 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVID-WIN: Fast Video Event Matching with Query-Aware Windowing at the Edge for the Internet of Multimedia Things
Apr 27, 2021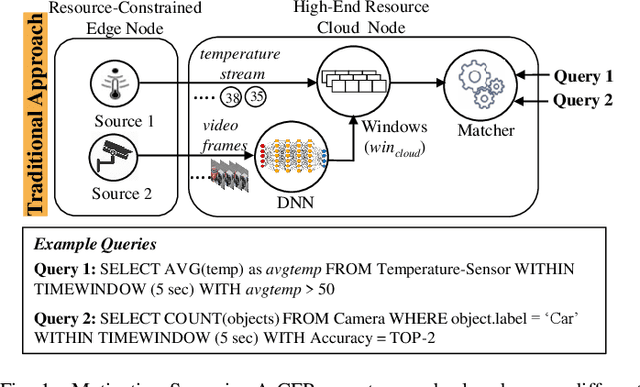
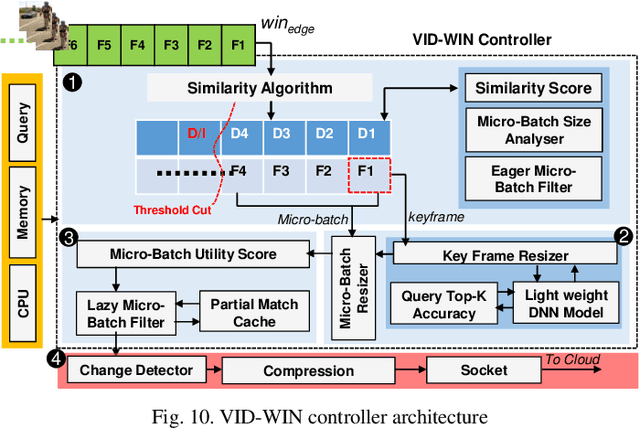
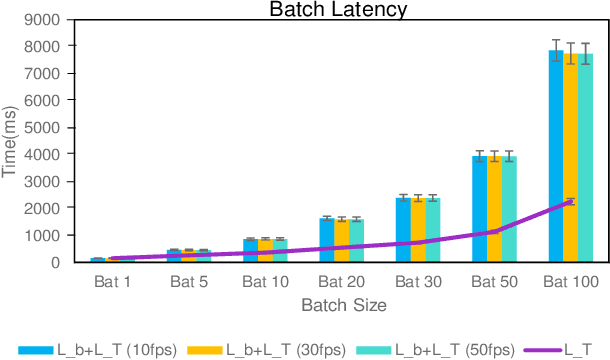
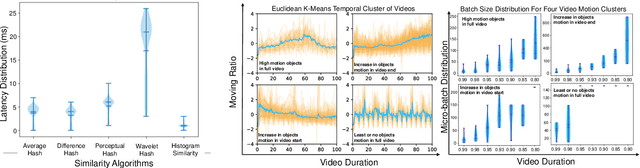
Efficient video processing is a critical component in many IoMT applications to detect events of interest. Presently, many window optimization techniques have been proposed in event processing with an underlying assumption that the incoming stream has a structured data model. Videos are highly complex due to the lack of any underlying structured data model. Video stream sources such as CCTV cameras and smartphones are resource-constrained edge nodes. At the same time, video content extraction is expensive and requires computationally intensive Deep Neural Network (DNN) models that are primarily deployed at high-end (or cloud) nodes. This paper presents VID-WIN, an adaptive 2-stage allied windowing approach to accelerate video event analytics in an edge-cloud paradigm. VID-WIN runs parallelly across edge and cloud nodes and performs the query and resource-aware optimization for state-based complex event matching. VID-WIN exploits the video content and DNN input knobs to accelerate the video inference process across nodes. The paper proposes a novel content-driven micro-batch resizing, queryaware caching and micro-batch based utility filtering strategy of video frames under resource-constrained edge nodes to improve the overall system throughput, latency, and network usage. Extensive evaluations are performed over five real-world datasets. The experimental results show that VID-WIN video event matching achieves ~2.3X higher throughput with minimal latency and ~99% bandwidth reduction compared to other baselines while maintaining query-level accuracy and resource bounds.
