 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Visual Cues: CoT-Enhanced Reasoning for Semi-supervised Medical Image Segmentation
Jun 16, 2026Semi-supervised medical image segmentation has emerged as a dominant research problem in medical image analysis, mitigating annotation scarcity by leveraging consistency regularization on unlabeled data. However, existing approaches operate predominantly via visual pattern matching, relying heavily on pixel-level similarities. This visual-centric dependency often falters in clinical scenarios characterized by the visual-semantic mismatch, where visually similar lesions warrant distinct diagnostic conclusions, thus failing to capture the underlying diagnostic logic used by experts. To address this, we move beyond visual cues and propose CERS (CoT-Enhanced Reasoning Segmentation), a framework that integrates Chain-of-Thought (CoT) reasoning to distinguish pathologically distinct cases. Specifically, we construct a knowledge pool enriched with linguistic reasoning descriptions generated by large language models (LLMs). A semantic-aware reference selection strategy is introduced to identify historical evidence, filtering candidates first by morphology, and then refining them via CoT consistency to eliminate hard negatives. Furthermore, a multi-scale coordinate attention module (MCAM) is designed to effectively fuse this reasoning-derived context into the decoding process. Extensive experiments demonstrate the superiority of CERS against state-of-the-art approaches, particularly in resolving boundary ambiguities and semantic inconsistencies. The code is available at https://github.com/cymasuna/CERS.
U-HNO: A U-shaped Hybrid Neural Operator with Sparse-Point Adaptive Routing for Non-stationary PDE Dynamics
May 13, 2026Solutions to many partial differential equations (PDEs) display coexisting smooth global transport and localized sharp features within a single trajectory: shock fronts, thin interfaces, and concentrated high-frequency content sit on top of slowly varying backgrounds. This poses a challenge for neural operators: Fourier-based architectures mix nonlocal interactions efficiently but tend to under-resolve localized non-smooth features, whereas spatially local architectures recover fine detail at the cost of long-range propagation and rollout stability. Existing hybrid operators paper over this tension with a fixed, spatially uniform fusion that forces the same trade-off everywhere. We propose U-HNO, a U-shaped hybrid neural operator whose central design is Sparse-Point Adaptive Routing (SPAR): at every spatial location, a per-pixel hard mask selects whether the global Fourier branch or the local multi-scale Gaussian branch should dominate, and the sparsity ratio is a function of the local contrast of the routing signal, so smooth and shock-aligned regions receive different mixtures of global and local computation. SPAR is embedded in a hierarchical encoder-bottleneck-decoder backbone with skip connections so that the dual branches and the gate operate at every resolution. Training combines pointwise supervision with a finite-difference H^1 gradient term and a band-wise spectral consistency regularizer. Across benchmarks spanning 1D Burgers, Kuramoto-Sivashinsky, KdV, 2D advection, Allen-Cahn, Navier-Stokes, Darcy flow, and 3D transonic compressible Navier-Stokes from PDEBench, U-HNO achieves state-of-the-art rollout accuracy on the majority of tasks in both relative L^2 and H^1 metrics, with the largest gains on problems dominated by sharp localized features. Ablations show that removing any single component substantially degrades rollout error.
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
Apr 06, 2026Extended reasoning in large language models (LLMs) creates severe KV cache memory bottlenecks. Leading KV cache compression methods estimate KV importance using attention scores from recent post-RoPE queries. However, queries rotate with position during RoPE, making representative queries very few, leading to poor top-key selection and unstable reasoning. To avoid this issue, we turn to the pre-RoPE space, where we observe that Q and K vectors are highly concentrated around fixed non-zero centers and remain stable across positions -- Q/K concentration. We show that this concentration causes queries to preferentially attend to keys at specific distances (e.g., nearest keys), with the centers determining which distances are preferred via a trigonometric series. Based on this, we propose TriAttention to estimate key importance by leveraging these centers. Via the trigonometric series, we use the distance preference characterized by these centers to score keys according to their positions, and also leverage Q/K norms as an additional signal for importance estimation. On AIME25 with 32K-token generation, TriAttention matches Full Attention reasoning accuracy while achieving 2.5x higher throughput or 10.7x KV memory reduction, whereas leading baselines achieve only about half the accuracy at the same efficiency. TriAttention enables OpenClaw deployment on a single consumer GPU, where long context would otherwise cause out-of-memory with Full Attention.
