 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Shot Frame Semantic Parsing with Task Agnostic Ontologies and Simple Labels
May 05, 2023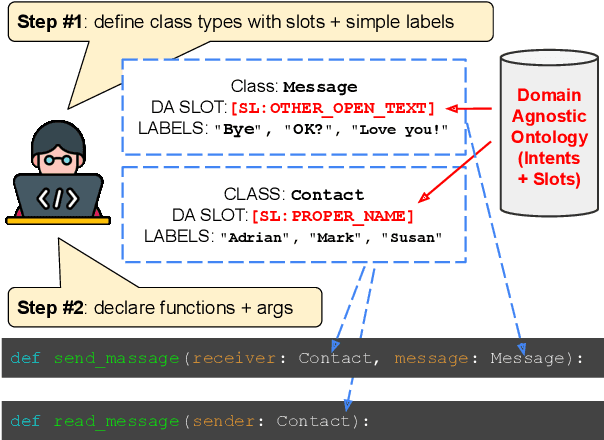
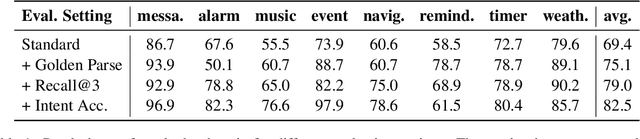
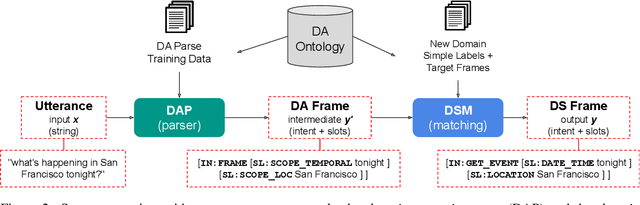
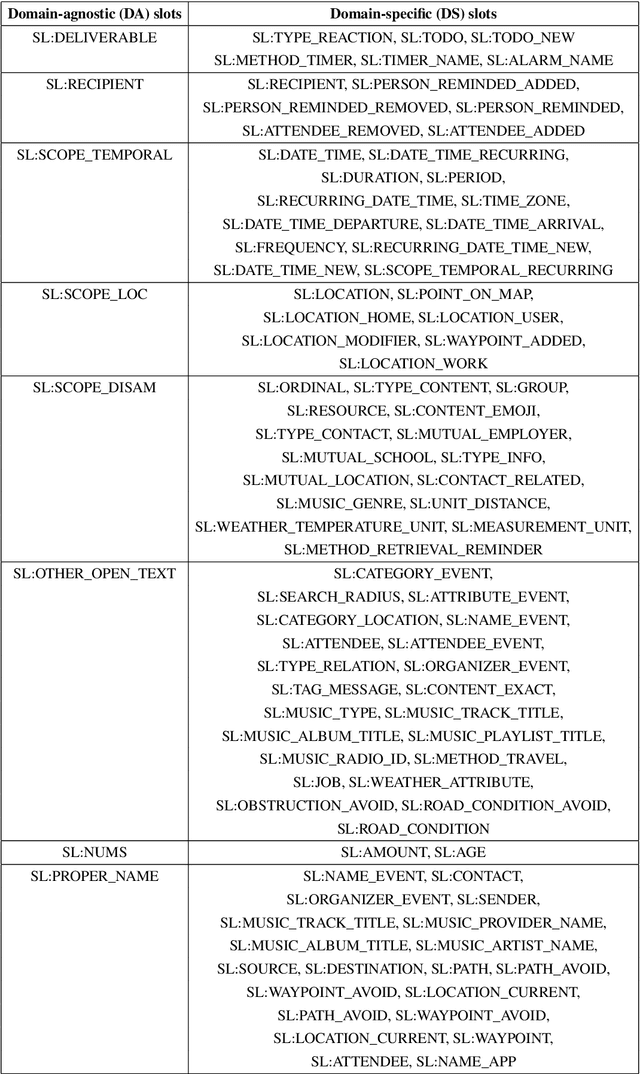
Frame semantic parsing is an important component of task-oriented dialogue systems. Current models rely on a significant amount training data to successfully identify the intent and slots in the user's input utterance. This creates a significant barrier for adding new domains to virtual assistant capabilities, as creation of this data requires highly specialized NLP expertise. In this work we propose OpenFSP, a framework that allows for easy creation of new domains from a handful of simple labels that can be generated without specific NLP knowledge. Our approach relies on creating a small, but expressive, set of domain agnostic slot types that enables easy annotation of new domains. Given such annotation, a matching algorithm relying on sentence encoders predicts the intent and slots for domains defined by end-users. Extensive experiments on the TopV2 dataset shows that our model outperforms strong baselines in this simple labels setting.
Neural Analogical Matching
Apr 27, 2020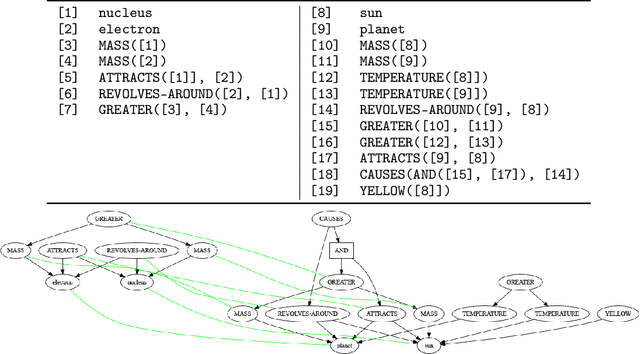
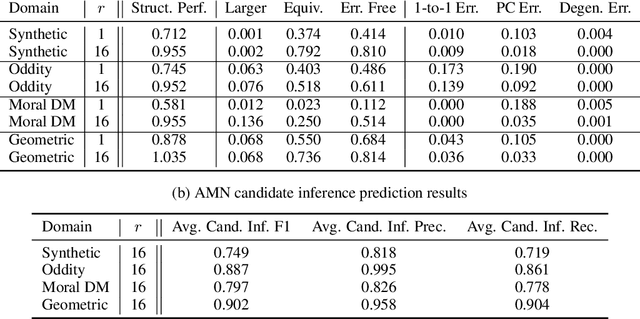
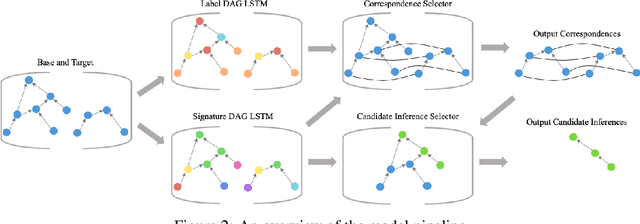