MuSeM: Detecting Incongruent News Headlines using Mutual Attentive Semantic Matching
Oct 07, 2020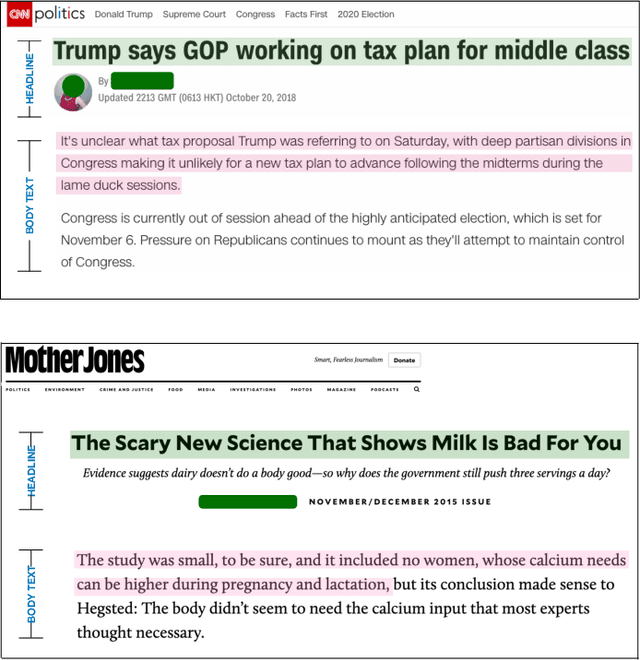
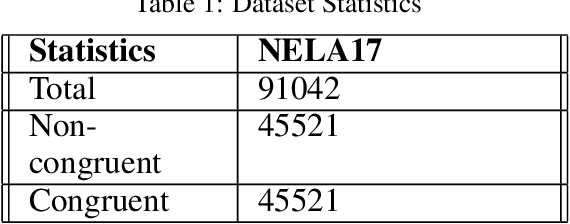
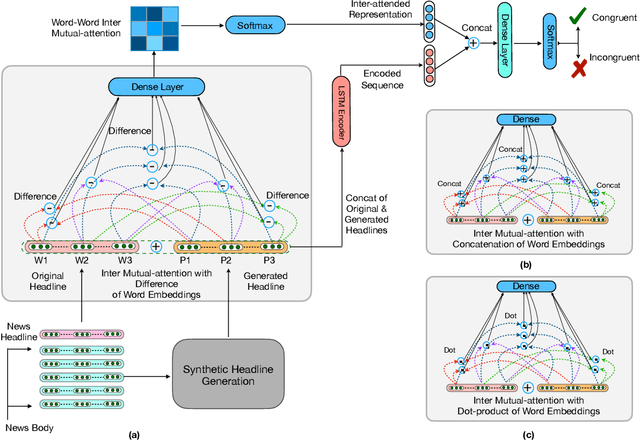
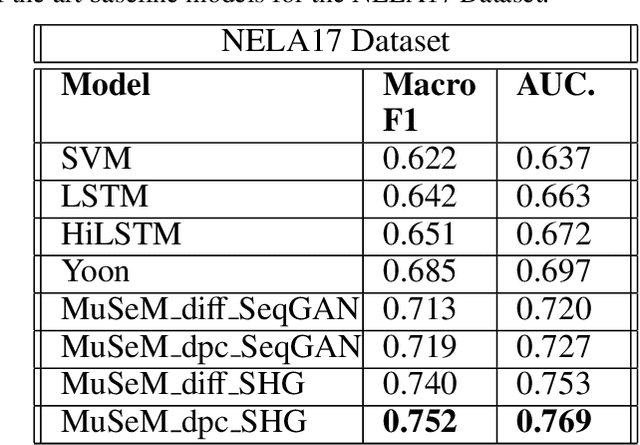
Measuring the congruence between two texts has several useful applications, such as detecting the prevalent deceptive and misleading news headlines on the web. Many works have proposed machine learning based solutions such as text similarity between the headline and body text to detect the incongruence. Text similarity based methods fail to perform well due to different inherent challenges such as relative length mismatch between the news headline and its body content and non-overlapping vocabulary. On the other hand, more recent works that use headline guided attention to learn a headline derived contextual representation of the news body also result in convoluting overall representation due to the news body's lengthiness. This paper proposes a method that uses inter-mutual attention-based semantic matching between the original and synthetically generated headlines, which utilizes the difference between all pairs of word embeddings of words involved. The paper also investigates two more variations of our method, which use concatenation and dot-products of word embeddings of the words of original and synthetic headlines. We observe that the proposed method outperforms prior arts significantly for two publicly available datasets.
