 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo we really have to filter out random noise in pre-training data for language models?
Paper and Code
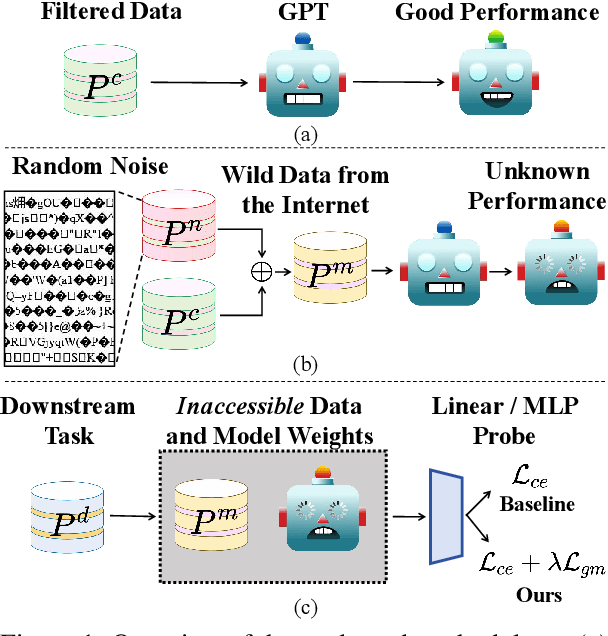



Web-scale pre-training datasets are the cornerstone of LLMs' success. However, text data curated from the internet inevitably contains random noise caused by decoding errors or unregulated web content. In contrast to previous works that focus on low quality or synthetic data, our study \textbf{provides the first systematic investigation into such random noise through a cohesive ``What-Why-How'' framework.} Surprisingly, we observed that the resulting increase in next-token prediction (NTP) loss was significantly lower than the proportion of random noise. We provide a theoretical justification for this phenomenon, which also elucidates the success of multilingual models. On the other hand, experiments show that the model's performance in downstream tasks is not based solely on the NTP loss, which means that random noise may result in degraded downstream performance. To address the potential adverse effects, we introduce a novel plug-and-play Local Gradient Matching loss, which explicitly enhances the denoising capability of the downstream task head by aligning the gradient of normal and perturbed features without requiring knowledge of the model's parameters. Additional experiments on 8 language and 14 vision benchmarks further validate its effectiveness.