 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mutual View Information Graph for Adaptive Adversarial Collaborative Perception
Feb 23, 2026Collaborative perception (CP) enables data sharing among connected and autonomous vehicles (CAVs) to enhance driving safety. However, CP systems are vulnerable to adversarial attacks where malicious agents forge false objects via feature-level perturbations. Current defensive systems use threshold-based consensus verification by comparing collaborative and ego detection results. Yet, these defenses remain vulnerable to more sophisticated attack strategies that could exploit two critical weaknesses: (i) lack of robustness against attacks with systematic timing and target region optimization, and (ii) inadvertent disclosure of vulnerability knowledge through implicit confidence information in shared collaboration data. In this paper, we propose MVIG attack, a novel adaptive adversarial CP framework learning to capture vulnerability knowledge disclosed by different defensive CP systems from a unified mutual view information graph (MVIG) representation. Our approach combines MVIG representation with temporal graph learning to generate evolving fabrication risk maps and employs entropy-aware vulnerability search to optimize attack location, timing and persistence, enabling adaptive attacks with generalizability across various defensive configurations. Extensive evaluations on OPV2V and Adv-OPV2V datasets demonstrate that MVIG attack reduces defense success rates by up to 62\% against state-of-the-art defenses while achieving 47\% lower detection for persistent attacks at 29.9 FPS, exposing critical security gaps in CP systems. Code will be released at https://github.com/yihangtao/MVIG.git
Optimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward
Jan 31, 2026Agentic reasoning enables large reasoning models (LRMs) to dynamically acquire external knowledge, but yet optimizing the retrieval process remains challenging due to the lack of dense, principled reward signals. In this paper, we introduce InfoReasoner, a unified framework that incentivizes effective information seeking via a synthetic semantic information gain reward. Theoretically, we redefine information gain as uncertainty reduction over the model's belief states, establishing guarantees, including non-negativity, telescoping additivity, and channel monotonicity. Practically, to enable scalable optimization without manual retrieval annotations, we propose an output-aware intrinsic estimator that computes information gain directly from the model's output distributions using semantic clustering via bidirectional textual entailment. This intrinsic reward guides the policy to maximize epistemic progress, enabling efficient training via Group Relative Policy Optimxization (GRPO). Experiments across seven question-answering benchmarks demonstrate that InfoReasoner consistently outperforms strong retrieval-augmented baselines, achieving up to 5.4% average accuracy improvement. Our work provides a theoretically grounded and scalable path toward agentic reasoning with retrieval.
Shared Spatial Memory Through Predictive Coding
Nov 06, 2025

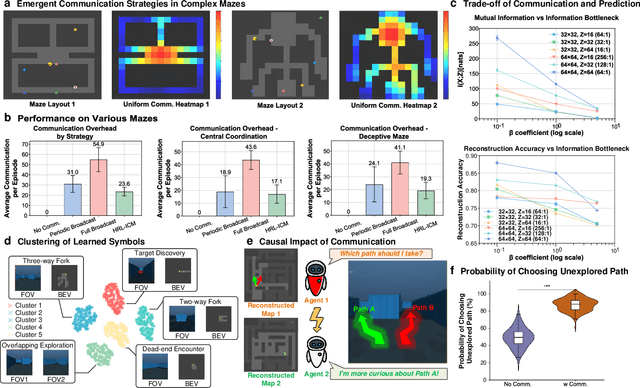
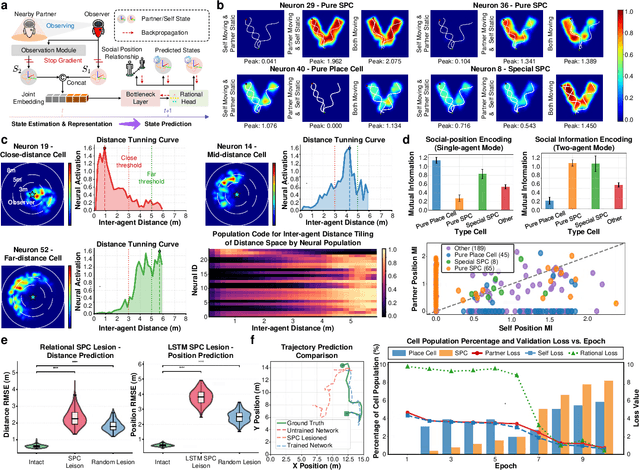
Sharing and reconstructing a consistent spatial memory is a critical challenge in multi-agent systems, where partial observability and limited bandwidth often lead to catastrophic failures in coordination. We introduce a multi-agent predictive coding framework that formulate coordination as the minimization of mutual uncertainty among agents. Instantiated as an information bottleneck objective, it prompts agents to learn not only who and what to communicate but also when. At the foundation of this framework lies a grid-cell-like metric as internal spatial coding for self-localization, emerging spontaneously from self-supervised motion prediction. Building upon this internal spatial code, agents gradually develop a bandwidth-efficient communication mechanism and specialized neural populations that encode partners' locations: an artificial analogue of hippocampal social place cells (SPCs). These social representations are further enacted by a hierarchical reinforcement learning policy that actively explores to reduce joint uncertainty. On the Memory-Maze benchmark, our approach shows exceptional resilience to bandwidth constraints: success degrades gracefully from 73.5% to 64.4% as bandwidth shrinks from 128 to 4 bits/step, whereas a full-broadcast baseline collapses from 67.6% to 28.6%. Our findings establish a theoretically principled and biologically plausible basis for how complex social representations emerge from a unified predictive drive, leading to social collective intelligence.
