 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplicability and Challenges of Deep Reinforcement Learning for Satellite Frequency Plan Design
Paper and Code
Oct 15, 2020
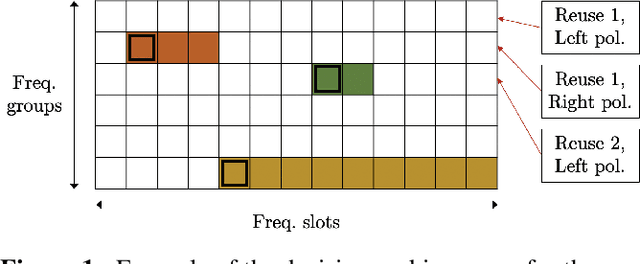


The study and benchmarking of Deep Reinforcement Learning (DRL) models has become a trend in many industries, including aerospace engineering and communications. Recent studies in these fields propose these kinds of models to address certain complex real-time decision-making problems in which classic approaches do not meet time requirements or fail to obtain optimal solutions. While the good performance of DRL models has been proved for specific use cases or scenarios, most studies do not discuss the compromises of such models. In this paper we explore the tradeoffs of different elements of DRL models and how they might impact the final performance. To that end, we choose the Frequency Plan Design (FPD) problem in the context of multibeam satellite constellations as our use case and propose a DRL model to address it. We identify six different core elements that have a major effect in its performance: the policy, the policy optimizer, the state, action, and reward representations, and the training environment. We analyze different alternatives for each of these elements and characterize their effect. We also use multiple environments to account for different scenarios in which we vary the dimensionality or make the environment non-stationary. Our findings show that DRL is a potential method to address the FPD problem in real operations, especially because of its speed in decision-making. However, no single DRL model is able to outperform the rest in all scenarios, and the best approach for each of the six core elements depends on the features of the operation environment. While we agree on the potential of DRL to solve future complex problems in the aerospace industry, we also reflect on the importance of designing appropriate models and training procedures, understanding the applicability of such models, and reporting the main performance tradeoffs.