 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCXR-ContraBench: Benchmarking Negated-Option Attraction in Medical VLMs
May 07, 2026When a chest X-ray shows consolidation but the question asks which finding is present, a medical vision-language model may answer "No consolidation." This is more than an incorrect choice: it is a polarity reversal that emits a clinical statement contradicting the image. We study this failure as negated-option attraction, where a model is drawn to a negated answer option even when it conflicts with both the visual evidence and the question. We introduce CXR-ContraBench (Chest X-Ray Contradiction Benchmark), a diagnostic benchmark spanning internal ReXVQA slices and external OpenI and CheXpert protocols. The benchmark centers on present-finding questions, where selecting "No X" despite visible X creates the main clinical risk, and uses absent-finding questions as secondary tests of whether models copy negated wording. Across CheXpert protocols, the failure is substantial and persistent. On a strict direct presence probe, MedGemma and Qwen2.5-VL reach only 31.49% and 30.21% accuracy, respectively; on a matched 135,754-record CheXpert training-split protocol, both models select negated options on over 62% of presence questions. Chain-of-thought prompting reduces some presence-side reversals but does not eliminate them and can amplify absence-side contradictions. Finally, QCCV-Neg (Question-Conditioned Consistency Verifier for Negation) deterministically repairs the measured polarity-confused subset without retraining, raising MedGemma and Qwen2.5-VL to 96.60% and 95.32% accuracy on the direct presence probe. These results show that standard accuracy can hide a clinically meaningful inference-time polarity failure. Source code and benchmark construction scripts are available at https://github.com/fangzr/cxr-contrabench-code.
RecoverMark: Robust Watermarking for Localization and Recovery of Manipulated Faces
Feb 24, 2026The proliferation of AI-generated content has facilitated sophisticated face manipulation, severely undermining visual integrity and posing unprecedented challenges to intellectual property. In response, a common proactive defense leverages fragile watermarks to detect, localize, or even recover manipulated regions. However, these methods always assume an adversary unaware of the embedded watermark, overlooking their inherent vulnerability to watermark removal attacks. Furthermore, this fragility is exacerbated in the commonly used dual-watermark strategy that adds a robust watermark for image ownership verification, where mutual interference and limited embedding capacity reduce the fragile watermark's effectiveness. To address the gap, we propose RecoverMark, a watermarking framework that achieves robust manipulation localization, content recovery, and ownership verification simultaneously. Our key insight is twofold. First, we exploit a critical real-world constraint: an adversary must preserve the background's semantic consistency to avoid visual detection, even if they apply global, imperceptible watermark removal attacks. Second, using the image's own content (face, in this paper) as the watermark enhances extraction robustness. Based on these insights, RecoverMark treats the protected face content itself as the watermark and embeds it into the surrounding background. By designing a robust two-stage training paradigm with carefully crafted distortion layers that simulate comprehensive potential attacks and a progressive training strategy, RecoverMark achieves a robust watermark embedding in no fragile manner for image manipulation localization, recovery, and image IP protection simultaneously. Extensive experiments demonstrate the proposed RecoverMark's robustness against both seen and unseen attacks and its generalizability to in-distribution and out-of-distribution data.
Learning Mutual View Information Graph for Adaptive Adversarial Collaborative Perception
Feb 23, 2026Collaborative perception (CP) enables data sharing among connected and autonomous vehicles (CAVs) to enhance driving safety. However, CP systems are vulnerable to adversarial attacks where malicious agents forge false objects via feature-level perturbations. Current defensive systems use threshold-based consensus verification by comparing collaborative and ego detection results. Yet, these defenses remain vulnerable to more sophisticated attack strategies that could exploit two critical weaknesses: (i) lack of robustness against attacks with systematic timing and target region optimization, and (ii) inadvertent disclosure of vulnerability knowledge through implicit confidence information in shared collaboration data. In this paper, we propose MVIG attack, a novel adaptive adversarial CP framework learning to capture vulnerability knowledge disclosed by different defensive CP systems from a unified mutual view information graph (MVIG) representation. Our approach combines MVIG representation with temporal graph learning to generate evolving fabrication risk maps and employs entropy-aware vulnerability search to optimize attack location, timing and persistence, enabling adaptive attacks with generalizability across various defensive configurations. Extensive evaluations on OPV2V and Adv-OPV2V datasets demonstrate that MVIG attack reduces defense success rates by up to 62\% against state-of-the-art defenses while achieving 47\% lower detection for persistent attacks at 29.9 FPS, exposing critical security gaps in CP systems. Code will be released at https://github.com/yihangtao/MVIG.git
Decoder Gradient Shields: A Family of Provable and High-Fidelity Methods Against Gradient-Based Box-Free Watermark Removal
Jan 17, 2026Box-free model watermarking has gained significant attention in deep neural network (DNN) intellectual property protection due to its model-agnostic nature and its ability to flexibly manage high-entropy image outputs from generative models. Typically operating in a black-box manner, it employs an encoder-decoder framework for watermark embedding and extraction. While existing research has focused primarily on the encoders for the robustness to resist various attacks, the decoders have been largely overlooked, leading to attacks against the watermark. In this paper, we identify one such attack against the decoder, where query responses are utilized to obtain backpropagated gradients to train a watermark remover. To address this issue, we propose Decoder Gradient Shields (DGSs), a family of defense mechanisms, including DGS at the output (DGS-O), at the input (DGS-I), and in the layers (DGS-L) of the decoder, with a closed-form solution for DGS-O and provable performance for all DGS. Leveraging the joint design of reorienting and rescaling of the gradients from watermark channel gradient leaking queries, the proposed DGSs effectively prevent the watermark remover from achieving training convergence to the desired low-loss value, while preserving image quality of the decoder output. We demonstrate the effectiveness of our proposed DGSs in diverse application scenarios. Our experimental results on deraining and image generation tasks with the state-of-the-art box-free watermarking show that our DGSs achieve a defense success rate of 100% under all settings.
