 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-Slot: Unsupervised Anatomical Factorization for Homologous Bilateral Reasoning in Retinal Diagnosis
May 13, 2026Retinal diagnosis is inherently bilateral: clinicians compare homologous structures across eyes (e.g., optic disc asymmetry), yet most deep models operate on monocular representations. We investigate whether explicit structural correspondence improves diagnosis, and propose Anatomy-Slot to operationalize this hypothesis. Anatomy-Slot introduces an unsupervised anatomical bottleneck by decomposing patch tokens into slots and aligning slots across eyes via bidirectional cross-attention. On ODIR-5K with $n=10$ seeds, the method improves AUC by 4.2% over a matched ViT-L baseline (95% CIs; Wilcoxon signed-rank test, $W=0$, $p=0.002$). Pairing disruption and stress testing under Gaussian noise provide controlled tests of correspondence dependence and robustness under corruption. We further report quantitative optic disc grounding on REFUGE and cross-attention localization analysis.
DermoGPT: Open Weights and Open Data for Morphology-Grounded Dermatological Reasoning MLLMs
Jan 05, 2026Multimodal Large Language Models (MLLMs) show promise for medical applications, yet progress in dermatology lags due to limited training data, narrow task coverage, and lack of clinically-grounded supervision that mirrors expert diagnostic workflows. We present a comprehensive framework to address these gaps. First, we introduce DermoInstruct, a large-scale morphology-anchored instruction corpus comprising 211,243 images and 772,675 trajectories across five task formats, capturing the complete diagnostic pipeline from morphological observation and clinical reasoning to final diagnosis. Second, we establish DermoBench, a rigorous benchmark evaluating 11 tasks across four clinical axes: Morphology, Diagnosis, Reasoning, and Fairness, including a challenging subset of 3,600 expert-verified open-ended instances and human performance baselines. Third, we develop DermoGPT, a dermatology reasoning MLLM trained via supervised fine-tuning followed by our Morphologically-Anchored Visual-Inference-Consistent (MAVIC) reinforcement learning objective, which enforces consistency between visual observations and diagnostic conclusions. At inference, we deploy Confidence-Consistency Test-time adaptation (CCT) for robust predictions. Experiments show DermoGPT significantly outperforms 16 representative baselines across all axes, achieving state-of-the-art performance while substantially narrowing the human-AI gap. DermoInstruct, DermoBench and DermoGPT will be made publicly available at https://github.com/mendicant04/DermoGPT upon acceptance.
