 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Relational Encoding in Language Model: Pre-Training for General Sequences
Paper and Code
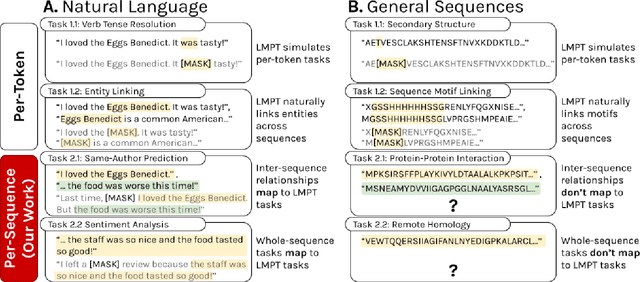
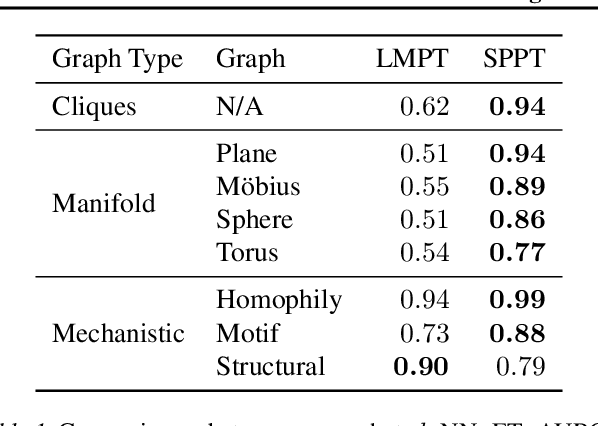
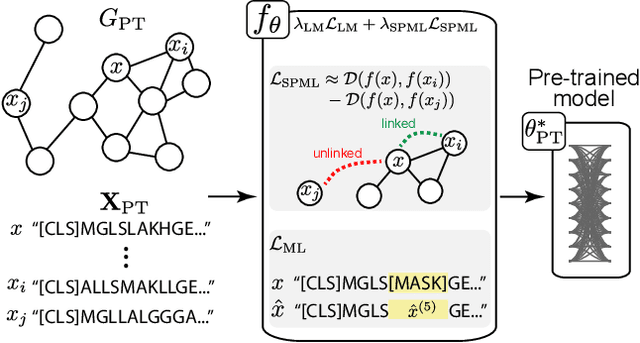
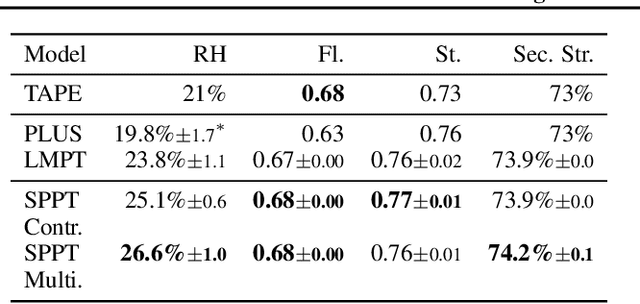
Language model pre-training (LMPT) has achieved remarkable results in natural language understanding. However, LMPT is much less successful in non-natural language domains like protein sequences, revealing a crucial discrepancy between the various sequential domains. Here, we posit that while LMPT can effectively model per-token relations, it fails at modeling per-sequence relations in non-natural language domains. To this end, we develop a framework that couples LMPT with deep structure-preserving metric learning to produce richer embeddings than can be obtained from LMPT alone. We examine new and existing pre-training models in this framework and theoretically analyze the framework overall. We also design experiments on a variety of synthetic datasets and new graph-augmented datasets of proteins and scientific abstracts. Our approach offers notable performance improvements on downstream tasks, including prediction of protein remote homology and classification of citation intent.