 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit, Unlearn, Merge: Leveraging Data Attributes for More Effective Unlearning in LLMs
Paper and Code
Jun 17, 2024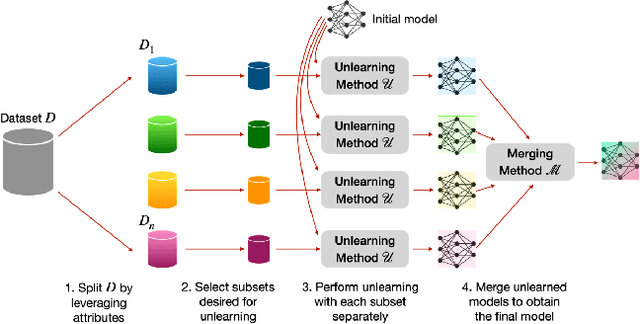
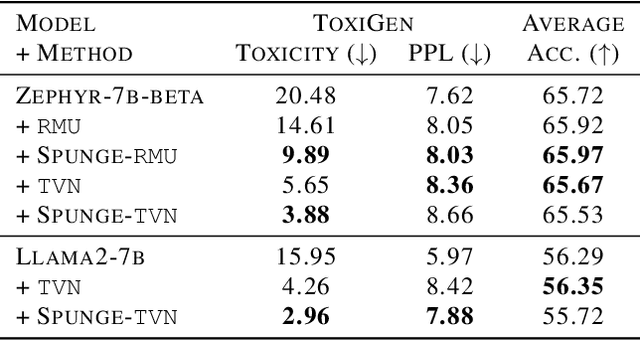
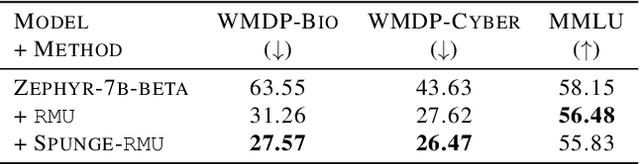
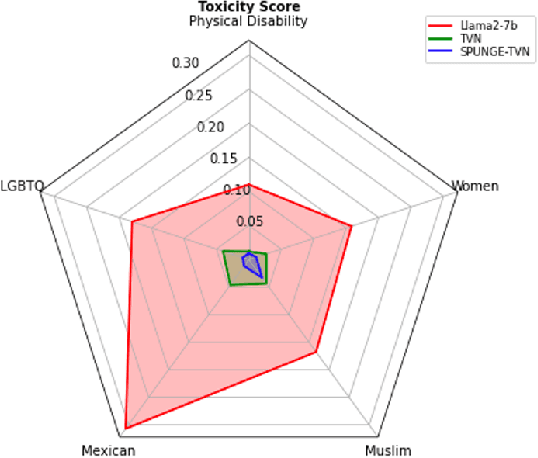
Large language models (LLMs) have shown to pose social and ethical risks such as generating toxic language or facilitating malicious use of hazardous knowledge. Machine unlearning is a promising approach to improve LLM safety by directly removing harmful behaviors and knowledge. In this paper, we propose "SPlit, UNlearn, MerGE" (SPUNGE), a framework that can be used with any unlearning method to amplify its effectiveness. SPUNGE leverages data attributes during unlearning by splitting unlearning data into subsets based on specific attribute values, unlearning each subset separately, and merging the unlearned models. We empirically demonstrate that SPUNGE significantly improves the performance of two recent unlearning methods on state-of-the-art LLMs while maintaining their general capabilities on standard academic benchmarks.