 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub- μ W Battery-Less and Oscillator-Less Wi-Fi Backscattering Transmitter Reusing RF Signal for Harvesting, Communications, and Motion Detection
Aug 07, 2025
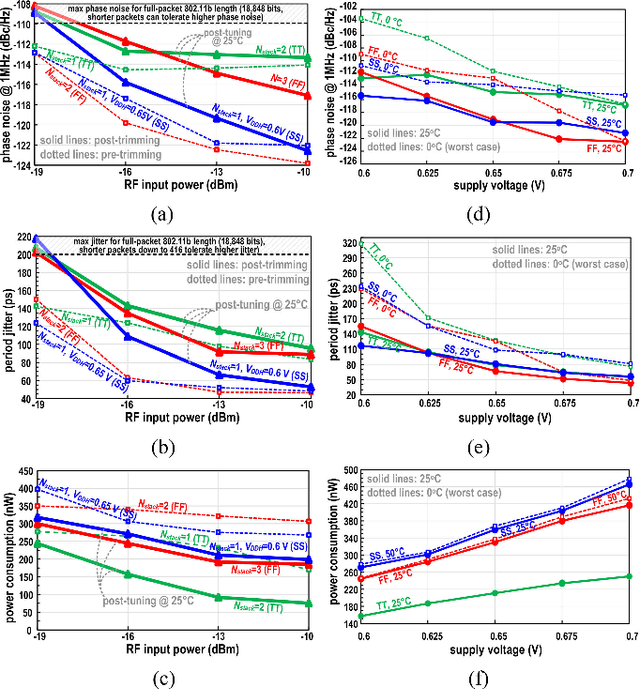


In this paper, a sub-uW power 802.11b backscattering transmitter is presented to enable reuse of the same incident wave for three purposes: RF harvesting, backscattering communications and position/motion sensing. The removal of the battery and any off-chip motion sensor (e.g., MEMS) enables unprecedented level of miniaturization and ubiquity, unrestricted device lifespan, low fabrication and maintenance cost. The uW power wall for WiFi transmitters is broken for the first time via local oscillator elimination, as achieved by extracting its frequency through second-order intermodulation of a twotone incident wave. The two-tone scheme also enables a cumulative harvesting/transmission/sensing sensitivity down to Pmin -19 dBm. Position/motion sensing is enabled by using the harvested voltage as a proxy for the Received Signal Strength (RSS), allowing to sense the chip location with respect to the tone generator(s) shared across tags in indoor neighborhoods.
Multi-Stage Face-Voice Association Learning with Keynote Speaker Diarization
Jul 25, 2024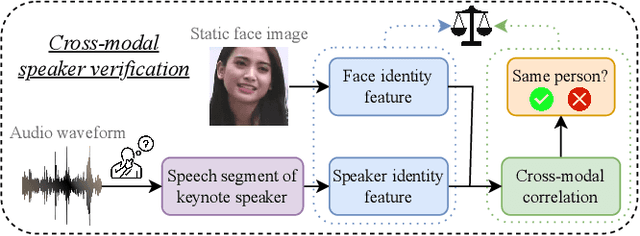
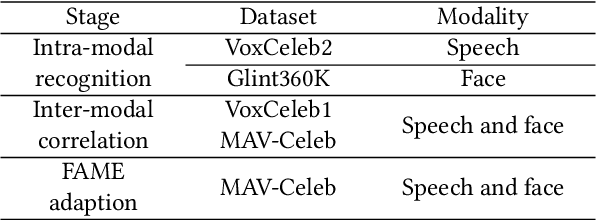
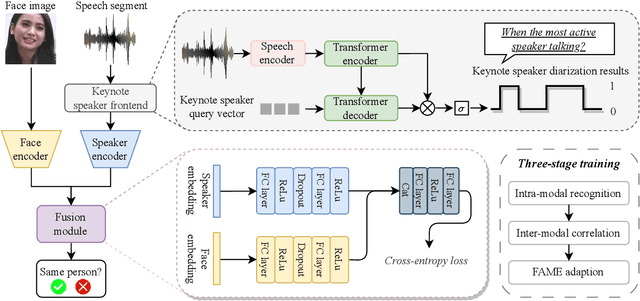

The human brain has the capability to associate the unknown person's voice and face by leveraging their general relationship, referred to as ``cross-modal speaker verification''. This task poses significant challenges due to the complex relationship between the modalities. In this paper, we propose a ``Multi-stage Face-voice Association Learning with Keynote Speaker Diarization''~(MFV-KSD) framework. MFV-KSD contains a keynote speaker diarization front-end to effectively address the noisy speech inputs issue. To balance and enhance the intra-modal feature learning and inter-modal correlation understanding, MFV-KSD utilizes a novel three-stage training strategy. Our experimental results demonstrated robust performance, achieving the first rank in the 2024 Face-voice Association in Multilingual Environments (FAME) challenge with an overall Equal Error Rate (EER) of 19.9%. Details can be found in https://github.com/TaoRuijie/MFV-KSD.