Task-Oriented Communications for Visual Navigation with Edge-Aerial Collaboration in Low Altitude Economy
Apr 29, 2025To support the Low Altitude Economy (LAE), precise unmanned aerial vehicles (UAVs) localization in urban areas where global positioning system (GPS) signals are unavailable. Vision-based methods offer a viable alternative but face severe bandwidth, memory and processing constraints on lightweight UAVs. Inspired by mammalian spatial cognition, we propose a task-oriented communication framework, where UAVs equipped with multi-camera systems extract compact multi-view features and offload localization tasks to edge servers. We introduce the Orthogonally-constrained Variational Information Bottleneck encoder (O-VIB), which incorporates automatic relevance determination (ARD) to prune non-informative features while enforcing orthogonality to minimize redundancy. This enables efficient and accurate localization with minimal transmission cost. Extensive evaluation on a dedicated LAE UAV dataset shows that O-VIB achieves high-precision localization under stringent bandwidth budgets. Code and dataset will be made publicly available: github.com/fangzr/TOC-Edge-Aerial.
Decoder Gradient Shield: Provable and High-Fidelity Prevention of Gradient-Based Box-Free Watermark Removal
Feb 28, 2025



The intellectual property of deep image-to-image models can be protected by the so-called box-free watermarking. It uses an encoder and a decoder, respectively, to embed into and extract from the model's output images invisible copyright marks. Prior works have improved watermark robustness, focusing on the design of better watermark encoders. In this paper, we reveal an overlooked vulnerability of the unprotected watermark decoder which is jointly trained with the encoder and can be exploited to train a watermark removal network. To defend against such an attack, we propose the decoder gradient shield (DGS) as a protection layer in the decoder API to prevent gradient-based watermark removal with a closed-form solution. The fundamental idea is inspired by the classical adversarial attack, but is utilized for the first time as a defensive mechanism in the box-free model watermarking. We then demonstrate that DGS can reorient and rescale the gradient directions of watermarked queries and stop the watermark remover's training loss from converging to the level without DGS, while retaining decoder output image quality. Experimental results verify the effectiveness of proposed method. Code of paper will be made available upon acceptance.
Channel-Aware Throughput Maximization for Cooperative Data Fusion in CAV
Oct 06, 2024Connected and autonomous vehicles (CAVs) have garnered significant attention due to their extended perception range and enhanced sensing coverage. To address challenges such as blind spots and obstructions, CAVs employ vehicle-to-vehicle (V2V) communications to aggregate sensory data from surrounding vehicles. However, cooperative perception is often constrained by the limitations of achievable network throughput and channel quality. In this paper, we propose a channel-aware throughput maximization approach to facilitate CAV data fusion, leveraging a self-supervised autoencoder for adaptive data compression. We formulate the problem as a mixed integer programming (MIP) model, which we decompose into two sub-problems to derive optimal data rate and compression ratio solutions under given link conditions. An autoencoder is then trained to minimize bitrate with the determined compression ratio, and a fine-tuning strategy is employed to further reduce spectrum resource consumption. Experimental evaluation on the OpenCOOD platform demonstrates the effectiveness of our proposed algorithm, showing more than 20.19\% improvement in network throughput and a 9.38\% increase in average precision (AP@IoU) compared to state-of-the-art methods, with an optimal latency of 19.99 ms.
Direct-CP: Directed Collaborative Perception for Connected and Autonomous Vehicles via Proactive Attention
Sep 13, 2024Collaborative perception (CP) leverages visual data from connected and autonomous vehicles (CAV) to enhance an ego vehicle's field of view (FoV). Despite recent progress, current CP methods expand the ego vehicle's 360-degree perceptual range almost equally, which faces two key challenges. Firstly, in areas with uneven traffic distribution, focusing on directions with little traffic offers limited benefits. Secondly, under limited communication budgets, allocating excessive bandwidth to less critical directions lowers the perception accuracy in more vital areas. To address these issues, we propose Direct-CP, a proactive and direction-aware CP system aiming at improving CP in specific directions. Our key idea is to enable an ego vehicle to proactively signal its interested directions and readjust its attention to enhance local directional CP performance. To achieve this, we first propose an RSU-aided direction masking mechanism that assists an ego vehicle in identifying vital directions. Additionally, we design a direction-aware selective attention module to wisely aggregate pertinent features based on ego vehicle's directional priorities, communication budget, and the positional data of CAVs. Moreover, we introduce a direction-weighted detection loss (DWLoss) to capture the divergence between directional CP outcomes and the ground truth, facilitating effective model training. Extensive experiments on the V2X-Sim 2.0 dataset demonstrate that our approach achieves 19.8\% higher local perception accuracy in interested directions and 2.5\% higher overall perception accuracy than the state-of-the-art methods in collaborative 3D object detection tasks.