Analogy is core to human cognition. It allows us to solve problems based on prior experience, it governs the way we conceptualize new information, and it even influences our visual perception. The importance of analogy to humans has made it an active area of research in the broader field of artificial intelligence, resulting in data-efficient models that learn and reason in human-like ways. While analogy and deep learning have generally been studied independently of one another, the integration of the two lines of research seems like a promising step towards more robust and efficient learning techniques. As part of the first steps towards such an integration, we introduce the Analogical Matching Network: a neural architecture that learns to produce analogies between structured, symbolic representations that are largely consistent with the principles of Structure-Mapping Theory.
Improving Graph Neural Network Representations of Logical Formulae with Subgraph Pooling
Nov 15, 2019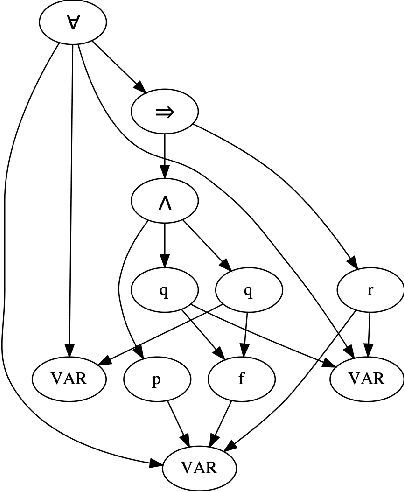
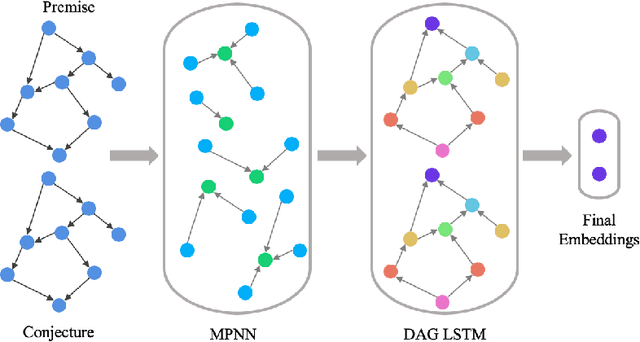


Recent advances in the integration of deep learning with automated theorem proving have centered around the representation of logical formulae as inputs to deep learning systems. In particular, there has been a shift from character and token-level representations to graph-structured representations, in large part driven by the rapidly emerging body of research on geometric deep learning. Typically, structure-aware neural methods for embedding logical formulae have been variants of either Tree LSTMs or GNNs. While more effective than character and token-level approaches, such methods have often made representational trade-offs that limited their ability to effectively represent the global structure of their inputs. In this work, we introduce a novel approach for embedding logical formulae using DAG LSTMs that is designed to overcome the limitations of both Tree LSTMs and GNNs. The effectiveness of the proposed framework is demonstrated on the tasks of premise selection and proof step classification where it achieves the state-of-the-art performance on two standard datasets.
High-Fidelity Vector Space Models of Structured Data
Jan 15, 2019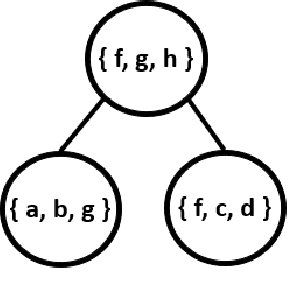

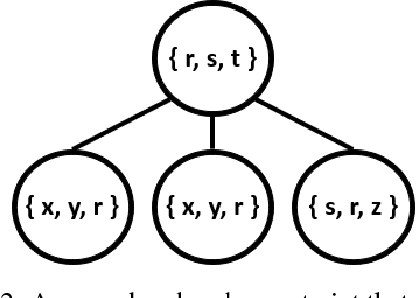
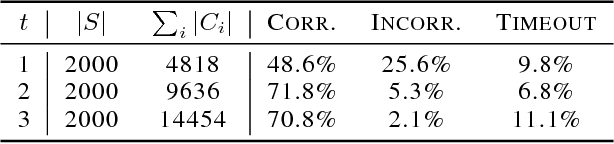
Machine learning systems regularly deal with structured data in real-world applications. Unfortunately, such data has been difficult to faithfully represent in a way that most machine learning techniques would expect, i.e. as a real-valued vector of a fixed, pre-specified size. In this work, we introduce a novel approach that compiles structured data into a satisfiability problem which has in its set of solutions at least (and often only) the input data. The satisfiability problem is constructed from constraints which are generated automatically a priori from a given signature, thus trivially allowing for a bag-of-words-esque vector representation of the input to be constructed. The method is demonstrated in two areas, automated reasoning and natural language processing, where it is shown to produce vector representations of natural-language sentences and first-order logic clauses that can be precisely translated back to their original, structured input forms.