 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Face-Voice Association Learning with Keynote Speaker Diarization
Paper and Code
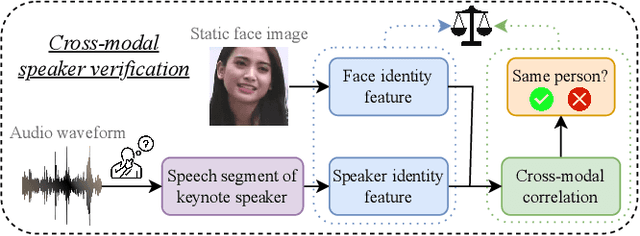
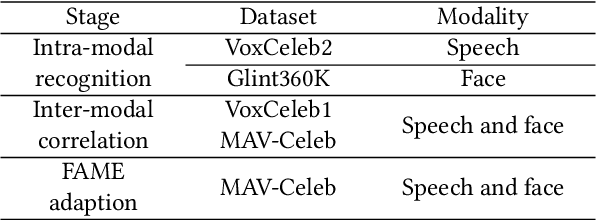
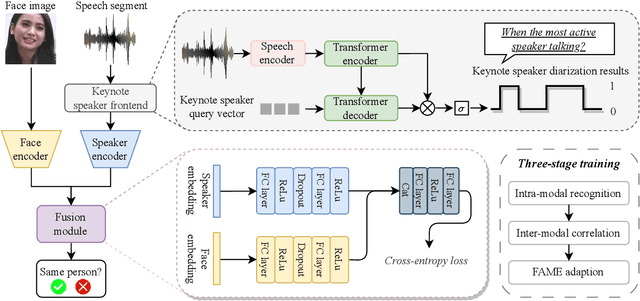

The human brain has the capability to associate the unknown person's voice and face by leveraging their general relationship, referred to as ``cross-modal speaker verification''. This task poses significant challenges due to the complex relationship between the modalities. In this paper, we propose a ``Multi-stage Face-voice Association Learning with Keynote Speaker Diarization''~(MFV-KSD) framework. MFV-KSD contains a keynote speaker diarization front-end to effectively address the noisy speech inputs issue. To balance and enhance the intra-modal feature learning and inter-modal correlation understanding, MFV-KSD utilizes a novel three-stage training strategy. Our experimental results demonstrated robust performance, achieving the first rank in the 2024 Face-voice Association in Multilingual Environments (FAME) challenge with an overall Equal Error Rate (EER) of 19.9%. Details can be found in https://github.com/TaoRuijie/MFV-KSD.