 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building Efficient Sentence BERT Models using Layer Pruning
Paper and Code
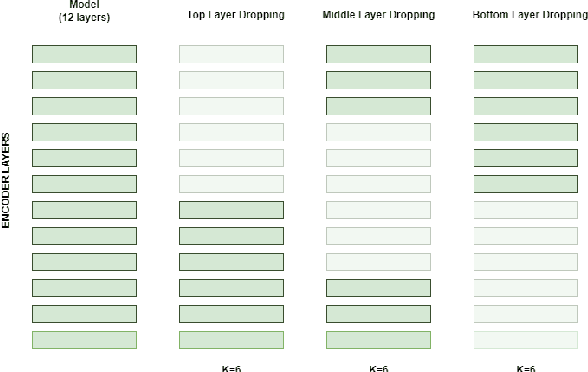
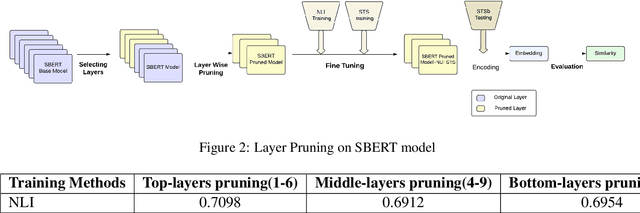

This study examines the effectiveness of layer pruning in creating efficient Sentence BERT (SBERT) models. Our goal is to create smaller sentence embedding models that reduce complexity while maintaining strong embedding similarity. We assess BERT models like Muril and MahaBERT-v2 before and after pruning, comparing them with smaller, scratch-trained models like MahaBERT-Small and MahaBERT-Smaller. Through a two-phase SBERT fine-tuning process involving Natural Language Inference (NLI) and Semantic Textual Similarity (STS), we evaluate the impact of layer reduction on embedding quality. Our findings show that pruned models, despite fewer layers, perform competitively with fully layered versions. Moreover, pruned models consistently outperform similarly sized, scratch-trained models, establishing layer pruning as an effective strategy for creating smaller, efficient embedding models. These results highlight layer pruning as a practical approach for reducing computational demand while preserving high-quality embeddings, making SBERT models more accessible for languages with limited technological resources.