NWaaS: Nonintrusive Watermarking as a Service for X-to-Image DNN
Jul 24, 2025The intellectual property of deep neural network (DNN) models can be protected with DNN watermarking, which embeds copyright watermarks into model parameters (white-box), model behavior (black-box), or model outputs (box-free), and the watermarks can be subsequently extracted to verify model ownership or detect model theft. Despite recent advances, these existing methods are inherently intrusive, as they either modify the model parameters or alter the structure. This natural intrusiveness raises concerns about watermarking-induced shifts in model behavior and the additional cost of fine-tuning, further exacerbated by the rapidly growing model size. As a result, model owners are often reluctant to adopt DNN watermarking in practice, which limits the development of practical Watermarking as a Service (WaaS) systems. To address this issue, we introduce Nonintrusive Watermarking as a Service (NWaaS), a novel trustless paradigm designed for X-to-Image models, in which we hypothesize that with the model untouched, an owner-defined watermark can still be extracted from model outputs. Building on this concept, we propose ShadowMark, a concrete implementation of NWaaS which addresses critical deployment challenges by establishing a robust and nonintrusive side channel in the protected model's black-box API, leveraging a key encoder and a watermark decoder. It is significantly distinctive from existing solutions by attaining the so-called absolute fidelity and being applicable to different DNN architectures, while being also robust against existing attacks, eliminating the fidelity-robustness trade-off. Extensive experiments on image-to-image, noise-to-image, noise-and-text-to-image, and text-to-image models, demonstrate the efficacy and practicality of ShadowMark for real-world deployment of nonintrusive DNN watermarking.
FIGhost: Fluorescent Ink-based Stealthy and Flexible Backdoor Attacks on Physical Traffic Sign Recognition
May 17, 2025Traffic sign recognition (TSR) systems are crucial for autonomous driving but are vulnerable to backdoor attacks. Existing physical backdoor attacks either lack stealth, provide inflexible attack control, or ignore emerging Vision-Large-Language-Models (VLMs). In this paper, we introduce FIGhost, the first physical-world backdoor attack leveraging fluorescent ink as triggers. Fluorescent triggers are invisible under normal conditions and activated stealthily by ultraviolet light, providing superior stealthiness, flexibility, and untraceability. Inspired by real-world graffiti, we derive realistic trigger shapes and enhance their robustness via an interpolation-based fluorescence simulation algorithm. Furthermore, we develop an automated backdoor sample generation method to support three attack objectives. Extensive evaluations in the physical world demonstrate FIGhost's effectiveness against state-of-the-art detectors and VLMs, maintaining robustness under environmental variations and effectively evading existing defenses.
GCP: Guarded Collaborative Perception with Spatial-Temporal Aware Malicious Agent Detection
Jan 05, 2025Collaborative perception significantly enhances autonomous driving safety by extending each vehicle's perception range through message sharing among connected and autonomous vehicles. Unfortunately, it is also vulnerable to adversarial message attacks from malicious agents, resulting in severe performance degradation. While existing defenses employ hypothesis-and-verification frameworks to detect malicious agents based on single-shot outliers, they overlook temporal message correlations, which can be circumvented by subtle yet harmful perturbations in model input and output spaces. This paper reveals a novel blind area confusion (BAC) attack that compromises existing single-shot outlier-based detection methods. As a countermeasure, we propose GCP, a Guarded Collaborative Perception framework based on spatial-temporal aware malicious agent detection, which maintains single-shot spatial consistency through a confidence-scaled spatial concordance loss, while simultaneously examining temporal anomalies by reconstructing historical bird's eye view motion flows in low-confidence regions. We also employ a joint spatial-temporal Benjamini-Hochberg test to synthesize dual-domain anomaly results for reliable malicious agent detection. Extensive experiments demonstrate GCP's superior performance under diverse attack scenarios, achieving up to 34.69% improvements in AP@0.5 compared to the state-of-the-art CP defense strategies under BAC attacks, while maintaining consistent 5-8% improvements under other typical attacks. Code will be released at https://github.com/CP-Security/GCP.git.
