 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Satellite Communications: An AI-based Framework to Address System-level Challenges
Dec 11, 2021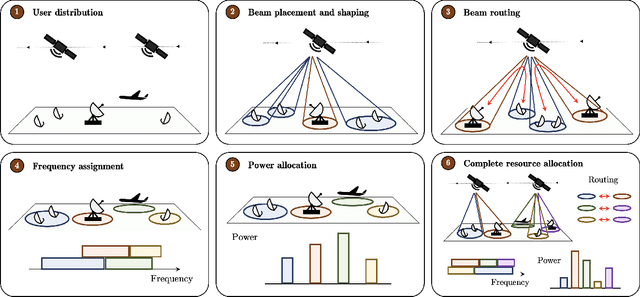
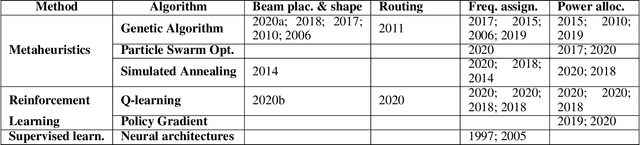
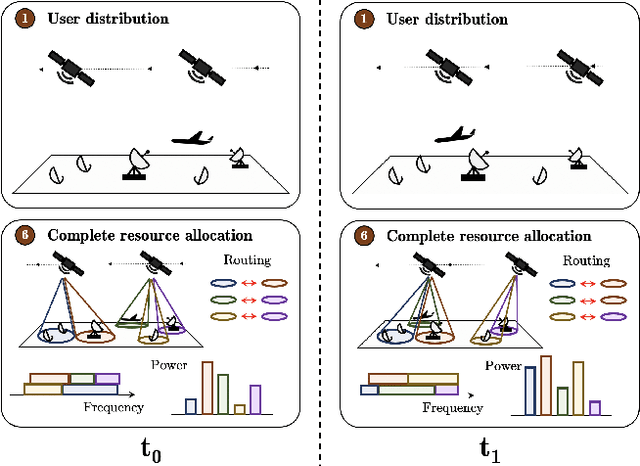

The next generation of satellite constellations is designed to better address the future needs of our connected society: highly-variable data demand, mobile connectivity, and reaching more under-served regions. Artificial Intelligence (AI) and learning-based methods are expected to become key players in the industry, given the poor scalability and slow reaction time of current resource allocation mechanisms. While AI frameworks have been validated for isolated communication tasks or subproblems, there is still not a clear path to achieve fully-autonomous satellite systems. Part of this issue results from the focus on subproblems when designing models, instead of the necessary system-level perspective. In this paper we try to bridge this gap by characterizing the system-level needs that must be met to increase satellite autonomy, and introduce three AI-based components (Demand Estimator, Offline Planner, and Real Time Engine) that jointly address them. We first do a broad literature review on the different subproblems and identify the missing links to the system-level goals. In response to these gaps, we outline the three necessary components and highlight their interactions. We also discuss how current models can be incorporated into the framework and possible directions of future work.
