 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats
Paper and Code
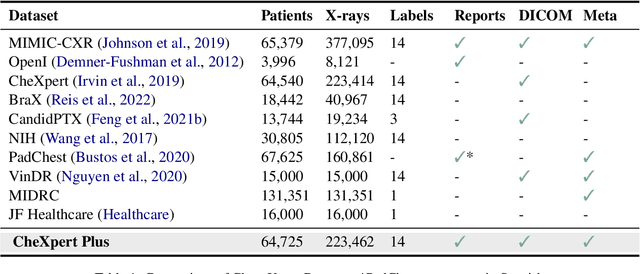

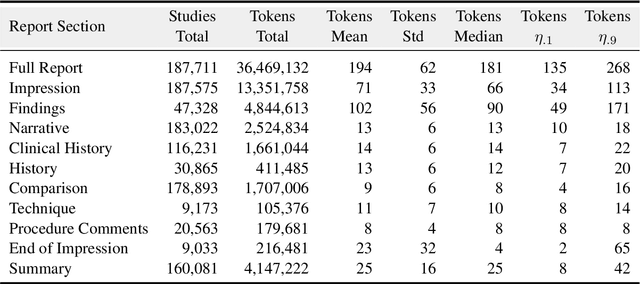
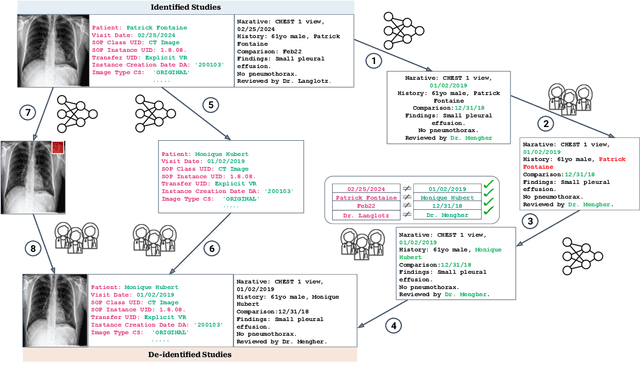
Since the release of the original CheXpert paper five years ago, CheXpert has become one of the most widely used and cited clinical AI datasets. The emergence of vision language models has sparked an increase in demands for sharing reports linked to CheXpert images, along with a growing interest among AI fairness researchers in obtaining demographic data. To address this, CheXpert Plus serves as a new collection of radiology data sources, made publicly available to enhance the scaling, performance, robustness, and fairness of models for all subsequent machine learning tasks in the field of radiology. CheXpert Plus is the largest text dataset publicly released in radiology, with a total of 36 million text tokens, including 13 million impression tokens. To the best of our knowledge, it represents the largest text de-identification effort in radiology, with almost 1 million PHI spans anonymized. It is only the second time that a large-scale English paired dataset has been released in radiology, thereby enabling, for the first time, cross-institution training at scale. All reports are paired with high-quality images in DICOM format, along with numerous image and patient metadata covering various clinical and socio-economic groups, as well as many pathology labels and RadGraph annotations. We hope this dataset will boost research for AI models that can further assist radiologists and help improve medical care. Data is available at the following URL: https://stanfordaimi.azurewebsites.net/datasets/5158c524-d3ab-4e02-96e9-6ee9efc110a1 Models are available at the following URL: https://github.com/Stanford-AIMI/chexpert-plus