ASK: Adaptive Self-improving Knowledge Framework for Audio Text Retrieval
Dec 11, 2025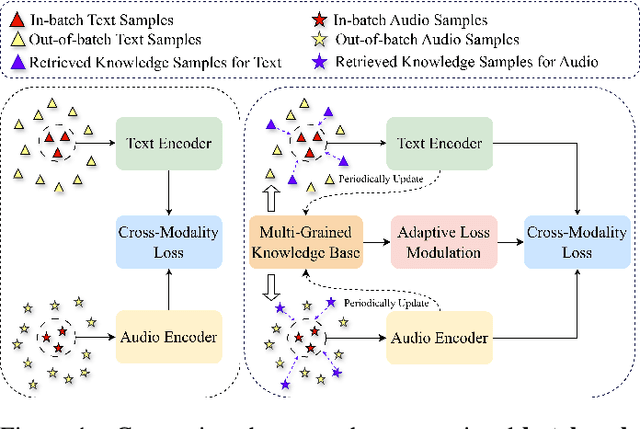
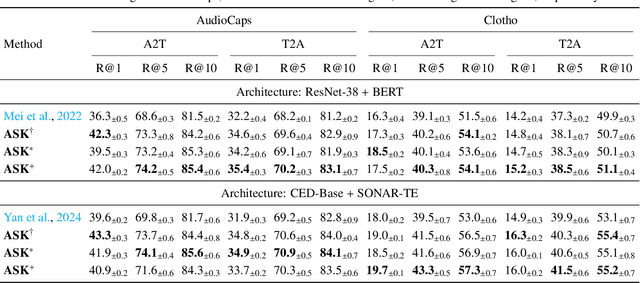
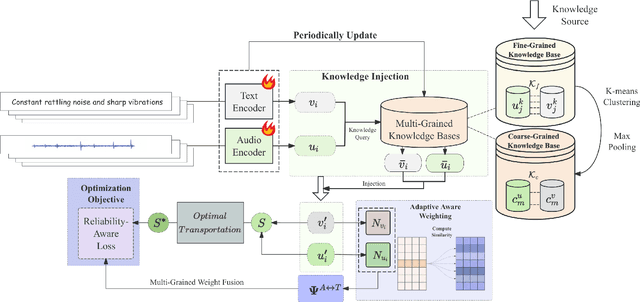
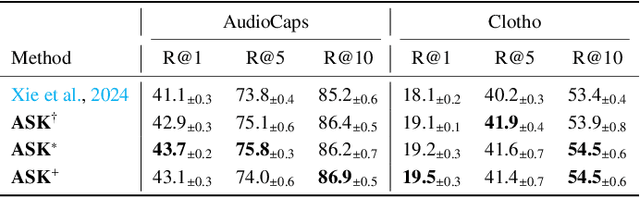
The dominant paradigm for Audio-Text Retrieval (ATR) relies on mini-batch-based contrastive learning. This process, however, is inherently limited by what we formalize as the Gradient Locality Bottleneck (GLB), which structurally prevents models from leveraging out-of-batch knowledge and thus impairs fine-grained and long-tail learning. While external knowledge-enhanced methods can alleviate the GLB, we identify a critical, unaddressed side effect: the Representation-Drift Mismatch (RDM), where a static knowledge base becomes progressively misaligned with the evolving model, turning guidance into noise. To address this dual challenge, we propose the Adaptive Self-improving Knowledge (ASK) framework, a model-agnostic, plug-and-play solution. ASK breaks the GLB via multi-grained knowledge injection, systematically mitigates RDM through dynamic knowledge refinement, and introduces a novel adaptive reliability weighting scheme to ensure consistent knowledge contributes to optimization. Experimental results on two benchmark datasets with superior, state-of-the-art performance justify the efficacy of our proposed ASK framework.
PiCo: Jailbreaking Multimodal Large Language Models via $\textbf{Pi}$ctorial $\textbf{Co}$de Contextualization
Apr 02, 2025Multimodal Large Language Models (MLLMs), which integrate vision and other modalities into Large Language Models (LLMs), significantly enhance AI capabilities but also introduce new security vulnerabilities. By exploiting the vulnerabilities of the visual modality and the long-tail distribution characteristic of code training data, we present PiCo, a novel jailbreaking framework designed to progressively bypass multi-tiered defense mechanisms in advanced MLLMs. PiCo employs a tier-by-tier jailbreak