 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayes-PD: Exploring a Sequence to Binding Bayesian Neural Network model trained on Phage Display data
Jan 07, 2026Phage display is a powerful laboratory technique used to study the interactions between proteins and other molecules, whether other proteins, peptides, DNA or RNA. The under-utilisation of this data in conjunction with deep learning models for protein design may be attributed to; high experimental noise levels; the complex nature of data pre-processing; and difficulty interpreting these experimental results. In this work, we propose a novel approach utilising a Bayesian Neural Network within a training loop, in order to simulate the phage display experiment and its associated noise. Our goal is to investigate how understanding the experimental noise and model uncertainty can enable the reliable application of such models to reliably interpret phage display experiments. We validate our approach using actual binding affinity measurements instead of relying solely on proxy values derived from 'held-out' phage display rounds.
GeoGraph: Geometric and Graph-based Ensemble Descriptors for Intrinsically Disordered Proteins
Oct 01, 2025While deep learning has revolutionized the prediction of rigid protein structures, modelling the conformational ensembles of Intrinsically Disordered Proteins (IDPs) remains a key frontier. Current AI paradigms present a trade-off: Protein Language Models (PLMs) capture evolutionary statistics but lack explicit physical grounding, while generative models trained to model full ensembles are computationally expensive. In this work we critically assess these limits and propose a path forward. We introduce GeoGraph, a simulation-informed surrogate trained to predict ensemble-averaged statistics of residue-residue contact-map topology directly from sequence. By featurizing coarse-grained molecular dynamics simulations into residue- and sequence-level graph descriptors, we create a robust and information-rich learning target. Our evaluation demonstrates that this approach yields representations that are more predictive of key biophysical properties than existing methods.
Discriminative protein sequence modelling with Latent Space Diffusion
Mar 24, 2025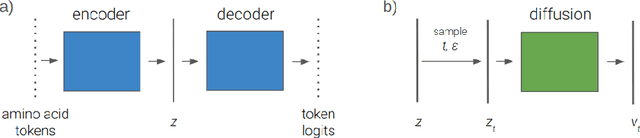



We explore a framework for protein sequence representation learning that decomposes the task between manifold learning and distributional modelling. Specifically we present a Latent Space Diffusion architecture which combines a protein sequence autoencoder with a denoising diffusion model operating on its latent space. We obtain a one-parameter family of learned representations from the diffusion model, along with the autoencoder's latent representation. We propose and evaluate two autoencoder architectures: a homogeneous model forcing amino acids of the same type to be identically distributed in the latent space, and an inhomogeneous model employing a noise-based variant of masking. As a baseline we take a latent space learned by masked language modelling, and evaluate discriminative capability on a range of protein property prediction tasks. Our finding is twofold: the diffusion models trained on both our proposed variants display higher discriminative power than the one trained on the masked language model baseline, none of the diffusion representations achieve the performance of the masked language model embeddings themselves.
Metalic: Meta-Learning In-Context with Protein Language Models
Oct 10, 2024
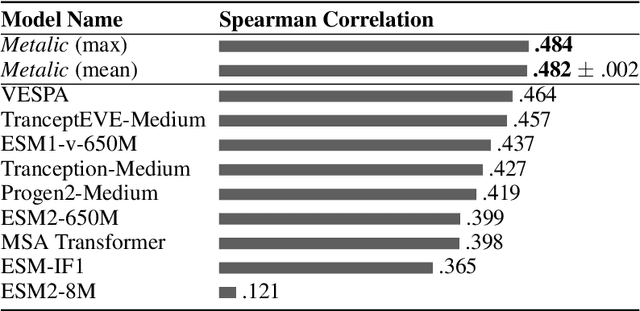
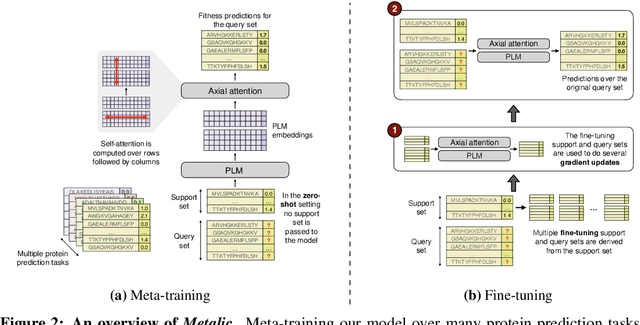

Predicting the biophysical and functional properties of proteins is essential for in silico protein design. Machine learning has emerged as a promising technique for such prediction tasks. However, the relative scarcity of in vitro annotations means that these models often have little, or no, specific data on the desired fitness prediction task. As a result of limited data, protein language models (PLMs) are typically trained on general protein sequence modeling tasks, and then fine-tuned, or applied zero-shot, to protein fitness prediction. When no task data is available, the models make strong assumptions about the correlation between the protein sequence likelihood and fitness scores. In contrast, we propose meta-learning over a distribution of standard fitness prediction tasks, and demonstrate positive transfer to unseen fitness prediction tasks. Our method, called Metalic (Meta-Learning In-Context), uses in-context learning and fine-tuning, when data is available, to adapt to new tasks. Crucially, fine-tuning enables considerable generalization, even though it is not accounted for during meta-training. Our fine-tuned models achieve strong results with 18 times fewer parameters than state-of-the-art models. Moreover, our method sets a new state-of-the-art in low-data settings on ProteinGym, an established fitness-prediction benchmark. Due to data scarcity, we believe meta-learning will play a pivotal role in advancing protein engineering.
Protein binding affinity prediction under multiple substitutions applying eGNNs on Residue and Atomic graphs combined with Language model information: eGRAL
May 03, 2024Protein-protein interactions (PPIs) play a crucial role in numerous biological processes. Developing methods that predict binding affinity changes under substitution mutations is fundamental for modelling and re-engineering biological systems. Deep learning is increasingly recognized as a powerful tool capable of bridging the gap between in-silico predictions and in-vitro observations. With this contribution, we propose eGRAL, a novel SE(3) equivariant graph neural network (eGNN) architecture designed for predicting binding affinity changes from multiple amino acid substitutions in protein complexes. eGRAL leverages residue, atomic and evolutionary scales, thanks to features extracted from protein large language models. To address the limited availability of large-scale affinity assays with structural information, we generate a simulated dataset comprising approximately 500,000 data points. Our model is pre-trained on this dataset, then fine-tuned and tested on experimental data.
Predicting protein stability changes under multiple amino acid substitutions using equivariant graph neural networks
May 30, 2023



