 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023
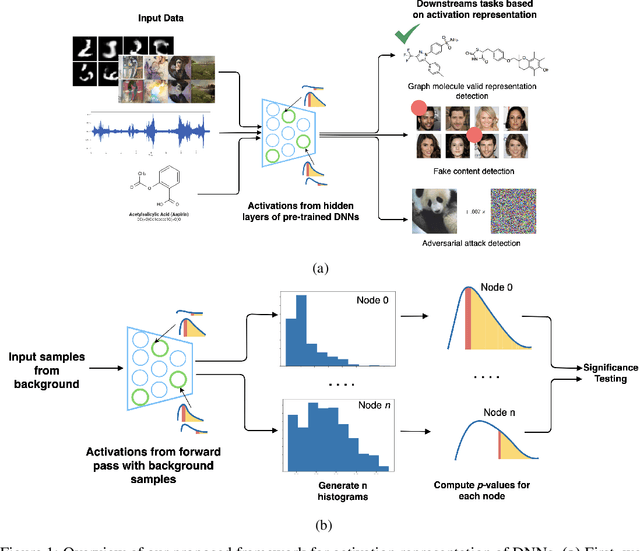

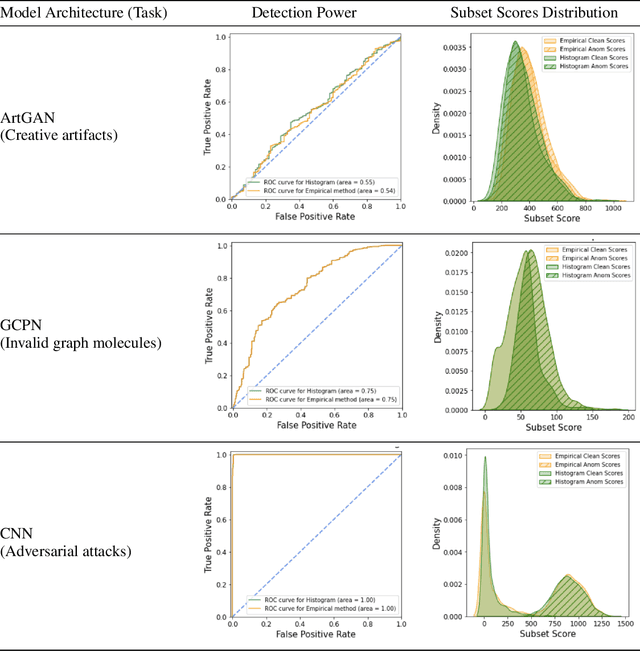
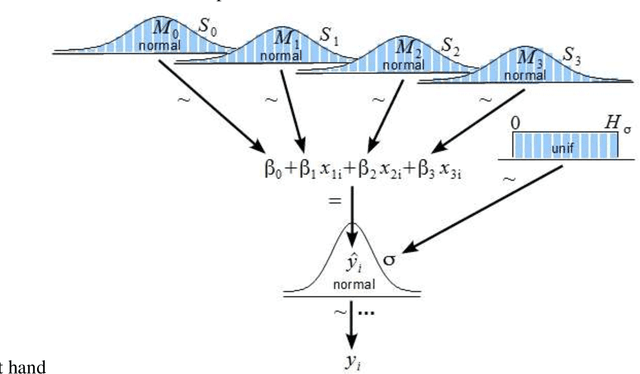
The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.
