 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Hospitalization Forecasting Evaluations for Decision Support using LLMs
Apr 27, 2026Medical and public health experts must make real-time resource decisions, such as expanding hospital bed capacity, based on projected hospitalization trends during large-scale healthcare disruptions (e.g., operational failures or pandemics). Forecasting models can assist in this task by analyzing large volumes of resource-related data at the facility level, but they must be reliable for decision-making under real-world data conditions. Recent work shows that large language models (LLMs) can incorporate richer forms of context into numerical forecasting. Whereas traditional models rely primarily on temporal context (i.e., past observations), LLMs can also leverage non-temporal public health context such as demographic, geographic, and population-level features. However, it remains unclear how these models should be used to produce stable or decision-relevant predictions in real-world healthcare settings. To evaluate how LLMs can be effectively used in this setting, we evaluate three approaches across 60 counties with low-,mid-, and high-hospitalization intensities in the United States: direct LLM-based forecasting, classical time-series models, and a context-augmented hybrid pipeline (HybridARX) that incorporates LLM-derived signals into structured models. Because the goal is operational decision-making rather than error minimization alone, we evaluate performance with bias and lead-lag alignment in addition to standard forecasting metrics. Our results show that HybridARX improves over classical ARX by yielding more stable and better-calibrated forecasts, particularly when incorporating noisy contextual signals into structured time-series models. These findings suggest that, in non-stationary healthcare resource forecasting, LLMs are most useful when embedded within structured hybrid models.
Reliable Self-Harm Risk Screening via Adaptive Multi-Agent LLM Systems
Apr 24, 2026Emerging AI systems in behavioral health and psychiatry use multi-step or multi-agent LLM pipelines for tasks like assessing self-harm risk and screening for depression. However, common evaluation approaches, like LLM-as-a-judge, do not indicate when a decision is reliable or how errors may accumulate across multiple LLM judgements, limiting their suitability for safety-critical settings. We present a statistical framework for multi-agent pipelines structured as directed acyclic graphs (DAGs) that provides an alternative to heuristic voting with principled, adaptive decision-making. We model each agent as a stochastic categorical decision and introduce (1) tighter agent-level performance confidence bounds, (2) a bandit-based adaptive sampling strategy based on input difficulty, and (3) regret guarantees over the multi-agent system that shows logarithmic error growth when deployed. We evaluate our system on two labeled datasets in behavioral health : the AEGIS 2.0 behavioral health subset (N=161) and a stratified sample of SWMH Reddit posts (N=250). Empirically, our adaptive sampling strategy achieves the lowest false positive rate of any condition across both datasets, 0.095 on AEGIS 2.0 compared to 0.159 for single-agent models, reducing incorrect flagging of safe content by 40\% and still having similar false negative rates across all conditions. These results suggest that principled adaptive sampling offers a meaningful improvement in precision without reducing recall in this setting.
Constrained Process Maps for Multi-Agent Generative AI Workflows
Feb 02, 2026Large language model (LLM)-based agents are increasingly used to perform complex, multi-step workflows in regulated settings such as compliance and due diligence. However, many agentic architectures rely primarily on prompt engineering of a single agent, making it difficult to observe or compare how models handle uncertainty and coordination across interconnected decision stages and with human oversight. We introduce a multi-agent system formalized as a finite-horizon Markov Decision Process (MDP) with a directed acyclic structure. Each agent corresponds to a specific role or decision stage (e.g., content, business, or legal review in a compliance workflow), with predefined transitions representing task escalation or completion. Epistemic uncertainty is quantified at the agent level using Monte Carlo estimation, while system-level uncertainty is captured by the MDP's termination in either an automated labeled state or a human-review state. We illustrate the approach through a case study in AI safety evaluation for self-harm detection, implemented as a multi-agent compliance system. Results demonstrate improvements over a single-agent baseline, including up to a 19\% increase in accuracy, up to an 85x reduction in required human review, and, in some configurations, reduced processing time.
