 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
Feb 27, 2025The emergence of audio language models is empowered by neural audio codecs, which establish critical mappings between continuous waveforms and discrete tokens compatible with language model paradigms. The evolutionary trends from multi-layer residual vector quantizer to single-layer quantizer are beneficial for language-autoregressive decoding. However, the capability to handle multi-domain audio signals through a single codebook remains constrained by inter-domain distribution discrepancies. In this work, we introduce UniCodec, a unified audio codec with a single codebook to support multi-domain audio data, including speech, music, and sound. To achieve this, we propose a partitioned domain-adaptive codebook method and domain Mixture-of-Experts strategy to capture the distinct characteristics of each audio domain. Furthermore, to enrich the semantic density of the codec without auxiliary modules, we propose a self-supervised mask prediction modeling approach. Comprehensive objective and subjective evaluations demonstrate that UniCodec achieves excellent audio reconstruction performance across the three audio domains, outperforming existing unified neural codecs with a single codebook, and even surpasses state-of-the-art domain-specific codecs on both acoustic and semantic representation capabilities.
Feedforward Sequential Memory Neural Networks without Recurrent Feedback
Oct 09, 2015
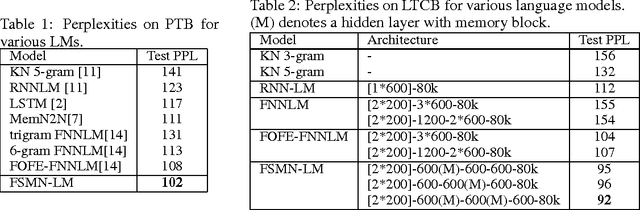
We introduce a new structure for memory neural networks, called feedforward sequential memory networks (FSMN), which can learn long-term dependency without using recurrent feedback. The proposed FSMN is a standard feedforward neural networks equipped with learnable sequential memory blocks in the hidden layers. In this work, we have applied FSMN to several language modeling (LM) tasks. Experimental results have shown that the memory blocks in FSMN can learn effective representations of long history. Experiments have shown that FSMN based language models can significantly outperform not only feedforward neural network (FNN) based LMs but also the popular recurrent neural network (RNN) LMs.