Model-Free Reinforcement Learning for Asset Allocation
Sep 21, 2022
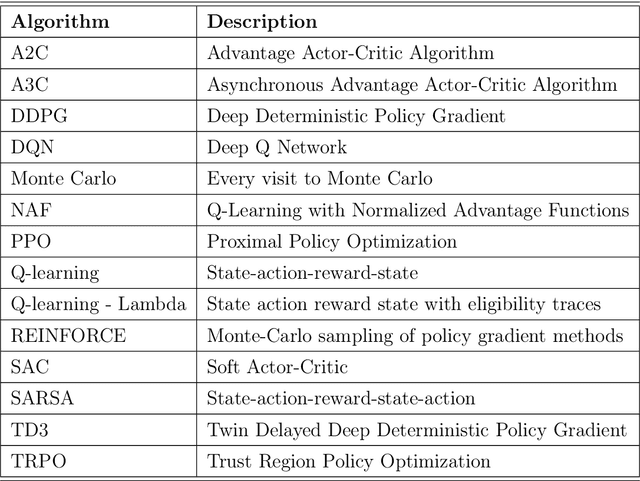
Asset allocation (or portfolio management) is the task of determining how to optimally allocate funds of a finite budget into a range of financial instruments/assets such as stocks. This study investigated the performance of reinforcement learning (RL) when applied to portfolio management using model-free deep RL agents. We trained several RL agents on real-world stock prices to learn how to perform asset allocation. We compared the performance of these RL agents against some baseline agents. We also compared the RL agents among themselves to understand which classes of agents performed better. From our analysis, RL agents can perform the task of portfolio management since they significantly outperformed two of the baseline agents (random allocation and uniform allocation). Four RL agents (A2C, SAC, PPO, and TRPO) outperformed the best baseline, MPT, overall. This shows the abilities of RL agents to uncover more profitable trading strategies. Furthermore, there were no significant performance differences between value-based and policy-based RL agents. Actor-critic agents performed better than other types of agents. Also, on-policy agents performed better than off-policy agents because they are better at policy evaluation and sample efficiency is not a significant problem in portfolio management. This study shows that RL agents can substantially improve asset allocation since they outperform strong baselines. On-policy, actor-critic RL agents showed the most promise based on our analysis.
Leak Detection in Natural Gas Pipeline Using Machine Learning Models
Sep 21, 2022
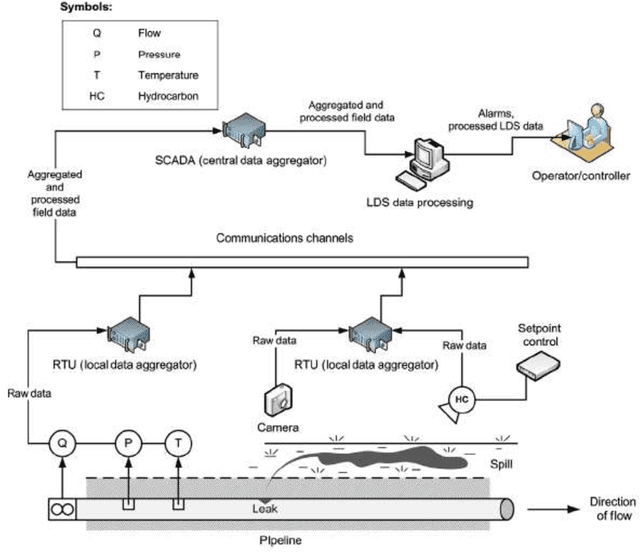
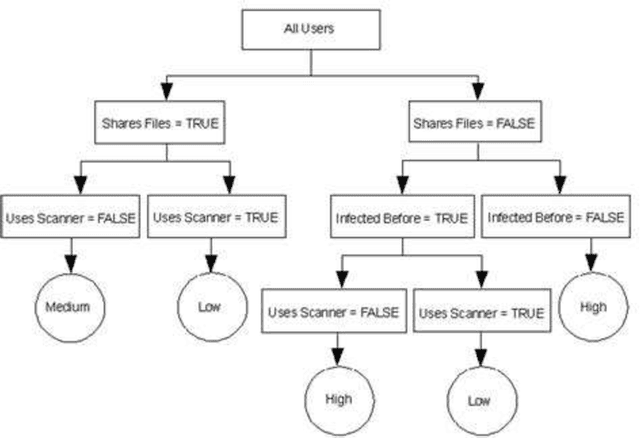
Leak detection in gas pipelines is an important and persistent problem in the Oil and Gas industry. This is particularly important as pipelines are the most common way of transporting natural gas. This research aims to study the ability of data-driven intelligent models to detect small leaks for a natural gas pipeline using basic operational parameters and then compare the intelligent models among themselves using existing performance metrics. This project applies the observer design technique to detect leaks in natural gas pipelines using a regressoclassification hierarchical model where an intelligent model acts as a regressor and a modified logistic regression model acts as a classifier. Five intelligent models (gradient boosting, decision trees, random forest, support vector machine and artificial neural network) are studied in this project using a pipeline data stream of four weeks. The results shows that while support vector machine and artificial neural networks are better regressors than the others, they do not provide the best results in leak detection due to their internal complexities and the volume of data used. The random forest and decision tree models are the most sensitive as they can detect a leak of 0.1% of nominal flow in about 2 hours. All the intelligent models had high reliability with zero false alarm rate in testing phase. The average time to leak detection for all the intelligent models was compared to a real time transient model in literature. The results show that intelligent models perform relatively well in the problem of leak detection. This result suggests that intelligent models could be used alongside a real time transient model to significantly improve leak detection results.