IC3M: In-Car Multimodal Multi-object Monitoring for Abnormal Status of Both Driver and Passengers
Oct 03, 2024Recently, in-car monitoring has emerged as a promising technology for detecting early-stage abnormal status of the driver and providing timely alerts to prevent traffic accidents. Although training models with multimodal data enhances the reliability of abnormal status detection, the scarcity of labeled data and the imbalance of class distribution impede the extraction of critical abnormal state features, significantly deteriorating training performance. Furthermore, missing modalities due to environment and hardware limitations further exacerbate the challenge of abnormal status identification. More importantly, monitoring abnormal health conditions of passengers, particularly in elderly care, is of paramount importance but remains underexplored. To address these challenges, we introduce our IC3M, an efficient camera-rotation-based multimodal framework for monitoring both driver and passengers in a car. Our IC3M comprises two key modules: an adaptive threshold pseudo-labeling strategy and a missing modality reconstruction. The former customizes pseudo-labeling thresholds for different classes based on the class distribution, generating class-balanced pseudo labels to guide model training effectively, while the latter leverages crossmodality relationships learned from limited labels to accurately recover missing modalities by distribution transferring from available modalities. Extensive experimental results demonstrate that IC3M outperforms state-of-the-art benchmarks in accuracy, precision, and recall while exhibiting superior robustness under limited labeled data and severe missing modality.
Secure Traffic Sign Recognition: An Attention-Enabled Universal Image Inpainting Mechanism against Light Patch Attacks
Sep 06, 2024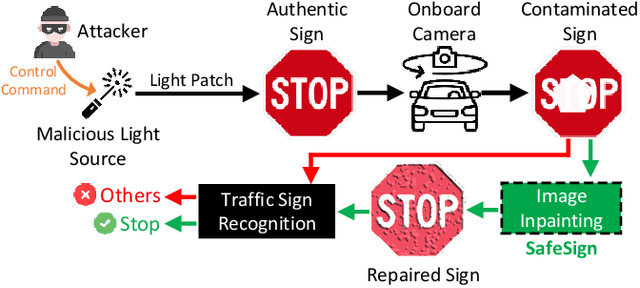

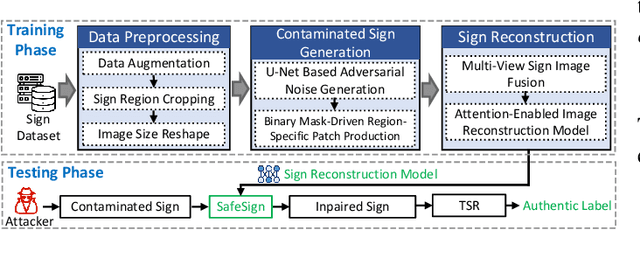
Traffic sign recognition systems play a crucial role in assisting drivers to make informed decisions while driving. However, due to the heavy reliance on deep learning technologies, particularly for future connected and autonomous driving, these systems are susceptible to adversarial attacks that pose significant safety risks to both personal and public transportation. Notably, researchers recently identified a new attack vector to deceive sign recognition systems: projecting well-designed adversarial light patches onto traffic signs. In comparison with traditional adversarial stickers or graffiti, these emerging light patches exhibit heightened aggression due to their ease of implementation and outstanding stealthiness. To effectively counter this security threat, we propose a universal image inpainting mechanism, namely, SafeSign. It relies on attention-enabled multi-view image fusion to repair traffic signs contaminated by adversarial light patches, thereby ensuring the accurate sign recognition. Here, we initially explore the fundamental impact of malicious light patches on the local and global feature spaces of authentic traffic signs. Then, we design a binary mask-based U-Net image generation pipeline outputting diverse contaminated sign patterns, to provide our image inpainting model with needed training data. Following this, we develop an attention mechanism-enabled neural network to jointly utilize the complementary information from multi-view images to repair contaminated signs. Finally, extensive experiments are conducted to evaluate SafeSign's effectiveness in resisting potential light patch-based attacks, bringing an average accuracy improvement of 54.8% in three widely-used sign recognition models