strategy, using token-level typographic attacks to evade input filtering and embedding harmful intent within programming context instructions to bypass runtime monitoring. To comprehensively assess the impact of attacks, a new evaluation metric is further proposed to assess both the toxicity and helpfulness of model outputs post-attack. By embedding harmful intent within code-style visual instructions, PiCo achieves an average Attack Success Rate (ASR) of 84.13% on Gemini-Pro Vision and 52.66% on GPT-4, surpassing previous methods. Experimental results highlight the critical gaps in current defenses, underscoring the need for more robust strategies to secure advanced MLLMs.
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025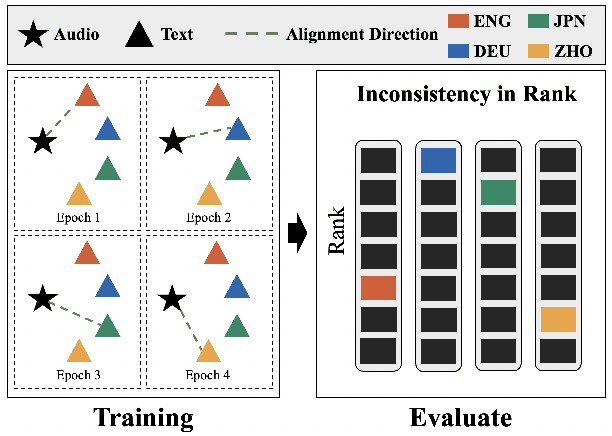
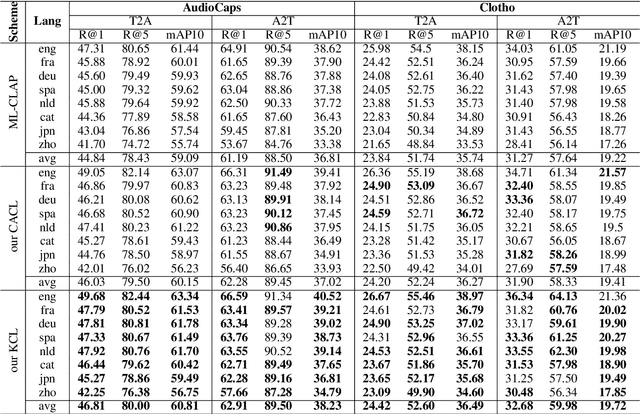
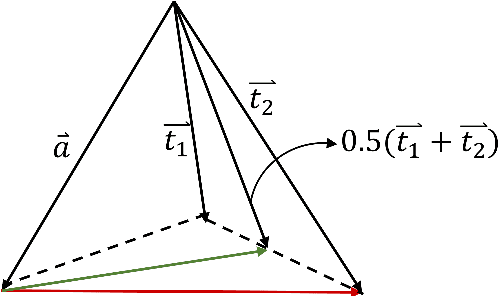
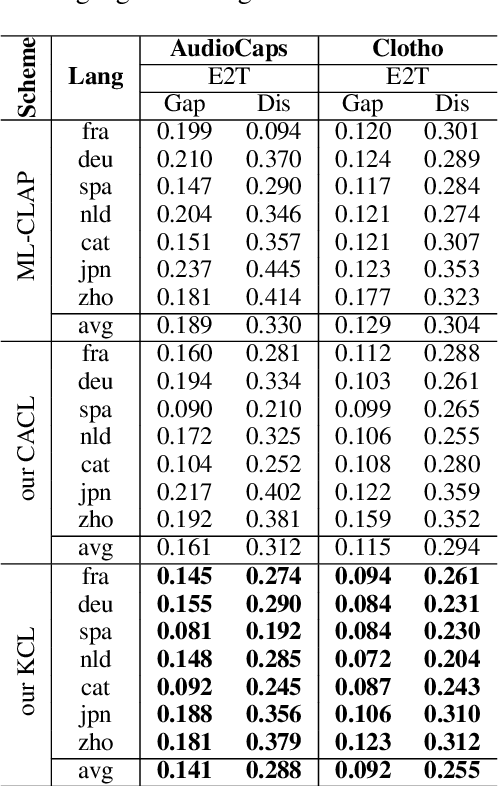
Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.
Do we really have to filter out random noise in pre-training data for language models?
Feb 10, 2025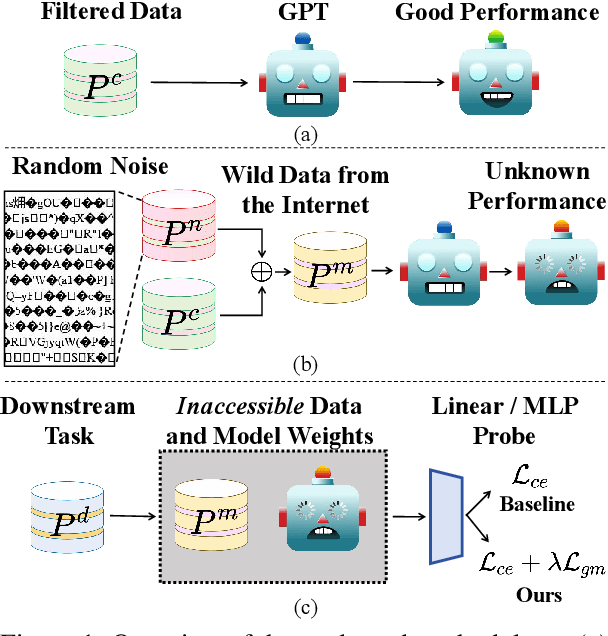



Web-scale pre-training datasets are the cornerstone of LLMs' success. However, text data curated from the internet inevitably contains random noise caused by decoding errors or unregulated web content. In contrast to previous works that focus on low quality or synthetic data, our study \textbf{provides the first systematic investigation into such random noise through a cohesive ``What-Why-How'' framework.} Surprisingly, we observed that the resulting increase in next-token prediction (NTP) loss was significantly lower than the proportion of random noise. We provide a theoretical justification for this phenomenon, which also elucidates the success of multilingual models. On the other hand, experiments show that the model's performance in downstream tasks is not based solely on the NTP loss, which means that random noise may result in degraded downstream performance. To address the potential adverse effects, we introduce a novel plug-and-play Local Gradient Matching loss, which explicitly enhances the denoising capability of the downstream task head by aligning the gradient of normal and perturbed features without requiring knowledge of the model's parameters. Additional experiments on 8 language and 14 vision benchmarks further validate its effectiveness.