Evaluating the progress of Deep Reinforcement Learning in the real world: aligning domain-agnostic and domain-specific research
Jul 07, 2021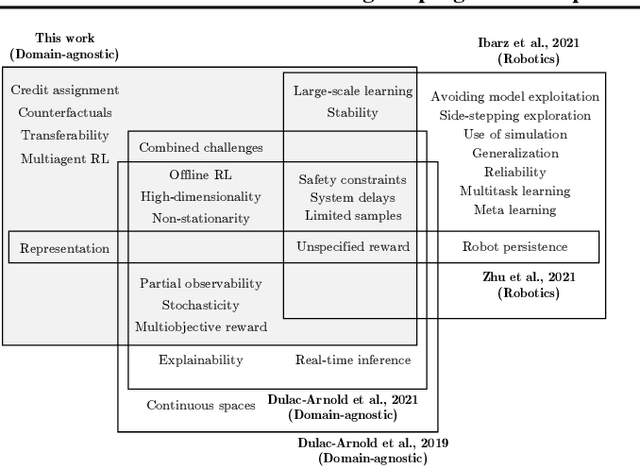
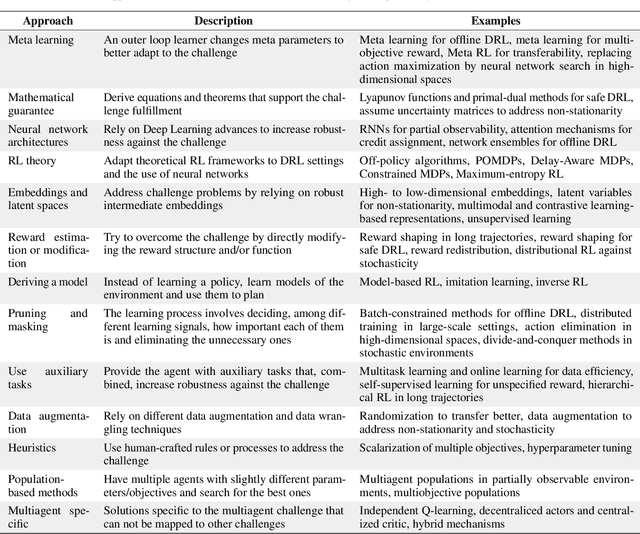
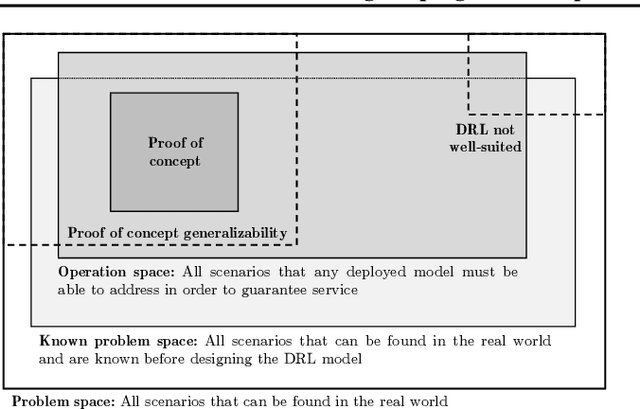
Deep Reinforcement Learning (DRL) is considered a potential framework to improve many real-world autonomous systems; it has attracted the attention of multiple and diverse fields. Nevertheless, the successful deployment in the real world is a test most of DRL models still need to pass. In this work we focus on this issue by reviewing and evaluating the research efforts from both domain-agnostic and domain-specific communities. On one hand, we offer a comprehensive summary of DRL challenges and summarize the different proposals to mitigate them; this helps identifying five gaps of domain-agnostic research. On the other hand, from the domain-specific perspective, we discuss different success stories and argue why other models might fail to be deployed. Finally, we take up on ways to move forward accounting for both perspectives.
Applicability and Challenges of Deep Reinforcement Learning for Satellite Frequency Plan Design
Oct 15, 2020
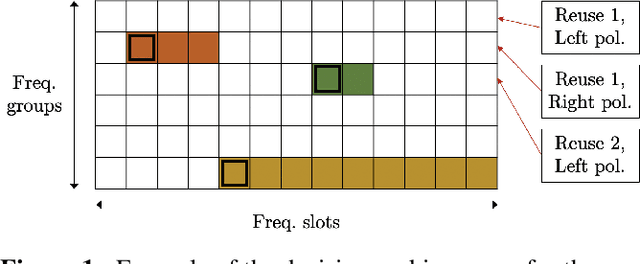


The study and benchmarking of Deep Reinforcement Learning (DRL) models has become a trend in many industries, including aerospace engineering and communications. Recent studies in these fields propose these kinds of models to address certain complex real-time decision-making problems in which classic approaches do not meet time requirements or fail to obtain optimal solutions. While the good performance of DRL models has been proved for specific use cases or scenarios, most studies do not discuss the compromises of such models. In this paper we explore the tradeoffs of different elements of DRL models and how they might impact the final performance. To that end, we choose the Frequency Plan Design (FPD) problem in the context of multibeam satellite constellations as our use case and propose a DRL model to address it. We identify six different core elements that have a major effect in its performance: the policy, the policy optimizer, the state, action, and reward representations, and the training environment. We analyze different alternatives for each of these elements and characterize their effect. We also use multiple environments to account for different scenarios in which we vary the dimensionality or make the environment non-stationary. Our findings show that DRL is a potential method to address the FPD problem in real operations, especially because of its speed in decision-making. However, no single DRL model is able to outperform the rest in all scenarios, and the best approach for each of the six core elements depends on the features of the operation environment. While we agree on the potential of DRL to solve future complex problems in the aerospace industry, we also reflect on the importance of designing appropriate models and training procedures, understanding the applicability of such models, and reporting the main performance tradeoffs.