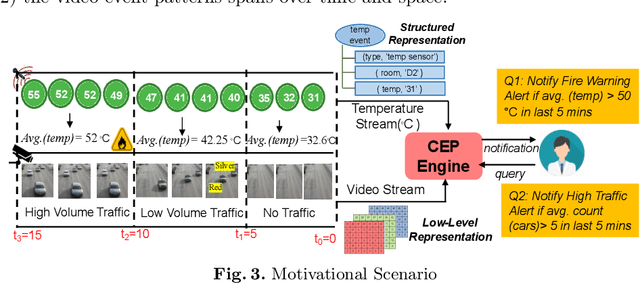
Visual Semantic Multimedia Event Model for Complex Event Detection in Video Streams
Sep 30, 2020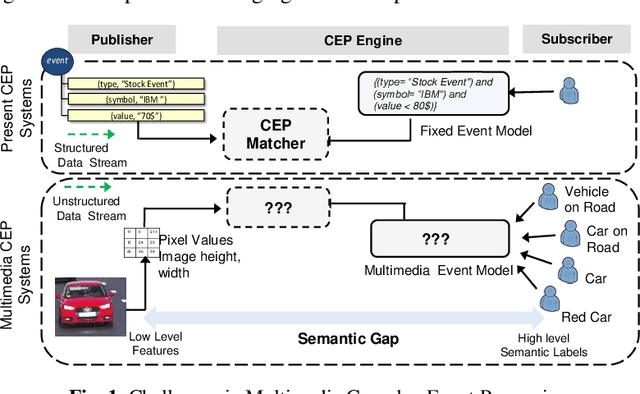



Multimedia data is highly expressive and has traditionally been very difficult for a machine to interpret. Middleware systems such as complex event processing (CEP) mine patterns from data streams and send notifications to users in a timely fashion. Presently, CEP systems have inherent limitations to process multimedia streams due to its data complexity and the lack of an underlying structured data model. In this work, we present a visual event specification method to enable complex multimedia event processing by creating a semantic knowledge representation derived from low-level media streams. The method enables the detection of high-level semantic concepts from the media streams using an ensemble of pattern detection capabilities. The semantic model is aligned with a multimedia CEP engine deep learning models to give flexibility to end-users to build rules using spatiotemporal event calculus. This enhances CEP capability to detect patterns from media streams and bridge the semantic gap between highly expressive knowledge-centric user queries to the low-level features of the multi-media data. We have built a small traffic event ontology prototype to validate the approach and performance. The paper contribution is threefold: i) we present a knowledge graph representation for multimedia streams, ii) a hierarchical event network to detect visual patterns from media streams and iii) define complex pattern rules for complex multimedia event reasoning using event calculus
VidCEP: Complex Event Processing Framework to Detect Spatiotemporal Patterns in Video Streams
Jul 15, 2020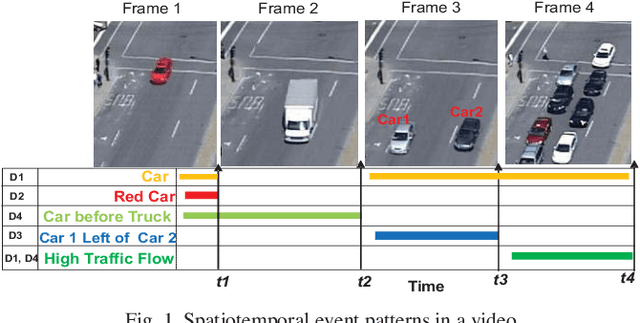

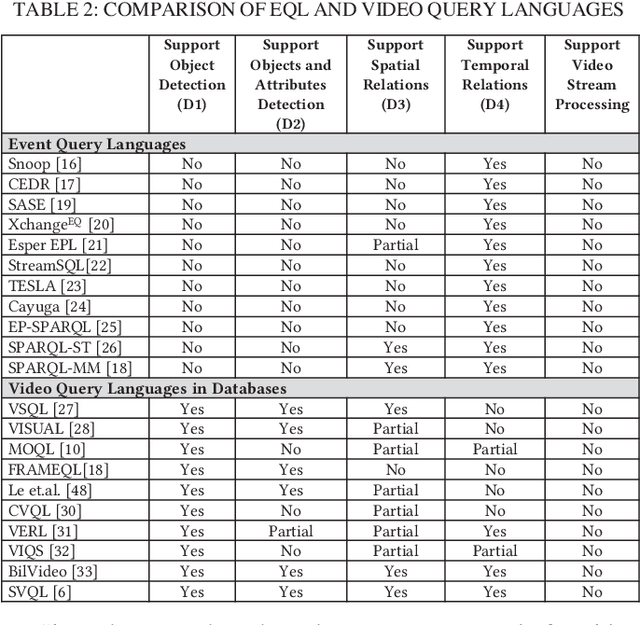

Video data is highly expressive and has traditionally been very difficult for a machine to interpret. Querying event patterns from video streams is challenging due to its unstructured representation. Middleware systems such as Complex Event Processing (CEP) mine patterns from data streams and send notifications to users in a timely fashion. Current CEP systems have inherent limitations to query video streams due to their unstructured data model and lack of expressive query language. In this work, we focus on a CEP framework where users can define high-level expressive queries over videos to detect a range of spatiotemporal event patterns. In this context, we propose: i) VidCEP, an in-memory, on the fly, near real-time complex event matching framework for video streams. The system uses a graph-based event representation for video streams which enables the detection of high-level semantic concepts from video using cascades of Deep Neural Network models, ii) a Video Event Query language (VEQL) to express high-level user queries for video streams in CEP, iii) a complex event matcher to detect spatiotemporal video event patterns by matching expressive user queries over video data. The proposed approach detects spatiotemporal video event patterns with an F-score ranging from 0.66 to 0.89. VidCEP maintains near real-time performance with an average throughput of 70 frames per second for 5 parallel videos with sub-second matching latency.