ASK: Adaptive Self-improving Knowledge Framework for Audio Text Retrieval
Dec 11, 2025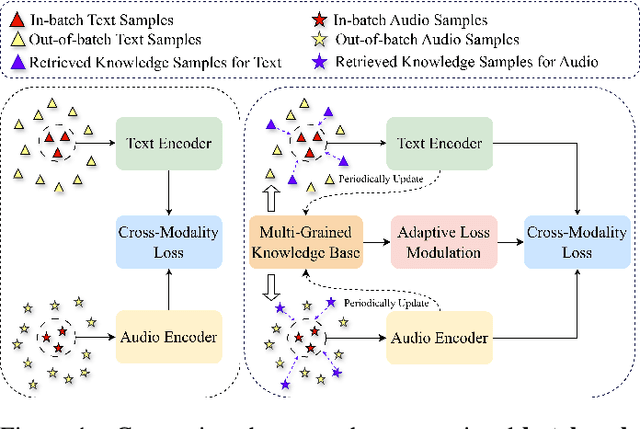
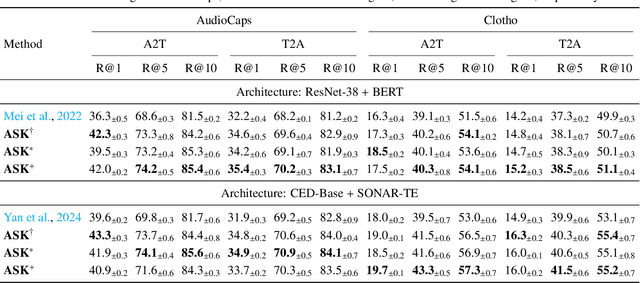
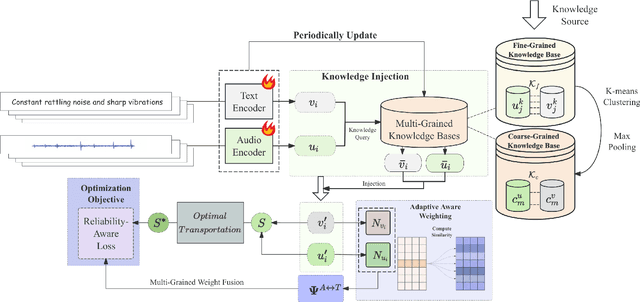
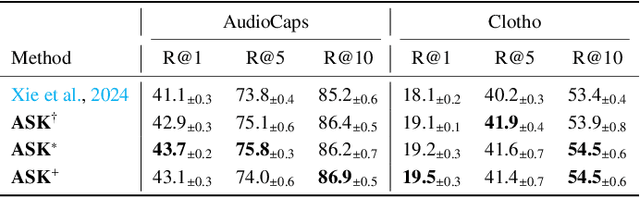
The dominant paradigm for Audio-Text Retrieval (ATR) relies on mini-batch-based contrastive learning. This process, however, is inherently limited by what we formalize as the Gradient Locality Bottleneck (GLB), which structurally prevents models from leveraging out-of-batch knowledge and thus impairs fine-grained and long-tail learning. While external knowledge-enhanced methods can alleviate the GLB, we identify a critical, unaddressed side effect: the Representation-Drift Mismatch (RDM), where a static knowledge base becomes progressively misaligned with the evolving model, turning guidance into noise. To address this dual challenge, we propose the Adaptive Self-improving Knowledge (ASK) framework, a model-agnostic, plug-and-play solution. ASK breaks the GLB via multi-grained knowledge injection, systematically mitigates RDM through dynamic knowledge refinement, and introduces a novel adaptive reliability weighting scheme to ensure consistent knowledge contributes to optimization. Experimental results on two benchmark datasets with superior, state-of-the-art performance justify the efficacy of our proposed ASK framework.