Deep Reinforcement Learning Architecture for Continuous Power Allocation in High Throughput Satellites
Jun 03, 2019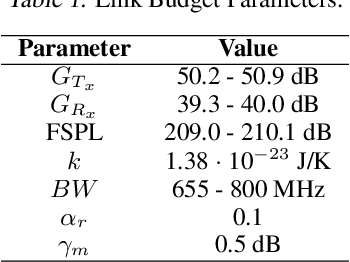
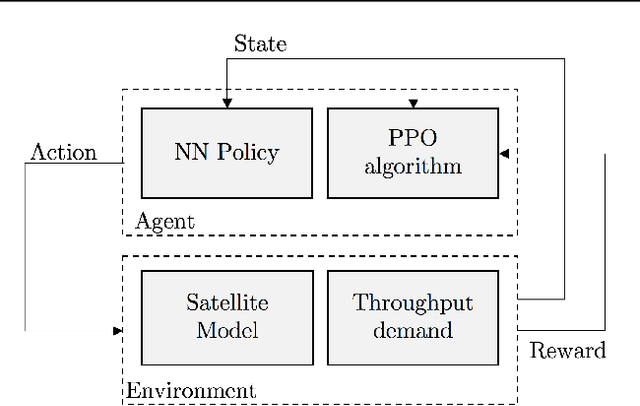

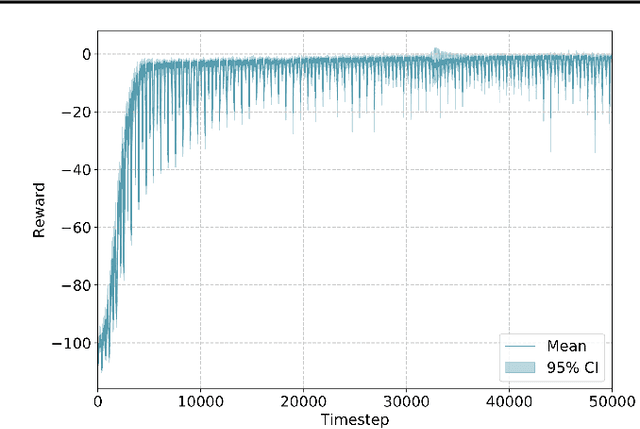
In the coming years, the satellite broadband market will experience significant increases in the service demand, especially for the mobility sector, where demand is burstier. Many of the next generation of satellites will be equipped with numerous degrees of freedom in power and bandwidth allocation capabilities, making manual resource allocation impractical and inefficient. Therefore, it is desirable to automate the operation of these highly flexible satellites. This paper presents a novel power allocation approach based on Deep Reinforcement Learning (DRL) that represents the problem as continuous state and action spaces. We make use of the Proximal Policy Optimization (PPO) algorithm to optimize the allocation policy for minimum Unmet System Demand (USD) and power consumption. The performance of the algorithm is analyzed through simulations of a multibeam satellite system, which show promising results for DRL to be used as a dynamic resource allocation algorithm.