 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unification of Discrete, Gaussian, and Simplicial Diffusion
Dec 17, 2025To model discrete sequences such as DNA, proteins, and language using diffusion, practitioners must choose between three major methods: diffusion in discrete space, Gaussian diffusion in Euclidean space, or diffusion on the simplex. Despite their shared goal, these models have disparate algorithms, theoretical structures, and tradeoffs: discrete diffusion has the most natural domain, Gaussian diffusion has more mature algorithms, and diffusion on the simplex in principle combines the strengths of the other two but in practice suffers from a numerically unstable stochastic processes. Ideally we could see each of these models as instances of the same underlying framework, and enable practitioners to switch between models for downstream applications. However previous theories have only considered connections in special cases. Here we build a theory unifying all three methods of discrete diffusion as different parameterizations of the same underlying process: the Wright-Fisher population genetics model. In particular, we find simplicial and Gaussian diffusion as two large-population limits. Our theory formally connects the likelihoods and hyperparameters of these models and leverages decades of mathematical genetics literature to unlock stable simplicial diffusion. Finally, we relieve the practitioner of balancing model trade-offs by demonstrating it is possible to train a single model that can perform diffusion in any of these three domains at test time. Our experiments show that Wright-Fisher simplicial diffusion is more stable and outperforms previous simplicial diffusion models on conditional DNA generation. We also show that we can train models on multiple domains at once that are competitive with models trained on any individual domain.
Out-of-Distribution Detection Methods Answer the Wrong Questions
Jul 02, 2025To detect distribution shifts and improve model safety, many out-of-distribution (OOD) detection methods rely on the predictive uncertainty or features of supervised models trained on in-distribution data. In this paper, we critically re-examine this popular family of OOD detection procedures, and we argue that these methods are fundamentally answering the wrong questions for OOD detection. There is no simple fix to this misalignment, since a classifier trained only on in-distribution classes cannot be expected to identify OOD points; for instance, a cat-dog classifier may confidently misclassify an airplane if it contains features that distinguish cats from dogs, despite generally appearing nothing alike. We find that uncertainty-based methods incorrectly conflate high uncertainty with being OOD, while feature-based methods incorrectly conflate far feature-space distance with being OOD. We show how these pathologies manifest as irreducible errors in OOD detection and identify common settings where these methods are ineffective. Additionally, interventions to improve OOD detection such as feature-logit hybrid methods, scaling of model and data size, epistemic uncertainty representation, and outlier exposure also fail to address this fundamental misalignment in objectives. We additionally consider unsupervised density estimation and generative models for OOD detection, which we show have their own fundamental limitations.
Simplifying Neural Network Training Under Class Imbalance
Dec 05, 2023



Real-world datasets are often highly class-imbalanced, which can adversely impact the performance of deep learning models. The majority of research on training neural networks under class imbalance has focused on specialized loss functions, sampling techniques, or two-stage training procedures. Notably, we demonstrate that simply tuning existing components of standard deep learning pipelines, such as the batch size, data augmentation, optimizer, and label smoothing, can achieve state-of-the-art performance without any such specialized class imbalance methods. We also provide key prescriptions and considerations for training under class imbalance, and an understanding of why imbalance methods succeed or fail.
A Study of Bayesian Neural Network Surrogates for Bayesian Optimization
May 31, 2023