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025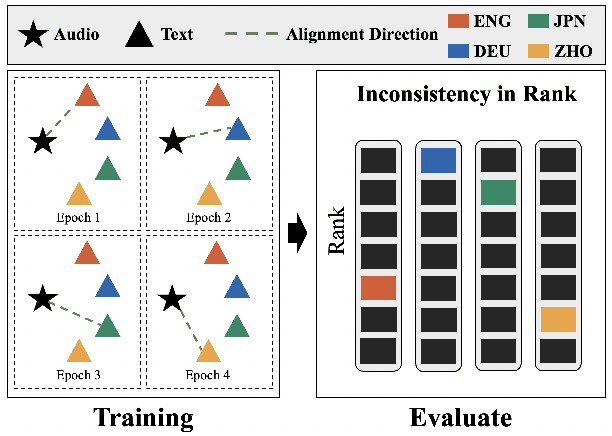
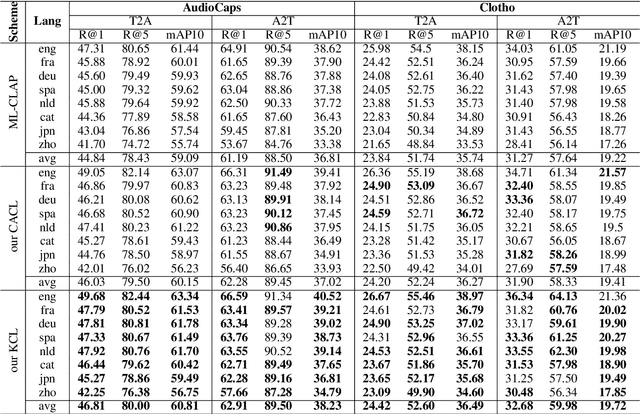
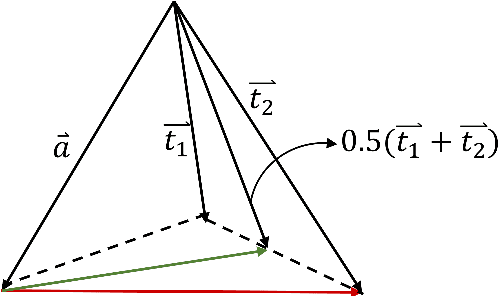
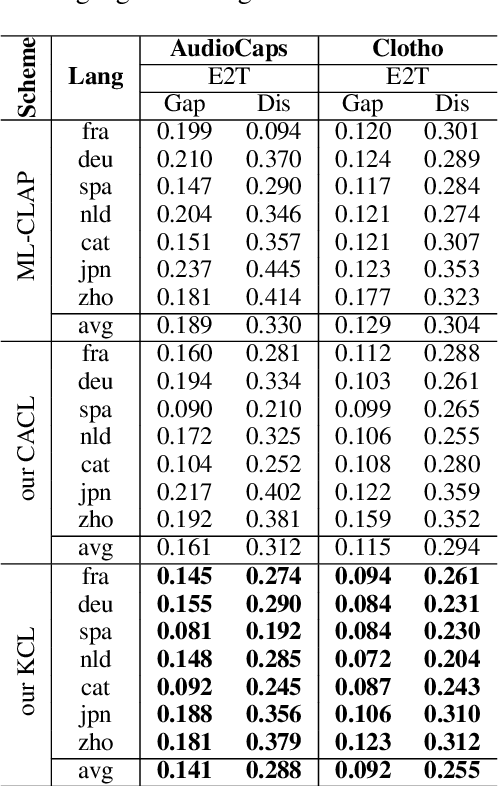
Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.
Do we really have to filter out random noise in pre-training data for language models?
Feb 10, 2025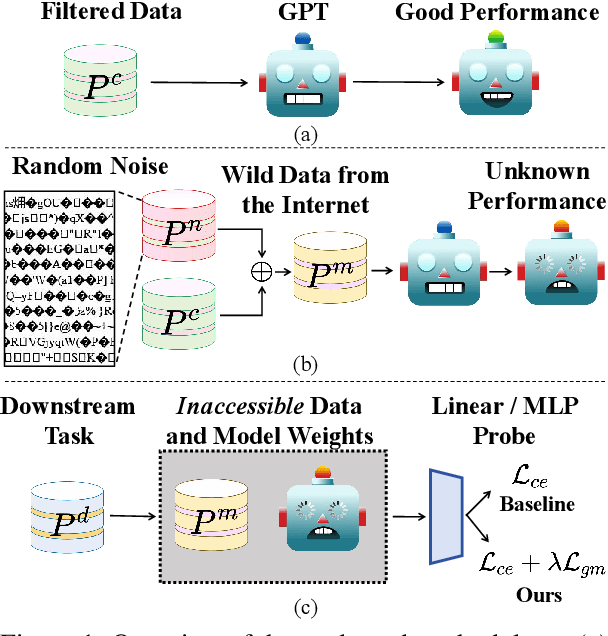



Web-scale pre-training datasets are the cornerstone of LLMs' success. However, text data curated from the internet inevitably contains random noise caused by decoding errors or unregulated web content. In contrast to previous works that focus on low quality or synthetic data, our study \textbf{provides the first systematic investigation into such random noise through a cohesive ``What-Why-How'' framework.} Surprisingly, we observed that the resulting increase in next-token prediction (NTP) loss was significantly lower than the proportion of random noise. We provide a theoretical justification for this phenomenon, which also elucidates the success of multilingual models. On the other hand, experiments show that the model's performance in downstream tasks is not based solely on the NTP loss, which means that random noise may result in degraded downstream performance. To address the potential adverse effects, we introduce a novel plug-and-play Local Gradient Matching loss, which explicitly enhances the denoising capability of the downstream task head by aligning the gradient of normal and perturbed features without requiring knowledge of the model's parameters. Additional experiments on 8 language and 14 vision benchmarks further validate its effectiveness.