Predicting Language Models' Success at Zero-Shot Probabilistic Prediction
Sep 18, 2025Recent work has investigated the capabilities of large language models (LLMs) as zero-shot models for generating individual-level characteristics (e.g., to serve as risk models or augment survey datasets). However, when should a user have confidence that an LLM will provide high-quality predictions for their particular task? To address this question, we conduct a large-scale empirical study of LLMs' zero-shot predictive capabilities across a wide range of tabular prediction tasks. We find that LLMs' performance is highly variable, both on tasks within the same dataset and across different datasets. However, when the LLM performs well on the base prediction task, its predicted probabilities become a stronger signal for individual-level accuracy. Then, we construct metrics to predict LLMs' performance at the task level, aiming to distinguish between tasks where LLMs may perform well and where they are likely unsuitable. We find that some of these metrics, each of which are assessed without labeled data, yield strong signals of LLMs' predictive performance on new tasks.
L3Cube-MahaSTS: A Marathi Sentence Similarity Dataset and Models
Aug 29, 2025



We present MahaSTS, a human-annotated Sentence Textual Similarity (STS) dataset for Marathi, along with MahaSBERT-STS-v2, a fine-tuned Sentence-BERT model optimized for regression-based similarity scoring. The MahaSTS dataset consists of 16,860 Marathi sentence pairs labeled with continuous similarity scores in the range of 0-5. To ensure balanced supervision, the dataset is uniformly distributed across six score-based buckets spanning the full 0-5 range, thus reducing label bias and enhancing model stability. We fine-tune the MahaSBERT model on this dataset and benchmark its performance against other alternatives like MahaBERT, MuRIL, IndicBERT, and IndicSBERT. Our experiments demonstrate that MahaSTS enables effective training for sentence similarity tasks in Marathi, highlighting the impact of human-curated annotations, targeted fine-tuning, and structured supervision in low-resource settings. The dataset and model are publicly shared at https://github.com/l3cube-pune/MarathiNLP
MahaParaphrase: A Marathi Paraphrase Detection Corpus and BERT-based Models
Aug 24, 2025



Paraphrases are a vital tool to assist language understanding tasks such as question answering, style transfer, semantic parsing, and data augmentation tasks. Indic languages are complex in natural language processing (NLP) due to their rich morphological and syntactic variations, diverse scripts, and limited availability of annotated data. In this work, we present the L3Cube-MahaParaphrase Dataset, a high-quality paraphrase corpus for Marathi, a low resource Indic language, consisting of 8,000 sentence pairs, each annotated by human experts as either Paraphrase (P) or Non-paraphrase (NP). We also present the results of standard transformer-based BERT models on these datasets. The dataset and model are publicly shared at https://github.com/l3cube-pune/MarathiNLP
Enabling Precise Topic Alignment in Large Language Models Via Sparse Autoencoders
Jun 14, 2025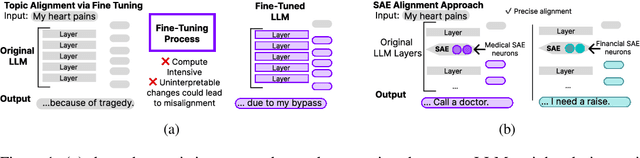



Recent work shows that Sparse Autoencoders (SAE) applied to large language model (LLM) layers have neurons corresponding to interpretable concepts. These SAE neurons can be modified to align generated outputs, but only towards pre-identified topics and with some parameter tuning. Our approach leverages the observational and modification properties of SAEs to enable alignment for any topic. This method 1) scores each SAE neuron by its semantic similarity to an alignment text and uses them to 2) modify SAE-layer-level outputs by emphasizing topic-aligned neurons. We assess the alignment capabilities of this approach on diverse public topic datasets including Amazon reviews, Medicine, and Sycophancy, across the currently available open-source LLMs and SAE pairs (GPT2 and Gemma) with multiple SAEs configurations. Experiments aligning to medical prompts reveal several benefits over fine-tuning, including increased average language acceptability (0.25 vs. 0.5), reduced training time across multiple alignment topics (333.6s vs. 62s), and acceptable inference time for many applications (+0.00092s/token). Our open-source code is available at github.com/IBM/sae-steering.
