 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Paper and Code
Jul 05, 2024
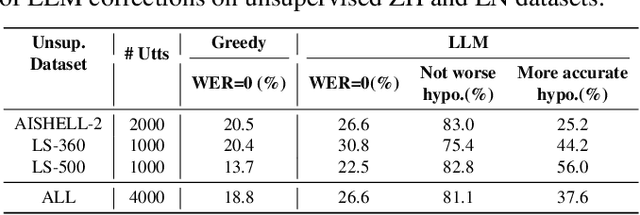


Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.