 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetalic: Meta-Learning In-Context with Protein Language Models
Oct 10, 2024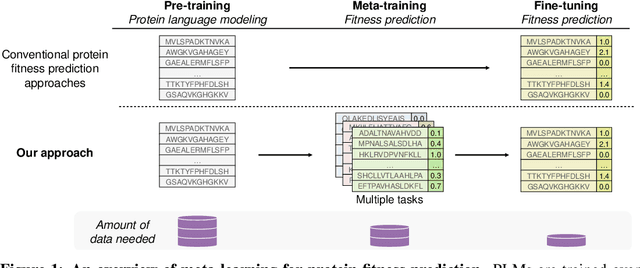
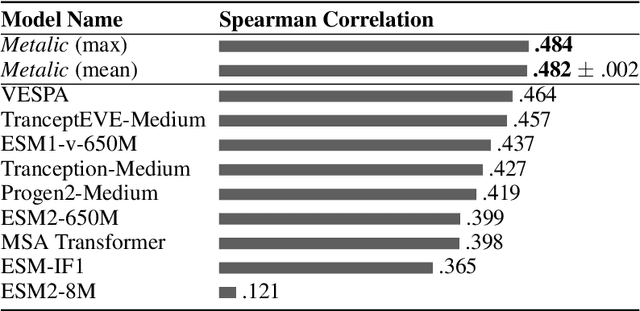
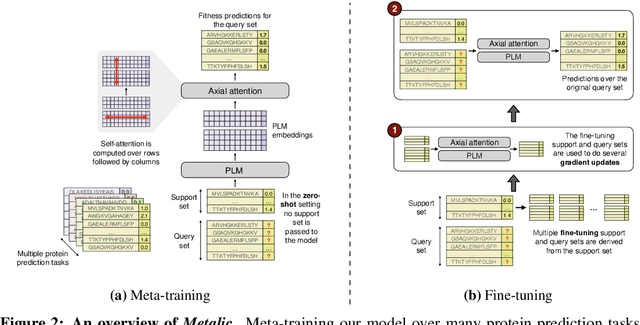

Predicting the biophysical and functional properties of proteins is essential for in silico protein design. Machine learning has emerged as a promising technique for such prediction tasks. However, the relative scarcity of in vitro annotations means that these models often have little, or no, specific data on the desired fitness prediction task. As a result of limited data, protein language models (PLMs) are typically trained on general protein sequence modeling tasks, and then fine-tuned, or applied zero-shot, to protein fitness prediction. When no task data is available, the models make strong assumptions about the correlation between the protein sequence likelihood and fitness scores. In contrast, we propose meta-learning over a distribution of standard fitness prediction tasks, and demonstrate positive transfer to unseen fitness prediction tasks. Our method, called Metalic (Meta-Learning In-Context), uses in-context learning and fine-tuning, when data is available, to adapt to new tasks. Crucially, fine-tuning enables considerable generalization, even though it is not accounted for during meta-training. Our fine-tuned models achieve strong results with 18 times fewer parameters than state-of-the-art models. Moreover, our method sets a new state-of-the-art in low-data settings on ProteinGym, an established fitness-prediction benchmark. Due to data scarcity, we believe meta-learning will play a pivotal role in advancing protein engineering.
Policy Gradient RL Algorithms as Directed Acyclic Graphs
Jan 16, 2021
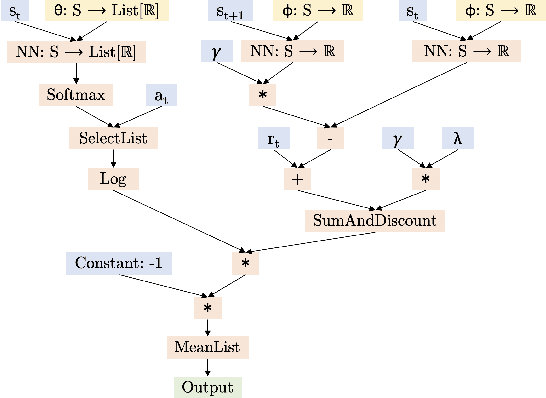
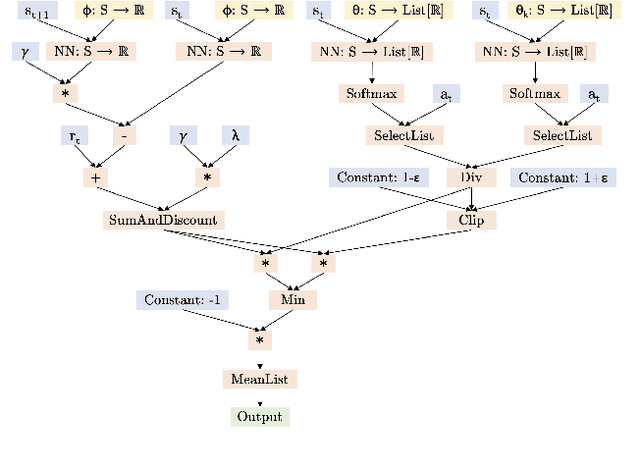