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
Jan 21, 2025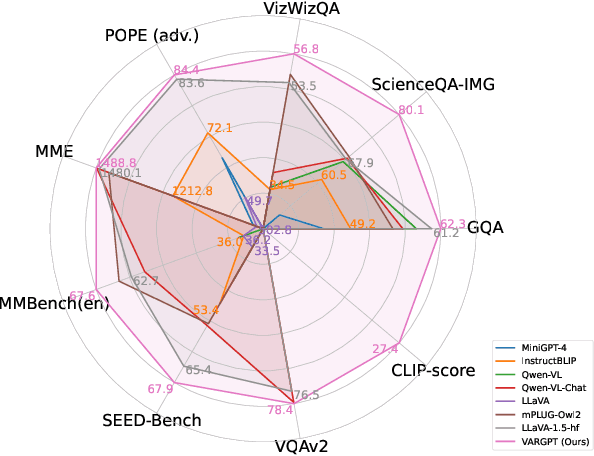
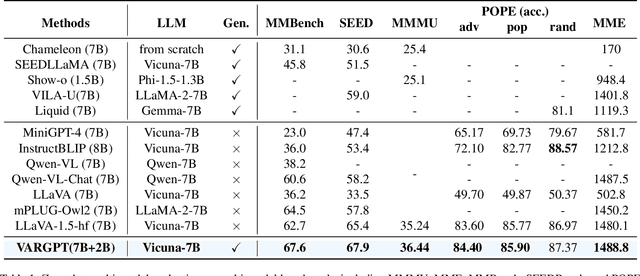

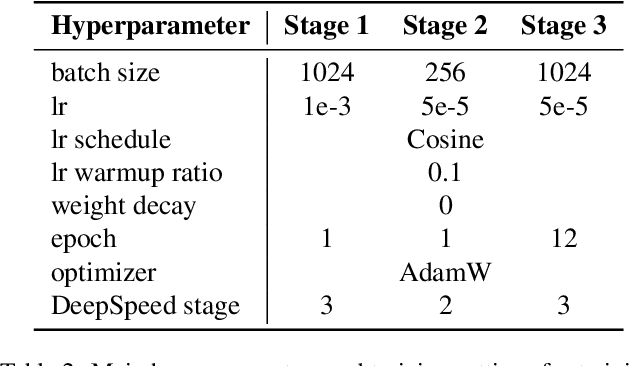
We present VARGPT, a novel multimodal large language model (MLLM) that unifies visual understanding and generation within a single autoregressive framework. VARGPT employs a next-token prediction paradigm for visual understanding and a next-scale prediction paradigm for visual autoregressive generation. VARGPT innovatively extends the LLaVA architecture, achieving efficient scale-wise autoregressive visual generation within MLLMs while seamlessly accommodating mixed-modal input and output within a single model framework. Our VARGPT undergoes a three-stage unified training process on specially curated datasets, comprising a pre-training phase and two mixed visual instruction-tuning phases. The unified training strategy are designed to achieve alignment between visual and textual features, enhance instruction following for both understanding and generation, and improve visual generation quality, respectively. Despite its LLAVA-based architecture for multimodel understanding, VARGPT significantly outperforms LLaVA-1.5 across various vision-centric benchmarks, such as visual question-answering and reasoning tasks. Notably, VARGPT naturally supports capabilities in autoregressive visual generation and instruction-to-image synthesis, showcasing its versatility in both visual understanding and generation tasks. Project page is at: \url{https://vargpt-1.github.io/}
FedSOV: Federated Model Secure Ownership Verification with Unforgeable Signature
May 10, 2023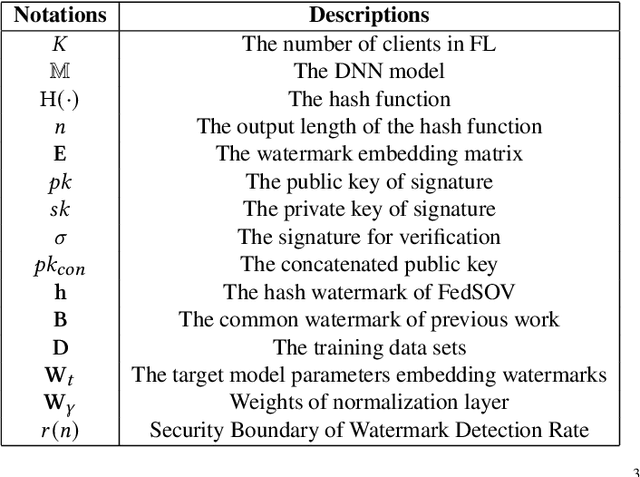
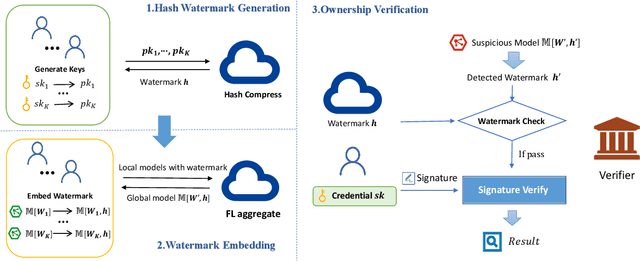
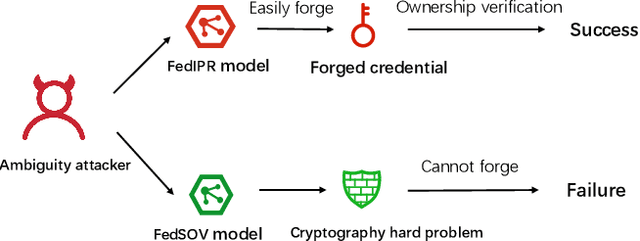
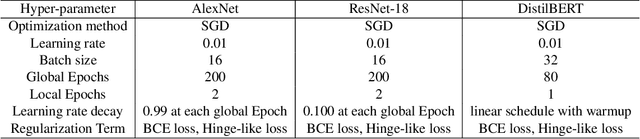