Secure Traffic Sign Recognition: An Attention-Enabled Universal Image Inpainting Mechanism against Light Patch Attacks
Sep 06, 2024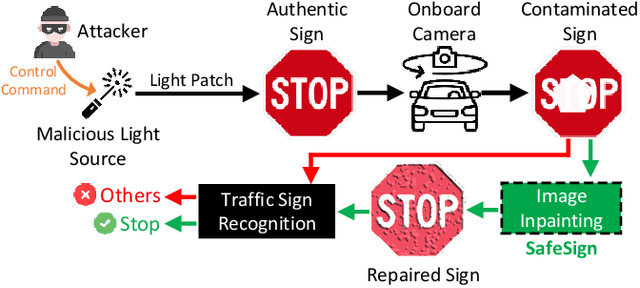

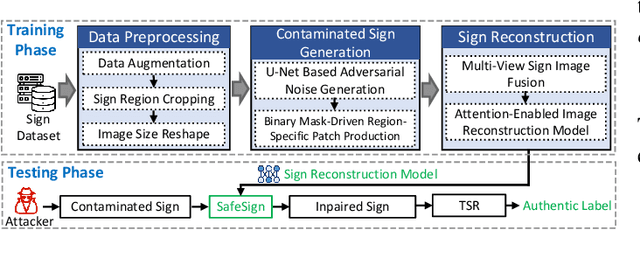
Traffic sign recognition systems play a crucial role in assisting drivers to make informed decisions while driving. However, due to the heavy reliance on deep learning technologies, particularly for future connected and autonomous driving, these systems are susceptible to adversarial attacks that pose significant safety risks to both personal and public transportation. Notably, researchers recently identified a new attack vector to deceive sign recognition systems: projecting well-designed adversarial light patches onto traffic signs. In comparison with traditional adversarial stickers or graffiti, these emerging light patches exhibit heightened aggression due to their ease of implementation and outstanding stealthiness. To effectively counter this security threat, we propose a universal image inpainting mechanism, namely, SafeSign. It relies on attention-enabled multi-view image fusion to repair traffic signs contaminated by adversarial light patches, thereby ensuring the accurate sign recognition. Here, we initially explore the fundamental impact of malicious light patches on the local and global feature spaces of authentic traffic signs. Then, we design a binary mask-based U-Net image generation pipeline outputting diverse contaminated sign patterns, to provide our image inpainting model with needed training data. Following this, we develop an attention mechanism-enabled neural network to jointly utilize the complementary information from multi-view images to repair contaminated signs. Finally, extensive experiments are conducted to evaluate SafeSign's effectiveness in resisting potential light patch-based attacks, bringing an average accuracy improvement of 54.8% in three widely-used sign recognition models
AgentsCoMerge: Large Language Model Empowered Collaborative Decision Making for Ramp Merging
Aug 07, 2024Ramp merging is one of the bottlenecks in traffic systems, which commonly cause traffic congestion, accidents, and severe carbon emissions. In order to address this essential issue and enhance the safety and efficiency of connected and autonomous vehicles (CAVs) at multi-lane merging zones, we propose a novel collaborative decision-making framework, named AgentsCoMerge, to leverage large language models (LLMs). Specifically, we first design a scene observation and understanding module to allow an agent to capture the traffic environment. Then we propose a hierarchical planning module to enable the agent to make decisions and plan trajectories based on the observation and the agent's own state. In addition, in order to facilitate collaboration among multiple agents, we introduce a communication module to enable the surrounding agents to exchange necessary information and coordinate their actions. Finally, we develop a reinforcement reflection guided training paradigm to further enhance the decision-making capability of the framework. Extensive experiments are conducted to evaluate the performance of our proposed method, demonstrating its superior efficiency and effectiveness for multi-agent collaborative decision-making under various ramp merging scenarios.
AgentsCoDriver: Large Language Model Empowered Collaborative Driving with Lifelong Learning
Apr 09, 2024Connected and autonomous driving is developing rapidly in recent years. However, current autonomous driving systems, which are primarily based on data-driven approaches, exhibit deficiencies in interpretability, generalization, and continuing learning capabilities. In addition, the single-vehicle autonomous driving systems lack of the ability of collaboration and negotiation with other vehicles, which is crucial for the safety and efficiency of autonomous driving systems. In order to address these issues, we leverage large language models (LLMs) to develop a novel framework, AgentsCoDriver, to enable multiple vehicles to conduct collaborative driving. AgentsCoDriver consists of five modules: observation module, reasoning engine, cognitive memory module, reinforcement reflection module, and communication module. It can accumulate knowledge, lessons, and experiences over time by continuously interacting with the environment, thereby making itself capable of lifelong learning. In addition, by leveraging the communication module, different agents can exchange information and realize negotiation and collaboration in complex traffic environments. Extensive experiments are conducted and show the superiority of AgentsCoDriver.