 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building Efficient Sentence BERT Models using Layer Pruning
Sep 21, 2024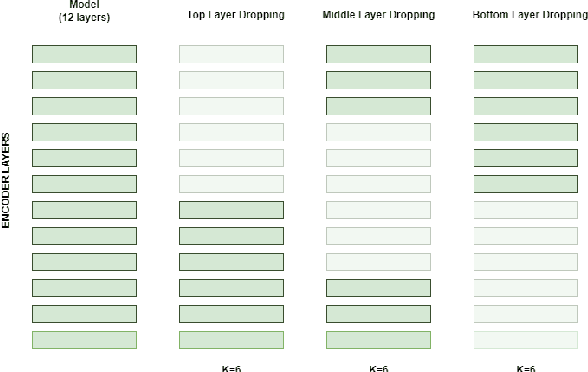
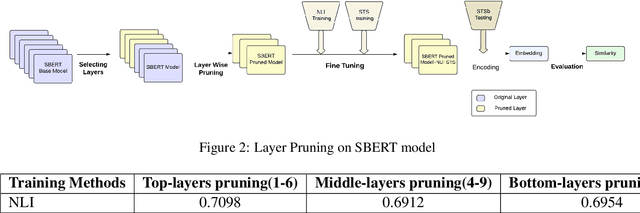

This study examines the effectiveness of layer pruning in creating efficient Sentence BERT (SBERT) models. Our goal is to create smaller sentence embedding models that reduce complexity while maintaining strong embedding similarity. We assess BERT models like Muril and MahaBERT-v2 before and after pruning, comparing them with smaller, scratch-trained models like MahaBERT-Small and MahaBERT-Smaller. Through a two-phase SBERT fine-tuning process involving Natural Language Inference (NLI) and Semantic Textual Similarity (STS), we evaluate the impact of layer reduction on embedding quality. Our findings show that pruned models, despite fewer layers, perform competitively with fully layered versions. Moreover, pruned models consistently outperform similarly sized, scratch-trained models, establishing layer pruning as an effective strategy for creating smaller, efficient embedding models. These results highlight layer pruning as a practical approach for reducing computational demand while preserving high-quality embeddings, making SBERT models more accessible for languages with limited technological resources.
Universal Cross-Lingual Text Classification
Jun 16, 2024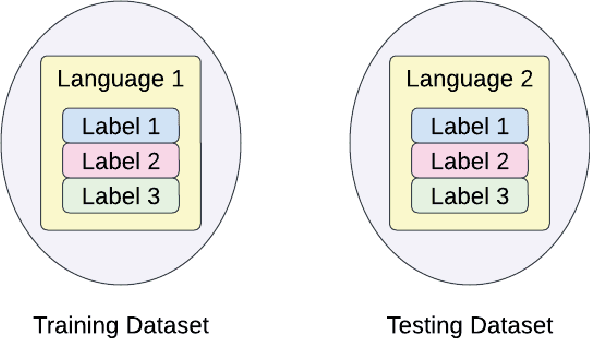


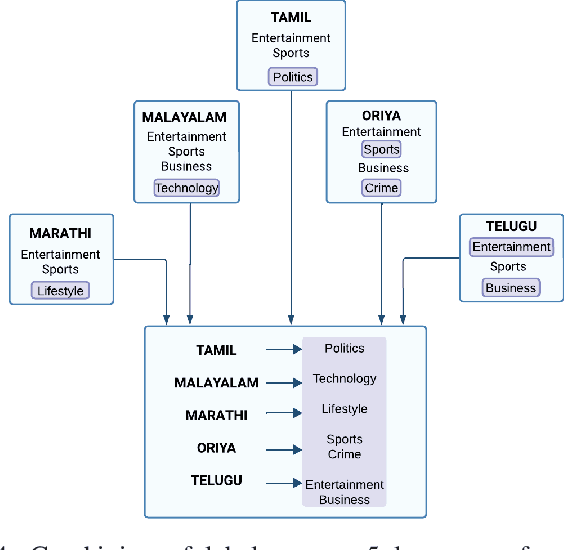
Text classification, an integral task in natural language processing, involves the automatic categorization of text into predefined classes. Creating supervised labeled datasets for low-resource languages poses a considerable challenge. Unlocking the language potential of low-resource languages requires robust datasets with supervised labels. However, such datasets are scarce, and the label space is often limited. In our pursuit to address this gap, we aim to optimize existing labels/datasets in different languages. This research proposes a novel perspective on Universal Cross-Lingual Text Classification, leveraging a unified model across languages. Our approach involves blending supervised data from different languages during training to create a universal model. The supervised data for a target classification task might come from different languages covering different labels. The primary goal is to enhance label and language coverage, aiming for a label set that represents a union of labels from various languages. We propose the usage of a strong multilingual SBERT as our base model, making our novel training strategy feasible. This strategy contributes to the adaptability and effectiveness of the model in cross-lingual language transfer scenarios, where it can categorize text in languages not encountered during training. Thus, the paper delves into the intricacies of cross-lingual text classification, with a particular focus on its application for low-resource languages, exploring methodologies and implications for the development of a robust and adaptable universal cross-lingual model.