 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Reinforcement Learning based Approach to Learning Transferable Proof Guidance Strategies
Paper and Code
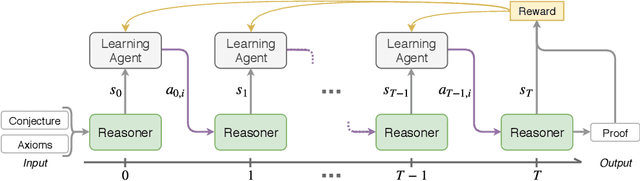
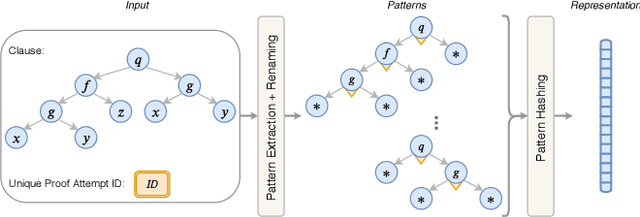

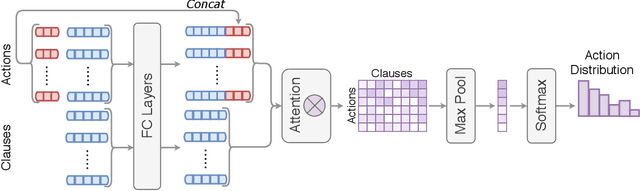
Traditional first-order logic (FOL) reasoning systems usually rely on manual heuristics for proof guidance. We propose TRAIL: a system that learns to perform proof guidance using reinforcement learning. A key design principle of our system is that it is general enough to allow transfer to problems in different domains that do not share the same vocabulary of the training set. To do so, we developed a novel representation of the internal state of a prover in terms of clauses and inference actions, and a novel neural-based attention mechanism to learn interactions between clauses. We demonstrate that this approach enables the system to generalize from training to test data across domains with different vocabularies, suggesting that the neural architecture in TRAIL is well suited for representing and processing of logical formalisms.