VARGPT: Unified Understanding and Generation in a Visual Autoregressive Multimodal Large Language Model
Jan 21, 2025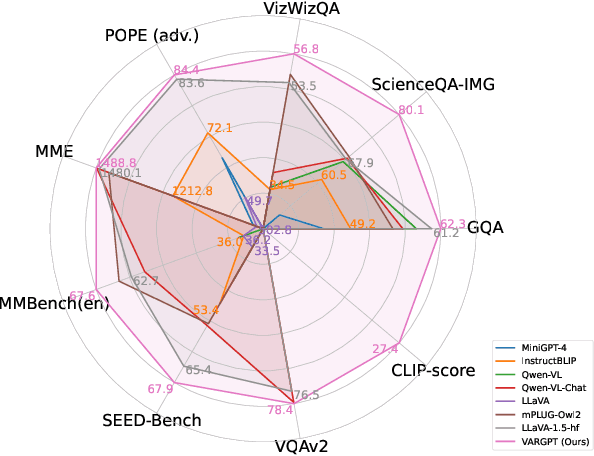
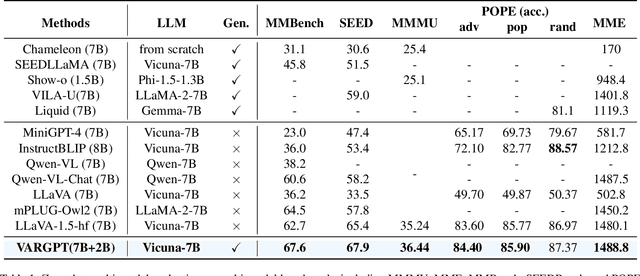

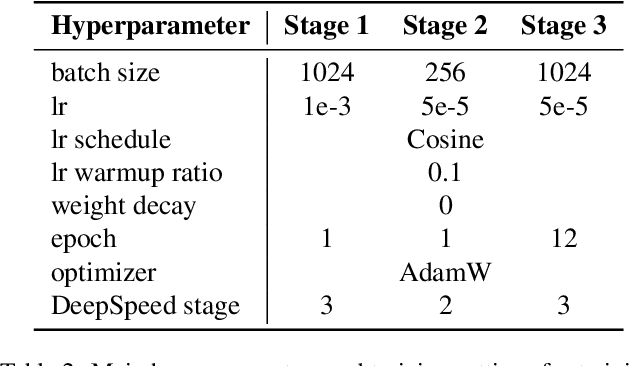
We present VARGPT, a novel multimodal large language model (MLLM) that unifies visual understanding and generation within a single autoregressive framework. VARGPT employs a next-token prediction paradigm for visual understanding and a next-scale prediction paradigm for visual autoregressive generation. VARGPT innovatively extends the LLaVA architecture, achieving efficient scale-wise autoregressive visual generation within MLLMs while seamlessly accommodating mixed-modal input and output within a single model framework. Our VARGPT undergoes a three-stage unified training process on specially curated datasets, comprising a pre-training phase and two mixed visual instruction-tuning phases. The unified training strategy are designed to achieve alignment between visual and textual features, enhance instruction following for both understanding and generation, and improve visual generation quality, respectively. Despite its LLAVA-based architecture for multimodel understanding, VARGPT significantly outperforms LLaVA-1.5 across various vision-centric benchmarks, such as visual question-answering and reasoning tasks. Notably, VARGPT naturally supports capabilities in autoregressive visual generation and instruction-to-image synthesis, showcasing its versatility in both visual understanding and generation tasks. Project page is at: \url{https://vargpt-1.github.io/}
VASparse: Towards Efficient Visual Hallucination Mitigation for Large Vision-Language Model via Visual-Aware Sparsification
Jan 11, 2025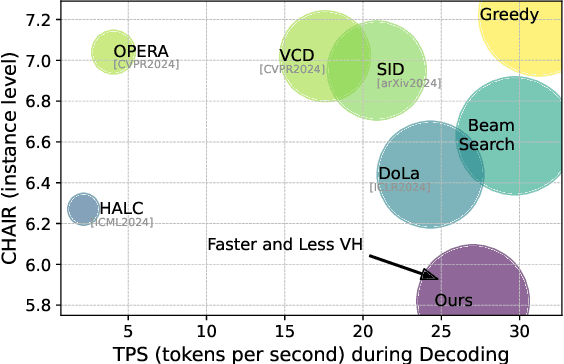



Large Vision-Language Models (LVLMs) may produce outputs that are unfaithful to reality, also known as visual hallucinations (VH), which significantly impedes their real-world usage. To alleviate VH, various decoding strategies have been proposed to enhance visual information. However, many of these methods may require secondary decoding and rollback, which significantly reduces inference speed. In this work, we propose an efficient plug-and-play decoding algorithm via Visual-Aware Sparsification (VASparse) from the perspective of token sparsity for mitigating VH. VASparse is inspired by empirical observations: (1) the sparse activation of attention in LVLMs, and (2) visual-agnostic tokens sparsification exacerbates VH. Based on these insights, we propose a novel token sparsification strategy that balances efficiency and trustworthiness. Specifically, VASparse implements a visual-aware token selection strategy during decoding to reduce redundant tokens while preserving visual context effectively. Additionally, we innovatively introduce a