 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.
Exploring the Versatility of Zero-Shot CLIP for Interstitial Lung Disease Classification
Jun 01, 2023



Interstitial lung diseases (ILD) present diagnostic challenges due to their varied manifestations and overlapping imaging features. To address this, we propose a machine learning approach that utilizes CLIP, a multimodal (image and text) self-supervised model, for ILD classification. We extensively integrate zero-shot CLIP throughout our workflow, starting from the initial extraction of image patches from volumetric CT scans and proceeding to ILD classification using "patch montages". Furthermore, we investigate how domain adaptive pretraining (DAPT) CLIP with task-specific images (CT "patch montages" extracted with ILD-specific prompts for CLIP) and/or text (lung-specific sections of radiology reports) affects downstream ILD classification performance. By leveraging CLIP-extracted "patch montages" and DAPT, we achieve strong zero-shot ILD classification results, including an AUROC of 0.893, without the need for any labeled training data. This work highlights the versatility and potential of multimodal models like CLIP for medical image classification tasks where labeled data is scarce.
How to Train Your CheXDragon: Training Chest X-Ray Models for Transfer to Novel Tasks and Healthcare Systems
May 13, 2023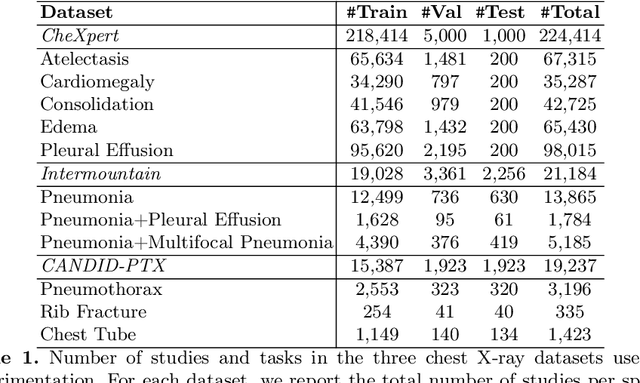
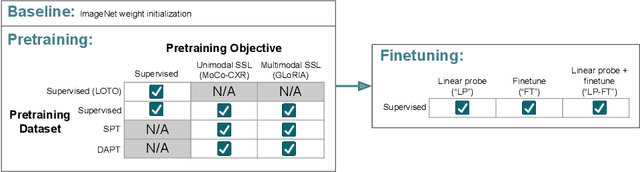
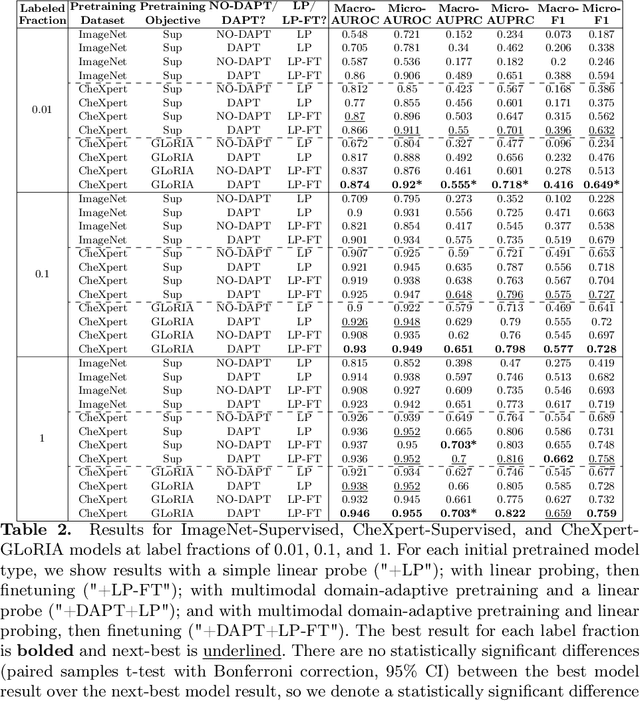
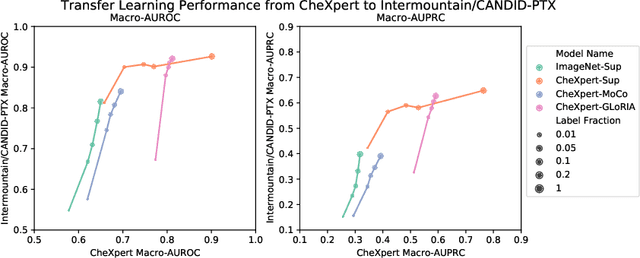
Self-supervised learning (SSL) enables label efficient training for machine learning models. This is essential for domains such as medical imaging, where labels are costly and time-consuming to curate. However, the most effective supervised or SSL strategy for transferring models to different healthcare systems or novel tasks is not well understood. In this work, we systematically experiment with a variety of supervised and self-supervised pretraining strategies using multimodal datasets of medical images (chest X-rays) and text (radiology reports). We then evaluate their performance on data from two external institutions with diverse sets of tasks. In addition, we experiment with different transfer learning strategies to effectively adapt these pretrained models to new tasks and healthcare systems. Our empirical results suggest that multimodal SSL gives substantial gains over unimodal SSL in performance across new healthcare systems and tasks, comparable to models pretrained with full supervision. We demonstrate additional performance gains with models further adapted to the new dataset and task, using multimodal domain-adaptive pretraining (DAPT), linear probing then finetuning (LP-FT), and both methods combined. We offer suggestions for alternative models to use in scenarios where not all of these additions are feasible. Our results provide guidance for improving the generalization of medical image interpretation models to new healthcare systems and novel tasks.
RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
May 02, 2023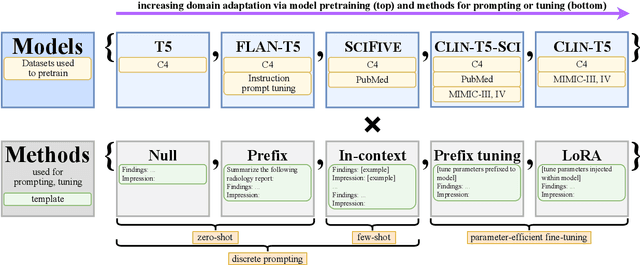
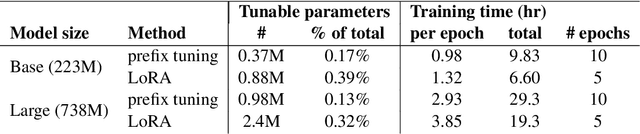
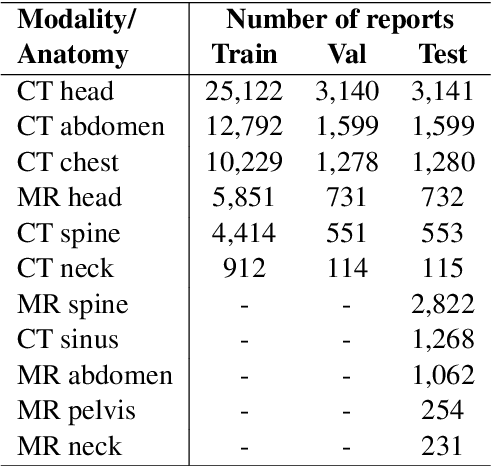

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.