Bayesian optimization is a highly efficient approach to optimizing objective functions which are expensive to query. These objectives are typically represented by Gaussian process (GP) surrogate models which are easy to optimize and support exact inference. While standard GP surrogates have been well-established in Bayesian optimization, Bayesian neural networks (BNNs) have recently become practical function approximators, with many benefits over standard GPs such as the ability to naturally handle non-stationarity and learn representations for high-dimensional data. In this paper, we study BNNs as alternatives to standard GP surrogates for optimization. We consider a variety of approximate inference procedures for finite-width BNNs, including high-quality Hamiltonian Monte Carlo, low-cost stochastic MCMC, and heuristics such as deep ensembles. We also consider infinite-width BNNs and partially stochastic models such as deep kernel learning. We evaluate this collection of surrogate models on diverse problems with varying dimensionality, number of objectives, non-stationarity, and discrete and continuous inputs. We find: (i) the ranking of methods is highly problem dependent, suggesting the need for tailored inductive biases; (ii) HMC is the most successful approximate inference procedure for fully stochastic BNNs; (iii) full stochasticity may be unnecessary as deep kernel learning is relatively competitive; (iv) infinite-width BNNs are particularly promising, especially in high dimensions.
PPL Bench: Evaluation Framework For Probabilistic Programming Languages
Oct 17, 2020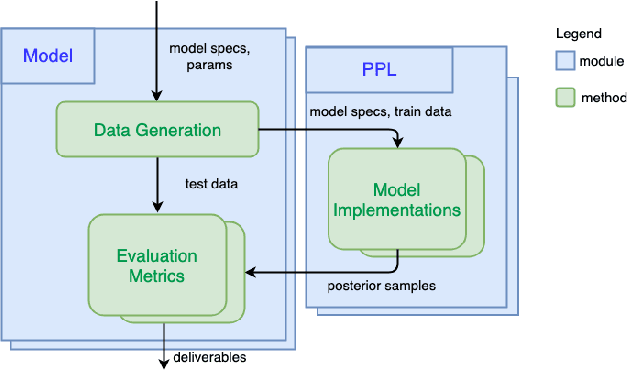
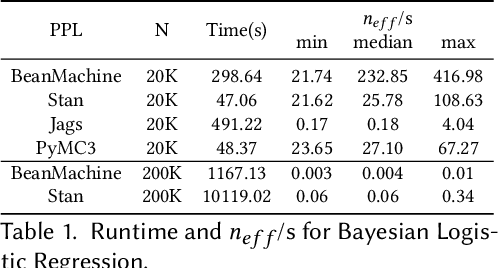
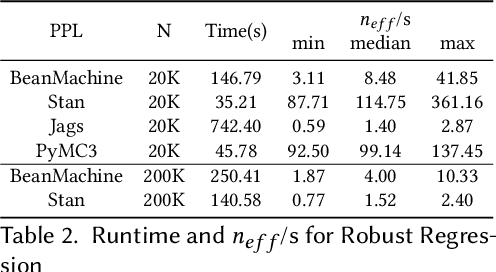
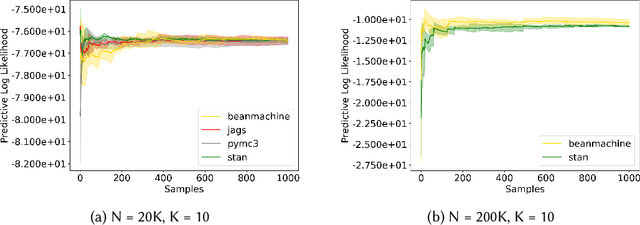
We introduce PPL Bench, a new benchmark for evaluating Probabilistic Programming Languages (PPLs) on a variety of statistical models. The benchmark includes data generation and evaluation code for a number of models as well as implementations in some common PPLs. All of the benchmark code and PPL implementations are available on Github. We welcome contributions of new models and PPLs and as well as improvements in existing PPL implementations. The purpose of the benchmark is two-fold. First, we want researchers as well as conference reviewers to be able to evaluate improvements in PPLs in a standardized setting. Second, we want end users to be able to pick the PPL that is most suited for their modeling application. In particular, we are interested in evaluating the accuracy and speed of convergence of the inferred posterior. Each PPL only needs to provide posterior samples given a model and observation data. The framework automatically computes and plots growth in predictive log-likelihood on held out data in addition to reporting other common metrics such as effective sample size and $\hat{r}$.
Newtonian Monte Carlo: single-site MCMC meets second-order gradient methods
Jan 15, 2020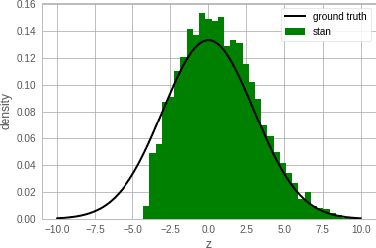

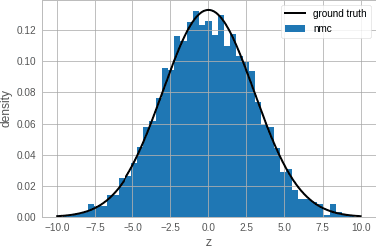
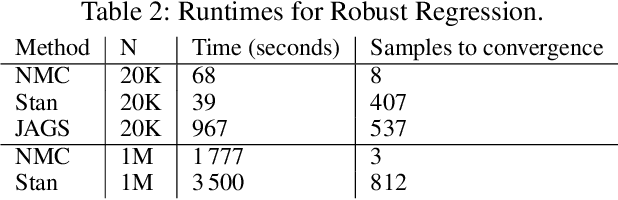
Single-site Markov Chain Monte Carlo (MCMC) is a variant of MCMC in which a single coordinate in the state space is modified in each step. Structured relational models are a good candidate for this style of inference. In the single-site context, second order methods become feasible because the typical cubic costs associated with these methods is now restricted to the dimension of each coordinate. Our work, which we call Newtonian Monte Carlo (NMC), is a method to improve MCMC convergence by analyzing the first and second order gradients of the target density to determine a suitable proposal density at each point. Existing first order gradient-based methods suffer from the problem of determining an appropriate step size. Too small a step size and it will take a large number of steps to converge, while a very large step size will cause it to overshoot the high density region. NMC is similar to the Newton-Raphson update in optimization where the second order gradient is used to automatically scale the step size in each dimension. However, our objective is to find a parameterized proposal density rather than the maxima. As a further improvement on existing first and second order methods, we show that random variables with constrained supports don't need to be transformed before taking a gradient step. We demonstrate the efficiency of NMC on a number of different domains. For statistical models where the prior is conjugate to the likelihood, our method recovers the posterior quite trivially in one step. However, we also show results on fairly large non-conjugate models, where NMC performs better than adaptive first order methods such as NUTS or other inexact scalable inference methods such as Stochastic Variational Inference or bootstrapping.