 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPL Bench: Evaluation Framework For Probabilistic Programming Languages
Paper and Code
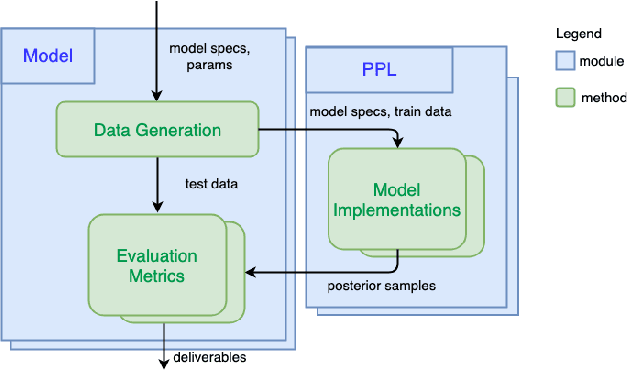
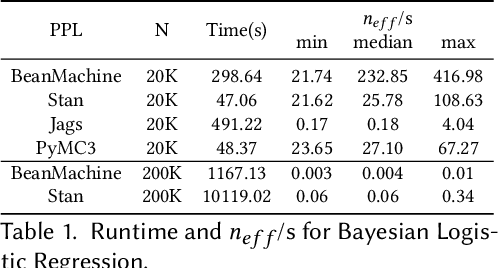
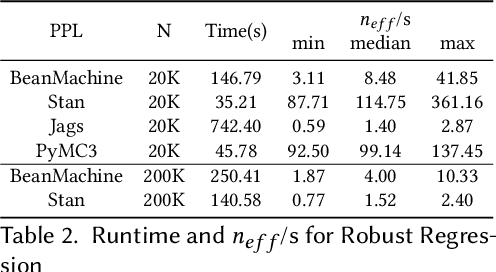
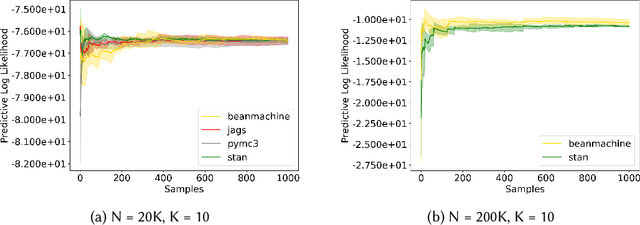
We introduce PPL Bench, a new benchmark for evaluating Probabilistic Programming Languages (PPLs) on a variety of statistical models. The benchmark includes data generation and evaluation code for a number of models as well as implementations in some common PPLs. All of the benchmark code and PPL implementations are available on Github. We welcome contributions of new models and PPLs and as well as improvements in existing PPL implementations. The purpose of the benchmark is two-fold. First, we want researchers as well as conference reviewers to be able to evaluate improvements in PPLs in a standardized setting. Second, we want end users to be able to pick the PPL that is most suited for their modeling application. In particular, we are interested in evaluating the accuracy and speed of convergence of the inferred posterior. Each PPL only needs to provide posterior samples given a model and observation data. The framework automatically computes and plots growth in predictive log-likelihood on held out data in addition to reporting other common metrics such as effective sample size and $\hat{r}$.