An AI-Based Public Health Data Monitoring System
Jun 04, 2025Public health experts need scalable approaches to monitor large volumes of health data (e.g., cases, hospitalizations, deaths) for outbreaks or data quality issues. Traditional alert-based monitoring systems struggle with modern public health data monitoring systems for several reasons, including that alerting thresholds need to be constantly reset and the data volumes may cause application lag. Instead, we propose a ranking-based monitoring paradigm that leverages new AI anomaly detection methods. Through a multi-year interdisciplinary collaboration, the resulting system has been deployed at a national organization to monitor up to 5,000,000 data points daily. A three-month longitudinal deployed evaluation revealed a significant improvement in monitoring objectives, with a 54x increase in reviewer speed efficiency compared to traditional alert-based methods. This work highlights the potential of human-centered AI to transform public health decision-making.
Universal Cross-Lingual Text Classification
Jun 16, 2024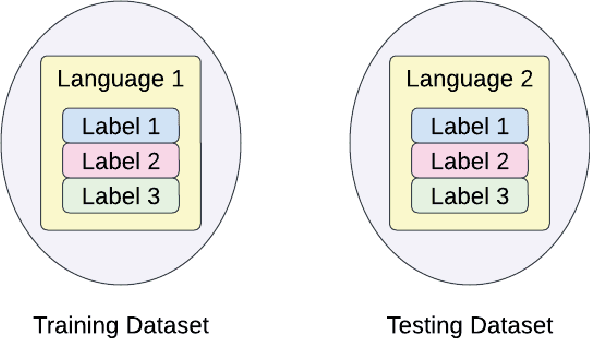


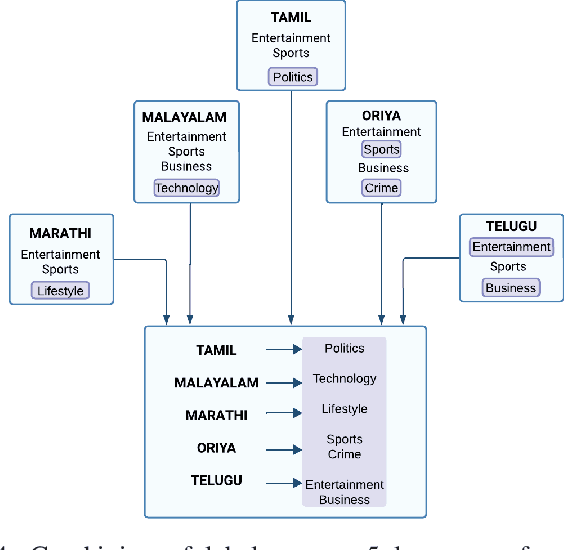
Text classification, an integral task in natural language processing, involves the automatic categorization of text into predefined classes. Creating supervised labeled datasets for low-resource languages poses a considerable challenge. Unlocking the language potential of low-resource languages requires robust datasets with supervised labels. However, such datasets are scarce, and the label space is often limited. In our pursuit to address this gap, we aim to optimize existing labels/datasets in different languages. This research proposes a novel perspective on Universal Cross-Lingual Text Classification, leveraging a unified model across languages. Our approach involves blending supervised data from different languages during training to create a universal model. The supervised data for a target classification task might come from different languages covering different labels. The primary goal is to enhance label and language coverage, aiming for a label set that represents a union of labels from various languages. We propose the usage of a strong multilingual SBERT as our base model, making our novel training strategy feasible. This strategy contributes to the adaptability and effectiveness of the model in cross-lingual language transfer scenarios, where it can categorize text in languages not encountered during training. Thus, the paper delves into the intricacies of cross-lingual text classification, with a particular focus on its application for low-resource languages, exploring methodologies and implications for the development of a robust and adaptable universal cross-lingual model.
Outlier Ranking in Large-Scale Public Health Streams
Jan 02, 2024Disease control experts inspect public health data streams daily for outliers worth investigating, like those corresponding to data quality issues or disease outbreaks. However, they can only examine a few of the thousands of maximally-tied outliers returned by univariate outlier detection methods applied to large-scale public health data streams. To help experts distinguish the most important outliers from these thousands of tied outliers, we propose a new task for algorithms to rank the outputs of any univariate method applied to each of many streams. Our novel algorithm for this task, which leverages hierarchical networks and extreme value analysis, performed the best across traditional outlier detection metrics in a human-expert evaluation using public health data streams. Most importantly, experts have used our open-source Python implementation since April 2023 and report identifying outliers worth investigating 9.1x faster than their prior baseline. Other organizations can readily adapt this implementation to create rankings from the outputs of their tailored univariate methods across large-scale streams.