 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free feature selection to facilitate automatic discovery of divergent subgroups in tabular data
Paper and Code
Mar 08, 2022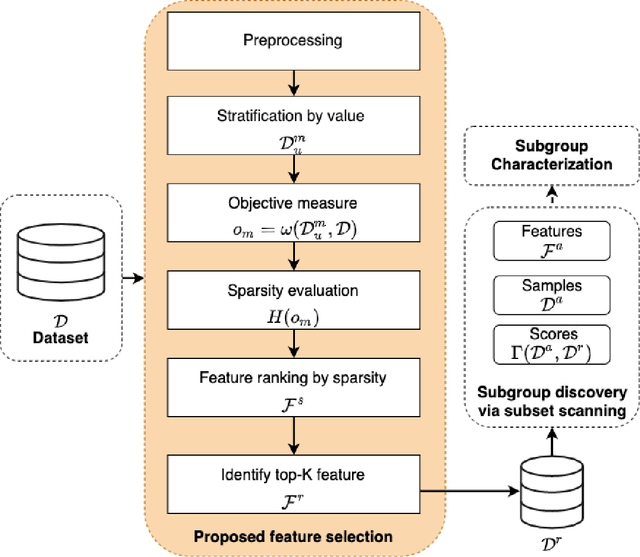
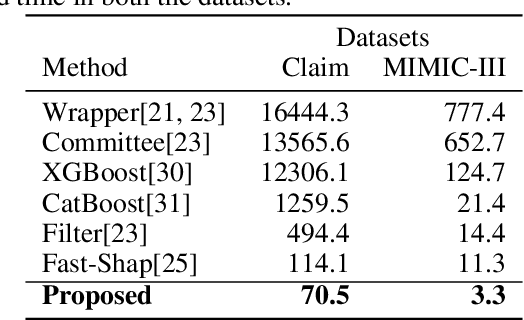
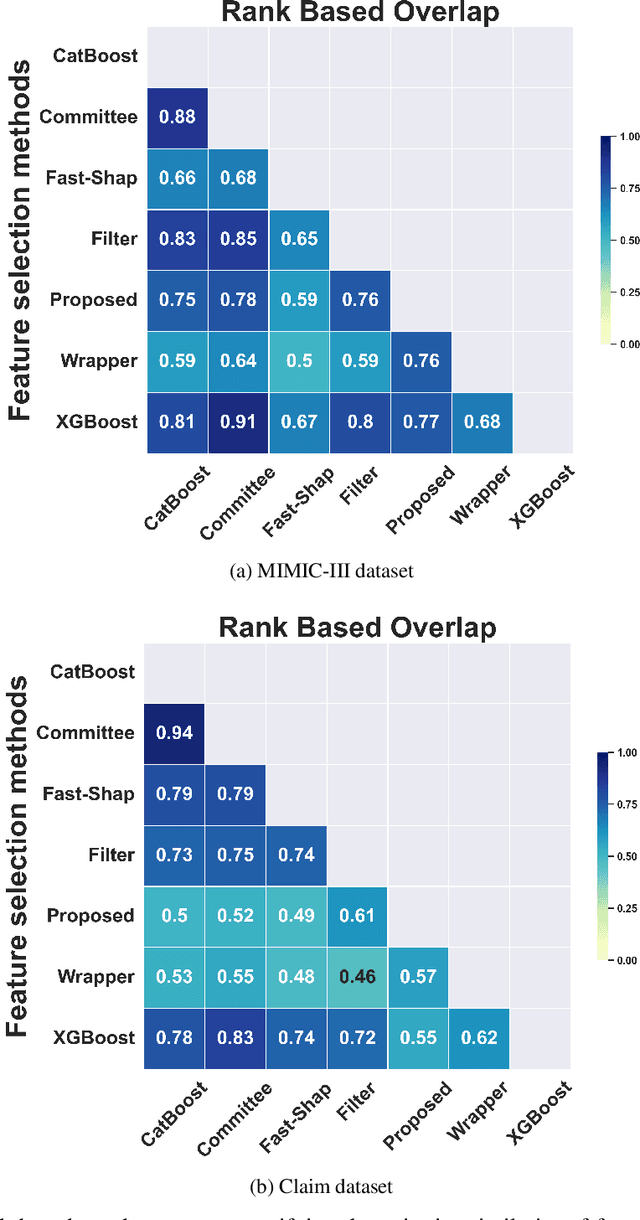
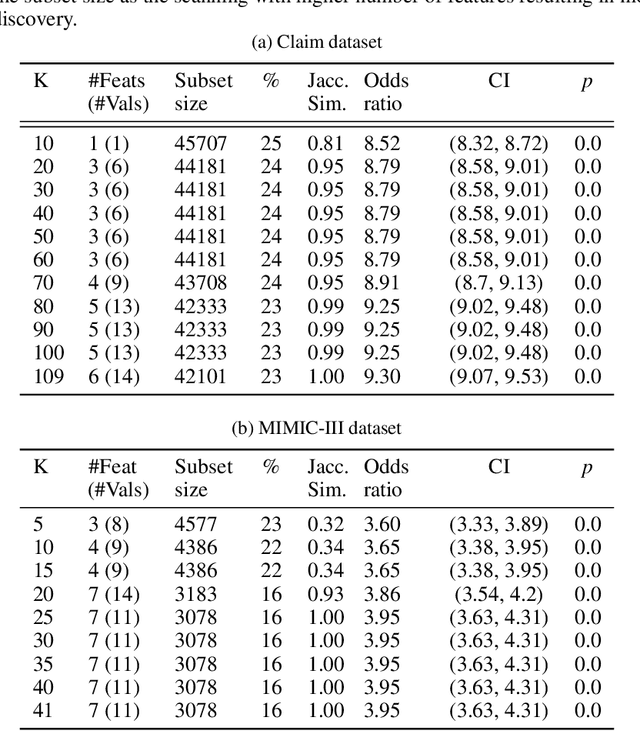
Data-centric AI encourages the need of cleaning and understanding of data in order to achieve trustworthy AI. Existing technologies, such as AutoML, make it easier to design and train models automatically, but there is a lack of a similar level of capabilities to extract data-centric insights. Manual stratification of tabular data per a feature (e.g., gender) is limited to scale up for higher feature dimension, which could be addressed using automatic discovery of divergent subgroups. Nonetheless, these automatic discovery techniques often search across potentially exponential combinations of features that could be simplified using a preceding feature selection step. Existing feature selection techniques for tabular data often involve fitting a particular model in order to select important features. However, such model-based selection is prone to model-bias and spurious correlations in addition to requiring extra resource to design, fine-tune and train a model. In this paper, we propose a model-free and sparsity-based automatic feature selection (SAFS) framework to facilitate automatic discovery of divergent subgroups. Different from filter-based selection techniques, we exploit the sparsity of objective measures among feature values to rank and select features. We validated SAFS across two publicly available datasets (MIMIC-III and Allstate Claims) and compared it with six existing feature selection methods. SAFS achieves a reduction of feature selection time by a factor of 81x and 104x, averaged cross the existing methods in the MIMIC-III and Claims datasets respectively. SAFS-selected features are also shown to achieve competitive detection performance, e.g., 18.3% of features selected by SAFS in the Claims dataset detected divergent samples similar to those detected by using the whole features with a Jaccard similarity of 0.95 but with a 16x reduction in detection time.