Meta Reinforcement Learning (RL) methods focus on automating the design of RL algorithms that generalize to a wide range of environments. The framework introduced in (Anonymous, 2020) addresses the problem by representing different RL algorithms as Directed Acyclic Graphs (DAGs), and using an evolutionary meta learner to modify these graphs and find good agent update rules. While the search language used to generate graphs in the paper serves to represent numerous already-existing RL algorithms (e.g., DQN, DDQN), it has limitations when it comes to representing Policy Gradient algorithms. In this work we try to close this gap by extending the original search language and proposing graphs for five different Policy Gradient algorithms: VPG, PPO, DDPG, TD3, and SAC.
Applicability and Challenges of Deep Reinforcement Learning for Satellite Frequency Plan Design
Oct 15, 2020
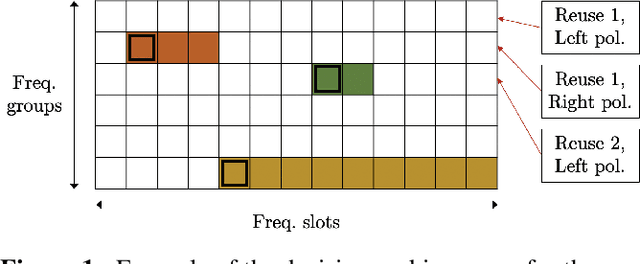


The study and benchmarking of Deep Reinforcement Learning (DRL) models has become a trend in many industries, including aerospace engineering and communications. Recent studies in these fields propose these kinds of models to address certain complex real-time decision-making problems in which classic approaches do not meet time requirements or fail to obtain optimal solutions. While the good performance of DRL models has been proved for specific use cases or scenarios, most studies do not discuss the compromises of such models. In this paper we explore the tradeoffs of different elements of DRL models and how they might impact the final performance. To that end, we choose the Frequency Plan Design (FPD) problem in the context of multibeam satellite constellations as our use case and propose a DRL model to address it. We identify six different core elements that have a major effect in its performance: the policy, the policy optimizer, the state, action, and reward representations, and the training environment. We analyze different alternatives for each of these elements and characterize their effect. We also use multiple environments to account for different scenarios in which we vary the dimensionality or make the environment non-stationary. Our findings show that DRL is a potential method to address the FPD problem in real operations, especially because of its speed in decision-making. However, no single DRL model is able to outperform the rest in all scenarios, and the best approach for each of the six core elements depends on the features of the operation environment. While we agree on the potential of DRL to solve future complex problems in the aerospace industry, we also reflect on the importance of designing appropriate models and training procedures, understanding the applicability of such models, and reporting the main performance tradeoffs.
Deep Reinforcement Learning Architecture for Continuous Power Allocation in High Throughput Satellites
Jun 03, 2019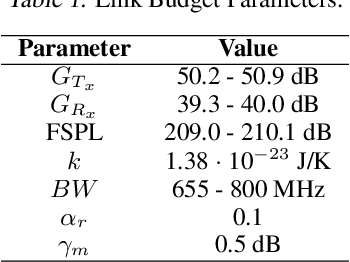
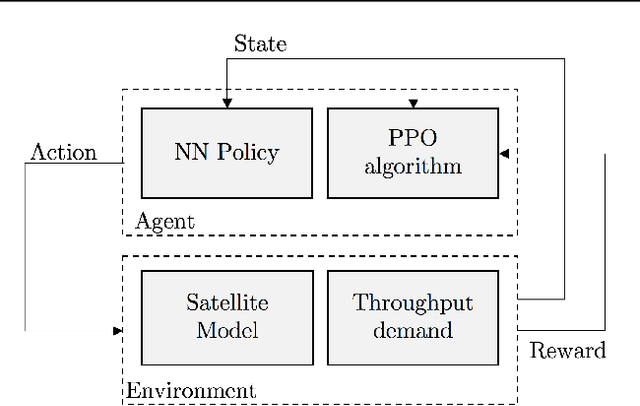

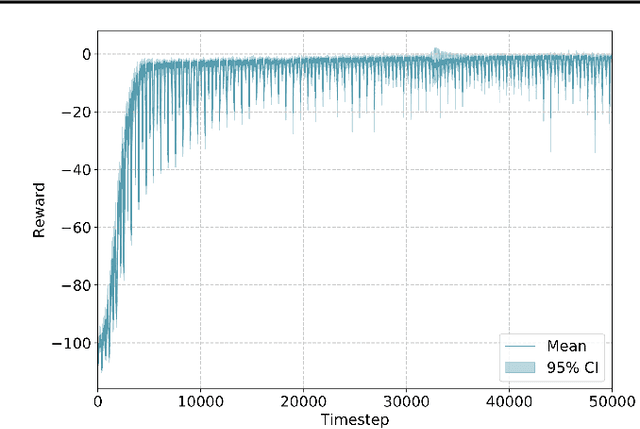
In the coming years, the satellite broadband market will experience significant increases in the service demand, especially for the mobility sector, where demand is burstier. Many of the next generation of satellites will be equipped with numerous degrees of freedom in power and bandwidth allocation capabilities, making manual resource allocation impractical and inefficient. Therefore, it is desirable to automate the operation of these highly flexible satellites. This paper presents a novel power allocation approach based on Deep Reinforcement Learning (DRL) that represents the problem as continuous state and action spaces. We make use of the Proximal Policy Optimization (PPO) algorithm to optimize the allocation policy for minimum Unmet System Demand (USD) and power consumption. The performance of the algorithm is analyzed through simulations of a multibeam satellite system, which show promising results for DRL to be used as a dynamic resource allocation algorithm.