sparse-based visual contrastive decoding method to recalibrate the distribution of hallucinated outputs without the time overhead associated with secondary decoding. Subsequently, VASparse recalibrates attention scores to penalize attention sinking of LVLMs towards text tokens. Extensive experiments across four popular benchmarks confirm the effectiveness of VASparse in mitigating VH across different LVLM families without requiring additional training or post-processing. Impressively, VASparse achieves state-of-the-art performance for mitigating VH while maintaining competitive decoding speed. Code is available at https://github.com/mengchuang123/VASparse-github.
SimTxtSeg: Weakly-Supervised Medical Image Segmentation with Simple Text Cues
Jun 27, 2024



Weakly-supervised medical image segmentation is a challenging task that aims to reduce the annotation cost while keep the segmentation performance. In this paper, we present a novel framework, SimTxtSeg, that leverages simple text cues to generate high-quality pseudo-labels and study the cross-modal fusion in training segmentation models, simultaneously. Our contribution consists of two key components: an effective Textual-to-Visual Cue Converter that produces visual prompts from text prompts on medical images, and a text-guided segmentation model with Text-Vision Hybrid Attention that fuses text and image features. We evaluate our framework on two medical image segmentation tasks: colonic polyp segmentation and MRI brain tumor segmentation, and achieve consistent state-of-the-art performance.
Joint End-to-End Image Compression and Denoising: Leveraging Contrastive Learning and Multi-Scale Self-ONNs
Feb 08, 2024



Noisy images are a challenge to image compression algorithms due to the inherent difficulty of compressing noise. As noise cannot easily be discerned from image details, such as high-frequency signals, its presence leads to extra bits needed for compression. Since the emerging learned image compression paradigm enables end-to-end optimization of codecs, recent efforts were made to integrate denoising into the compression model, relying on clean image features to guide denoising. However, these methods exhibit suboptimal performance under high noise levels, lacking the capability to generalize across diverse noise types. In this paper, we propose a novel method integrating a multi-scale denoiser comprising of Self Organizing Operational Neural Networks, for joint image compression and denoising. We employ contrastive learning to boost the network ability to differentiate noise from high frequency signal components, by emphasizing the correlation between noisy and clean counterparts. Experimental results demonstrate the effectiveness of the proposed method both in rate-distortion performance, and codec speed, outperforming the current state-of-the-art.