 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Multi-Domain, Multi-Task Learning With Unified Text-to-Text Transfer Transformers
Sep 21, 2022


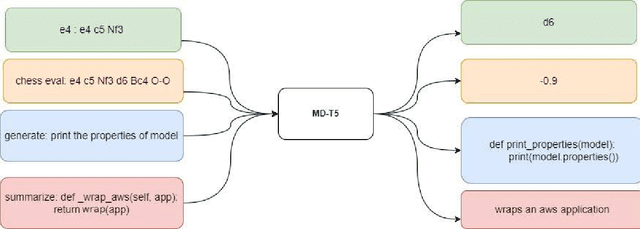
Text-to-text transformers have shown remarkable success in the task of multi-task transfer learning, especially in natural language processing (NLP). However, while there have been several attempts to train transformers on different domains, there is usually a clear relationship between these domains, e.g.,, code summarization, where the natural language summary describes the code. There have been very few attempts to study how multi-task transfer learning works on tasks in significantly different domains. In this project, we investigated the behavior of multi-domain, multi-task learning using multi-domain text-to-text transfer transformers (MD-T5) on four tasks across two domains - Python Code and Chess. We carried out extensive experiments using three popular training strategies: Bert-style joint pretraining + successive finetuning, GPT-style joint pretraining + successive finetuning, and GPT-style joint pretraining + joint finetuning. Also, we evaluate the model on four metrics - Play Score, Eval Score, BLEU Score, and Multi-Domain Learning Score (MDLS). These metrics measure performance across the various tasks and multi-domain learning. We show that while negative knowledge transfer and catastrophic forgetting are still considerable challenges for all the models, the GPT-style joint pretraining + joint finetuning strategy showed the most promise in multi-domain, multi-task learning as it performs well across all four tasks while still keeping its multi-domain knowledge.
Detection of Malicious Websites Using Machine Learning Techniques
Sep 13, 2022



In detecting malicious websites, a common approach is the use of blacklists which are not exhaustive in themselves and are unable to generalize to new malicious sites. Detecting newly encountered malicious websites automatically will help reduce the vulnerability to this form of attack. In this study, we explored the use of ten machine learning models to classify malicious websites based on lexical features and understand how they generalize across datasets. Specifically, we trained, validated, and tested these models on different sets of datasets and then carried out a cross-datasets analysis. From our analysis, we found that K-Nearest Neighbor is the only model that performs consistently high across datasets. Other models such as Random Forest, Decision Trees, Logistic Regression, and Support Vector Machines also consistently outperform a baseline model of predicting every link as malicious across all metrics and datasets. Also, we found no evidence that any subset of lexical features generalizes across models or datasets. This research should be relevant to cybersecurity professionals and academic researchers as it could form the basis for real-life detection systems or further research work.