Extreme Multi-Domain, Multi-Task Learning With Unified Text-to-Text Transfer Transformers
Sep 21, 2022


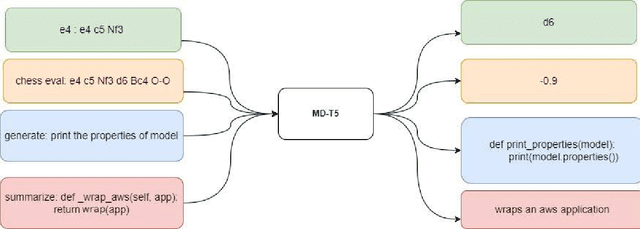
Text-to-text transformers have shown remarkable success in the task of multi-task transfer learning, especially in natural language processing (NLP). However, while there have been several attempts to train transformers on different domains, there is usually a clear relationship between these domains, e.g.,, code summarization, where the natural language summary describes the code. There have been very few attempts to study how multi-task transfer learning works on tasks in significantly different domains. In this project, we investigated the behavior of multi-domain, multi-task learning using multi-domain text-to-text transfer transformers (MD-T5) on four tasks across two domains - Python Code and Chess. We carried out extensive experiments using three popular training strategies: Bert-style joint pretraining + successive finetuning, GPT-style joint pretraining + successive finetuning, and GPT-style joint pretraining + joint finetuning. Also, we evaluate the model on four metrics - Play Score, Eval Score, BLEU Score, and Multi-Domain Learning Score (MDLS). These metrics measure performance across the various tasks and multi-domain learning. We show that while negative knowledge transfer and catastrophic forgetting are still considerable challenges for all the models, the GPT-style joint pretraining + joint finetuning strategy showed the most promise in multi-domain, multi-task learning as it performs well across all four tasks while still keeping its multi-domain knowledge.
Detection of Malicious Websites Using Machine Learning Techniques
Sep 13, 2022



In detecting malicious websites, a common approach is the use of blacklists which are not exhaustive in themselves and are unable to generalize to new malicious sites. Detecting newly encountered malicious websites automatically will help reduce the vulnerability to this form of attack. In this study, we explored the use of ten machine learning models to classify malicious websites based on lexical features and understand how they generalize across datasets. Specifically, we trained, validated, and tested these models on different sets of datasets and then carried out a cross-datasets analysis. From our analysis, we found that K-Nearest Neighbor is the only model that performs consistently high across datasets. Other models such as Random Forest, Decision Trees, Logistic Regression, and Support Vector Machines also consistently outperform a baseline model of predicting every link as malicious across all metrics and datasets. Also, we found no evidence that any subset of lexical features generalizes across models or datasets. This research should be relevant to cybersecurity professionals and academic researchers as it could form the basis for real-life detection systems or further research work.