The accurate prediction of changes in protein stability under multiple amino acid substitutions is essential for realising true in-silico protein re-design. To this purpose, we propose improvements to state-of-the-art Deep learning (DL) protein stability prediction models, enabling first-of-a-kind predictions for variable numbers of amino acid substitutions, on structural representations, by decoupling the atomic and residue scales of protein representations. This was achieved using E(3)-equivariant graph neural networks (EGNNs) for both atomic environment (AE) embedding and residue-level scoring tasks. Our AE embedder was used to featurise a residue-level graph, then trained to score mutant stability ($\Delta\Delta G$). To achieve effective training of this predictive EGNN we have leveraged the unprecedented scale of a new high-throughput protein stability experimental data-set, Mega-scale. Finally, we demonstrate the immediately promising results of this procedure, discuss the current shortcomings, and highlight potential future strategies.
BON: An extended public domain dataset for human activity recognition
Sep 12, 2022



Body-worn first-person vision (FPV) camera enables to extract a rich source of information on the environment from the subject's viewpoint. However, the research progress in wearable camera-based egocentric office activity understanding is slow compared to other activity environments (e.g., kitchen and outdoor ambulatory), mainly due to the lack of adequate datasets to train more sophisticated (e.g., deep learning) models for human activity recognition in office environments. This paper provides details of a large and publicly available office activity dataset (BON) collected in different office settings across three geographical locations: Barcelona (Spain), Oxford (UK) and Nairobi (Kenya), using a chest-mounted GoPro Hero camera. The BON dataset contains eighteen common office activities that can be categorised into person-to-person interactions (e.g., Chat with colleagues), person-to-object (e.g., Writing on a whiteboard), and proprioceptive (e.g., Walking). Annotation is provided for each segment of video with 5-seconds duration. Generally, BON contains 25 subjects and 2639 total segments. In order to facilitate further research in the sub-domain, we have also provided results that could be used as baselines for future studies.
WNTRAC: Artificial Intelligence Assisted Tracking of Non-pharmaceutical Interventions Implemented Worldwide for COVID-19
Sep 16, 2020



The Coronavirus disease 2019 (COVID-19) global pandemic has transformed almost every facet of human society throughout the world. Against an emerging, highly transmissible disease with no definitive treatment or vaccine, governments worldwide have implemented non-pharmaceutical intervention (NPI) to slow the spread of the virus. Examples of such interventions include community actions (e.g. school closures, restrictions on mass gatherings), individual actions (e.g. mask wearing, self-quarantine), and environmental actions (e.g. public facility cleaning). We present the Worldwide Non-pharmaceutical Interventions Tracker for COVID-19 (WNTRAC), a comprehensive dataset consisting of over 6,000 NPIs implemented worldwide since the start of the pandemic. WNTRAC covers NPIs implemented across 261 countries and territories, and classifies NPI measures into a taxonomy of sixteen NPI types. NPI measures are automatically extracted daily from Wikipedia articles using natural language processing techniques and manually validated to ensure accuracy and veracity. We hope that the dataset is valuable for policymakers, public health leaders, and researchers in modeling and analysis efforts for controlling the spread of COVID-19.
Novel Exploration Techniques (NETs) for Malaria Policy Interventions
Dec 01, 2017
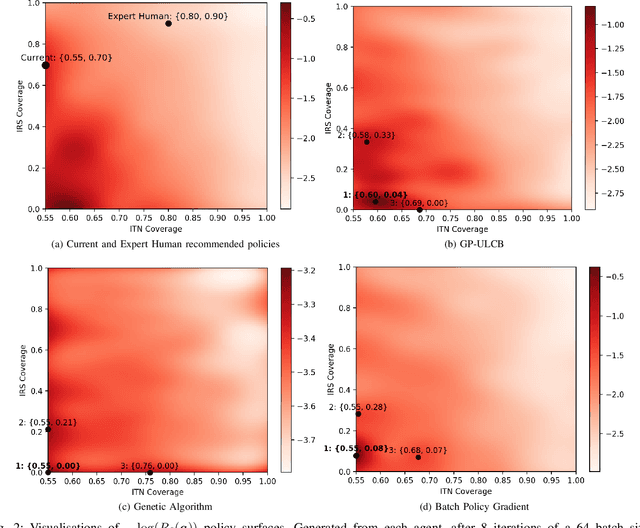

The task of decision-making under uncertainty is daunting, especially for problems which have significant complexity. Healthcare policy makers across the globe are facing problems under challenging constraints, with limited tools to help them make data driven decisions. In this work we frame the process of finding an optimal malaria policy as a stochastic multi-armed bandit problem, and implement three agent based strategies to explore the policy space. We apply a Gaussian Process regression to the findings of each agent, both for comparison and to account for stochastic results from simulating the spread of malaria in a fixed population. The generated policy spaces are compared with published results to give a direct reference with human expert decisions for the same simulated population. Our novel approach provides a powerful resource for policy makers, and a platform which can be readily extended to capture future more nuanced policy spaces.