Knowledge Graph Driven Approach to Represent Video Streams for Spatiotemporal Event Pattern Matching in Complex Event Processing
Jul 13, 2020
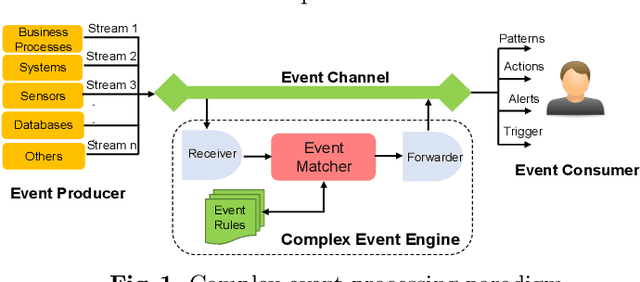

Complex Event Processing (CEP) is an event processing paradigm to perform real-time analytics over streaming data and match high-level event patterns. Presently, CEP is limited to process structured data stream. Video streams are complicated due to their unstructured data model and limit CEP systems to perform matching over them. This work introduces a graph-based structure for continuous evolving video streams, which enables the CEP system to query complex video event patterns. We propose the Video Event Knowledge Graph (VEKG), a graph driven representation of video data. VEKG models video objects as nodes and their relationship interaction as edges over time and space. It creates a semantic knowledge representation of video data derived from the detection of high-level semantic concepts from the video using an ensemble of deep learning models. A CEP-based state optimization - VEKG-Time Aggregated Graph (VEKG-TAG) is proposed over VEKG representation for faster event detection. VEKG-TAG is a spatiotemporal graph aggregation method that provides a summarized view of the VEKG graph over a given time length. We defined a set of nine event pattern rules for two domains (Activity Recognition and Traffic Management), which act as a query and applied over VEKG graphs to discover complex event patterns. To show the efficacy of our approach, we performed extensive experiments over 801 video clips across 10 datasets. The proposed VEKG approach was compared with other state-of-the-art methods and was able to detect complex event patterns over videos with F-Score ranging from 0.44 to 0.90. In the given experiments, the optimized VEKG-TAG was able to reduce 99% and 93% of VEKG nodes and edges, respectively, with 5.19X faster search time, achieving sub-second median latency of 4-20 milliseconds.
Human Assisted Artificial Intelligence Based Technique to Create Natural Features for OpenStreetMap
Jul 08, 2020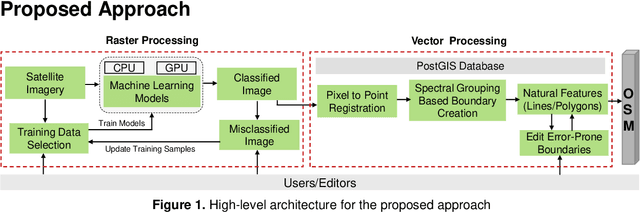

In this work, we propose an AI-based technique using freely available satellite images like Landsat and Sentinel to create natural features over OSM in congruence with human editors acting as initiators and validators. The method is based on Interactive Machine Learning technique where human inputs are coupled with the machine to solve complex problems efficiently as compare to pure autonomous process. We use a bottom-up approach where a machine learning (ML) pipeline in loop with editors is used to extract classes using spectral signatures of images and later convert them to editable features to create natural features.