Federated learning allows multiple parties to collaborate in learning a global model without revealing private data. The high cost of training and the significant value of the global model necessitates the need for ownership verification of federated learning. However, the existing ownership verification schemes in federated learning suffer from several limitations, such as inadequate support for a large number of clients and vulnerability to ambiguity attacks. To address these limitations, we propose a cryptographic signature-based federated learning model ownership verification scheme named FedSOV. FedSOV allows numerous clients to embed their ownership credentials and verify ownership using unforgeable digital signatures. The scheme provides theoretical resistance to ambiguity attacks with the unforgeability of the signature. Experimental results on computer vision and natural language processing tasks demonstrate that FedSOV is an effective federated model ownership verification scheme enhanced with provable cryptographic security.
FedZKP: Federated Model Ownership Verification with Zero-knowledge Proof
May 10, 2023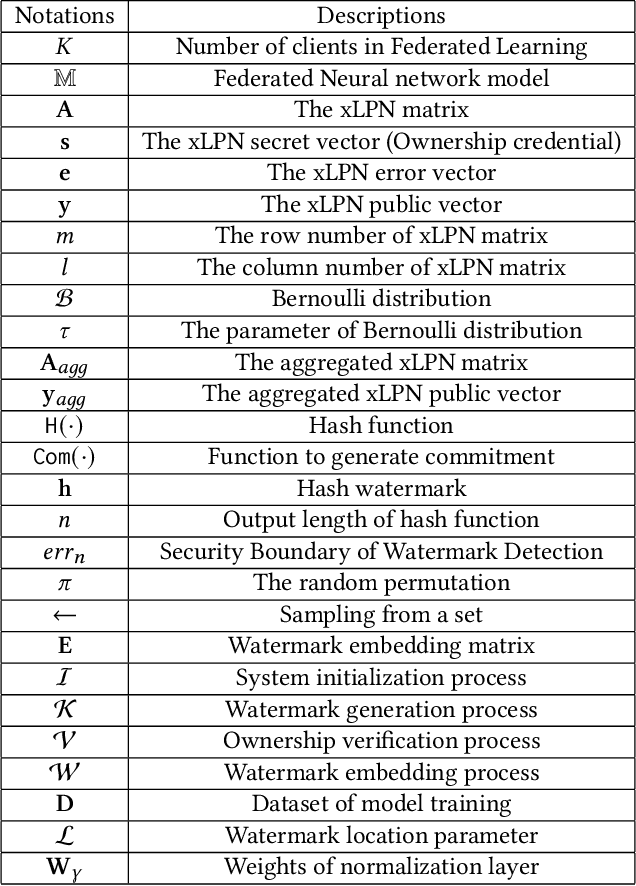


Federated learning (FL) allows multiple parties to cooperatively learn a federated model without sharing private data with each other. The need of protecting such federated models from being plagiarized or misused, therefore, motivates us to propose a provable secure model ownership verification scheme using zero-knowledge proof, named FedZKP. It is shown that the FedZKP scheme without disclosing credentials is guaranteed to defeat a variety of existing and potential attacks. Both theoretical analysis and empirical studies demonstrate the security of FedZKP in the sense that the probability for attackers to breach the proposed FedZKP is negligible. Moreover, extensive experimental results confirm the fidelity and robustness of our scheme.