches relying on synthetic data have been hindered by issues related to faithfulness, which limit their effectiveness in enhancing model performance on tasks such as long-context reasoning and question answering (QA). These challenges are often exacerbated by misinformation caused by lack of verification, reasoning without attribution, and potential knowledge conflicts. We propose LongFaith, a novel pipeline for synthesizing faithful long-context reasoning instruction datasets. By integrating ground truth and citation-based reasoning prompts, we eliminate distractions and improve the accuracy of reasoning chains, thus mitigating the need for costly verification processes. We open-source two synthesized datasets, LongFaith-SFT and LongFaith-PO, which systematically address multiple dimensions of faithfulness, including verified reasoning, attribution, and contextual grounding. Extensive experiments on multi-hop reasoning datasets and LongBench demonstrate that models fine-tuned on these datasets significantly improve performance. Our ablation studies highlight the scalability and adaptability of the LongFaith pipeline, showcasing its broad applicability in developing long-context LLMs.